Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
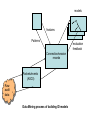
A Framework for Constructing Features and Models for Intrusion Detection Systems Authors: Wenke Lee & Salvatore J.Stolfo Published in ACM Transactions on Information and System Security, Volume 3, Number 4, 2000. Presented By Suchandra Goswami Contributions of this work • Development of automated Intrusion Detection Systems (IDSs) rather than pure knowledge encoding and engineering approaches • Provides a novel framework called MADAM ID, for Mining Audit Data for Automated Models for Intrusion Detection • First work applying data mining and machine learning algorithms for IDSs Introduction • Intrusion Detection (ID) is the art of detecting inappropriate, incorrect, or anomalous activity. • ID systems that operate on a host to detect malicious activity on that host are called hostbased ID systems • ID systems that operate on network data flows are called network-based ID systems. • statistical anomaly detection and patternmatching most commonly used for ID • Two main ID techniques: misuse detection and anomaly detection • Misuse detection – Use patterns of well-known attacks or weak spots of the system to match and identify known intrusions • E.g, signature rule for “guessing password attack” will be “there are more than 4 failed login attempts within 2 minutes” • Anomaly detection – Flag observed activities that deviate significantly from the established normal usage profiles. • This research takes a data centric point of view and ID is considered to be a data analysis process • Data mining programs used to compute models that accurately capture actual behavior (patterns) • Eliminates the need to manually analyze and encode intrusion patterns • Validated with large amounts of audit data Some Data Mining techniques and its application to IDSs • Classification – maps data items into one of several pre-defined categories. Algorithms generally output classifiers like decision trees or rules. • E.g, gather sufficient “normal” and “abnormal” audit data. Apply classification algorithm to learn a classifier that can label unseen audit data normal or abnormal • Link Analysis – determines relation/correlation between fields in the database records. E.g, “emacs” may be highly associated with “C” files • Sequence analysis – models sequential patterns. Algorithms discover what time based sequence of audit events are frequently occurring together. • Frequent event patterns provide guidelines for incorporating temporal statistical measures into intrusion detection models • E.g, patterns from audit data containing network based DoS attacks suggest that several per-host and per-service measures should be included models features Patterns evaluation feedback Connection/session records Packets/events (ASCII) Raw audit data Data Mining process of building ID models Data Mining techniques used in MADAM ID • Audit data consist of pre-processed timestamped audit records with a number of features/fields • ID is considered to be a classification problem • Given a set of records, where one of the features is a class label, classification algorithms compute a model that uses the most discriminating feature values to describe a concept Telnet Records label service flag hot Failed_logins compromised Root_ shell su duration …. normal telnet SF 0 0 0 0 0 10.2 … normal telnet SF 0 0 0 3 1 2.1 … guess telnet SF 0 6 0 0 0 26.2 … normal telnet SF 0 0 0 0 0 126.2 … overflow telnet SF 3 0 2 1 0 92.5 … normal telnet SF 0 0 0 0 0 2.1 … guess telnet SF 0 5 0 0 0 13.9 … overflow telnet SF 3 0 2 1 0 92.5 … normal telnet SF 0 0 0 0 0 1248 … … …. … … … … … … … … Rule Learning • RIPPER is a classification rule learning program that generate rules • Accuracy of classification model depends on the set of features provided in the training set • Classification algorithm looks for features with large information gain • Adding per-host and perservice temporal service reulted in significant improvement in accuracy RIPPER RULE Meaning Guess :- failed_logins ≥ 4 If number of failed logins is at least 4, then this telnet connection is “guess”, a guessing password attack Overflow :- hot ≥ 3, compromised ≥ 2, root_shell = 1 If the number of hot indicators is at least 3, the number of compromised conditions is at least 2, and a root shell is obtained, then this telnet connection is a buffer overflow attack ….. ….. Normal :- true If none of the above, then this connection is “normal” Meta-classification • Meta-learning is a mechanism for inductively learning the correlation of predictions made by a number of base classifiers • Each record in training data has the true class label and the predictions made by the base classifiers • Meta-classifier combines the base models to make a final prediction • IDS should consist of multiple cooperative lightweight subsystems that monitors separate parts of the network environment Association Rules • Program executions and user activities exhibit frequent correlations among system features • Goal of mining association rules - derive multifeature correlations from database table • Support(X) - % of records that contain item set X where each record is a set of items • Association rule – an expression of the form X → Y, [c,s] where X and Y are itemsets, X ∩ Y = Φ, s = support(X U Y) c = support(X U Y) / support(X) is the