Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Matrix completion wikipedia , lookup
Capelli's identity wikipedia , lookup
Linear least squares (mathematics) wikipedia , lookup
Rotation matrix wikipedia , lookup
Eigenvalues and eigenvectors wikipedia , lookup
Determinant wikipedia , lookup
System of linear equations wikipedia , lookup
Jordan normal form wikipedia , lookup
Matrix (mathematics) wikipedia , lookup
Four-vector wikipedia , lookup
Principal component analysis wikipedia , lookup
Perron–Frobenius theorem wikipedia , lookup
Singular-value decomposition wikipedia , lookup
Non-negative matrix factorization wikipedia , lookup
Orthogonal matrix wikipedia , lookup
Cayley–Hamilton theorem wikipedia , lookup
Gaussian elimination wikipedia , lookup
Matrix calculus wikipedia , lookup
Sketching as a Tool for Numerical
Linear Algebra
All Lectures
David Woodruff
IBM Almaden
Massive data sets
Examples
Internet traffic logs
Financial data
etc.
Algorithms
Want nearly linear time or less
Usually at the cost of a randomized approximation
2
Regression analysis
Regression
Statistical method to study dependencies between
variables in the presence of noise.
3
Regression analysis
Linear Regression
Statistical method to study linear dependencies
between variables in the presence of noise.
4
Regression analysis
Linear Regression
Statistical method to study linear dependencies
between variables in the presence of noise.
Example Regression
Example
Ohm's law V = R ∙ I
250
200
150
Example Regression
100
50
0
0
50
100
150
5
Regression analysis
Linear Regression
Statistical method to study linear dependencies
between variables in the presence of noise.
Example Regression
Example
Ohm's law V = R ∙ I
Find linear function that
best fits the data
250
200
150
Example Regression
100
50
0
0
50
100
150
6
Regression analysis
Linear Regression
Statistical method to study linear dependencies between
variables in the presence of noise.
Standard Setting
One measured variable b
A set of predictor variables a1 ,…, a d
Assumption:
b = x0 + a 1 x1 + … + a d xd + e
e is assumed to be noise and the xi are model
parameters we want to learn
Can assume x0 = 0
Now consider n observations of b
7
Regression analysis
Matrix form
Input: nd-matrix A and a vector b=(b1,…, bn)
n is the number of observations; d is the number of
predictor variables
Output: x* so that Ax* and b are close
Consider the over-constrained case, when n À d
Can assume that A has full column rank
8
Regression analysis
Least Squares Method
Find x* that minimizes |Ax-b|22 = S (bi – <Ai*, x>)²
Ai* is i-th row of A
Certain desirable statistical properties
9
Regression analysis
Geometry of regression
We want to find an x that minimizes |Ax-b|2
The product Ax can be written as
A*1x1 + A*2x2 + ... + A*dxd
where A*i is the i-th column of A
This is a linear d-dimensional subspace
The problem is equivalent to computing the point of the
column space of A nearest to b in l2-norm
10
Regression analysis
Solving least squares regression via the normal equations
How to find the solution x to minx |Ax-b|2 ?
Equivalent problem: minx |Ax-b |22
Write b = Ax’ + b’, where b’ orthogonal to columns of A
Cost is |A(x-x’)|22 + |b’|22 by Pythagorean theorem
Optimal solution x if and only if AT(Ax-b) = AT(Ax-Ax’) = 0
Normal Equation: ATAx = ATb for any optimal x
x = (ATA)-1 AT b
If the columns of A are not linearly independent, the MoorePenrose pseudoinverse gives a minimum norm solution x
11
Moore-Penrose Pseudoinverse
• Any optimal solution x has the form A− b + I − V′V′T z, where
V’ corresponds to the rows i of V T for which Σ𝑖,𝑖 > 0
•
Why?
•
Because A I − V′V′T z = 0, so A− b + I − V′V′T z is a
solution. This is a d-rank(A) dimensional affine space so it
spans all optimal solutions
•
Since A− b is in column span of V’, by Pythagorean theorem,
|A− b + I − V′V′T z|22 = A− b 22 + |(I − V ′ V ′T )z|22 ≥ A− b 22
12
Time Complexity
Solving least squares regression via the normal equations
Need to compute x = A-b
Naively this takes nd2 time
Can do nd1.376 using fast matrix multiplication
But we want much better running time!
13
Sketching to solve least squares regression
How to find an approximate solution x to minx |Ax-b|2 ?
Goal: output x‘ for which |Ax‘-b|2 · (1+ε) minx |