confidence time hostname command arg1 arg2 am pascal mkdir dir1 … am pascal cd dir1 … am pascal vi text … am pascal tex vi … am pascal subject progress … am pascal vi text … am pascal vi text … am pascal subject progress … am pascal vi text … vi → time = am, hostname = pascal, arg1 = text, [1.0, 44.4] Support(vi) = 44.4% When using vi to edit a file, the user is always (i.e, 100% of the time) editing a text file, in the morning, and at host pascal; and 44.4% of the command data matches this pattern Frequent Episodes • A frequent episode rule is the expression X,Y → Z,[c,s,w] where w is the width of the time interval [t1 , t2 ] during which the episode occurs • Mined frequent episodes from audit data contain association among features used to construct temporal statistical features for building classifiers Network Connection Records timestamp duration service Src_host Dst_host Src_ bytes Dst_ bytes flag 1.1 0 http Spoofed_1 victim 0 0 S0 1.1 0 http Spoofed_2 Victim 0 0 S0 1.1 0 http Spoofed_3 Victim 0 0 S0 1.1 0 http Spoofed_4 Victim 0 0 S0 1.1 0 http Spoofed_5 Victim 0 0 S0 1.1 0 http Spoofed_6 Victim 0 0 S0 1.1 0 http Spoofed_7 Victim 0 0 S0 ……. ……. ….. ….. …….. ……. ….. ….. 10.1 2 ftp A B 200 300 SF Flag = S0, service = http, dst_host =‘victim’ used to describe the SYN flood attack Victim → service = ‘http’, src_byte = 0, dst_byte = 0, flag = ‘S0’ [1.0, 0.7, 0] Constructing features from intrusion patterns • Parse frequent episodes and use three operators, count, percent, and average to construct statistical features Procedure – E.g, assume F0 say dst_host is a reference feature and the width of the episode is w seconds – Add the following features that examine only the connections in the past w seconds that share the same value in dst_host as the current connection – Add a feature that computes “ the count of these connections” – Let F1 be service, src_host or dst_host other than F0. If the same value of F1 is in all item sets of the episode, add a feature that computes “% of connections having same F1 value as the current connection” – Let V2 be a value (e.g, S0) of a feature F2 (say flag). If V2 is in all the itemsets of the episode, add a feature that computes “% of connections having same V2”; otherwise if F2 is a numerical feature, add a feature that “computes the average of F2 values”. Example to illustrate feature construction • Suppose record 7 in slide 17 is our current connection ( F0 value = ‘victim’, F1 value = ‘http’) Assume w = 0, F0 is the feature ‘dst_host’ • Count number of connections in the past w = 0 time units having the same value for feature F0 i.e, dst_host = ‘victim’ ( = 7 for this e.g) • Create a new feature count_F0 (containing value 7 in this e.g) • Assume F1 is the feature ‘service’ • Compute the % of connections having service = ‘http’ in the past w = 0 time units for a given F0 i.e, dst_host = ‘victim’ ( = 100% for this e.g) • Create a new feature pcnt_F1_F0 (containing value 100 in this e.g) • Assume V2 = S0 • Compute the % of connections having V2 = ‘S0’ in the past w = 0 time units for a given F0 i.e, dst_host = ‘victim’ • Create a new feature pcnt_V2_F0 (containing value 100 in this e.g) Experimentation • Experiments were conducted on 1998 DARPA Intrusion Detection Evaluation Program data and DARPA BSM data • Algorithms and tools of MADAM ID were used to process audit data, mine patterns, construct features and build RIPPER classifiers • DARPA data – 4 gigabytes of compressed tcpdump data of 7 weeks of network traffic • Data was processed into 5 million connection records of about 100 bytes each • DoS, R2L, U2R, PROBING attacks in training data Model # of features in records # of rules # of features used in rules 22 55 11 traffic 20 26 4+9 Host traffic 14 8 1+5 Model Complexities content User Anomaly Detection • Goal is to determine whether the behavior of a user is normal or not • Difficult to classify a single event by a user as normal or abnormal • A user’s actions during a login session needs to be studied as a whole to determine whether he/she is behaving normally • Approach - Mine the frequent patterns from command data - Form the normal usage profile of the user - Analyze a login session by comparing its similarity to the profile User Descriptions User Anomaly Description Strengths • Paper very well written • Exhaustive experimentation with real world data • Developed a simple, intuitive yet powerful method for feature construction • First attempt to incorporate data mining algorithms in IDS • Experimented with both misuse detection and user anomaly detection • Models performed better than the systems built with knowledge engineering approaches • Critique their own work Weaknesses • Results show that the tools are not effective for attacks having large variance in behavior (like DoS and R2L) • Results depend on quality and quantity of training data – may lead to overtraining • Network anomaly detection not implemented to detect new attacks • Computationally expensive Future Improvements • Develop algorithms to learn network anomaly detection models • ID models should be sensitive to cost factors like development cost, operational cost, i.e, needed resources, cost of damages of an intrusion, cost of detecting and responding to potential intrusion • Algorithms should incorporate user-defined factors and policies to compute cost-sensitive ID models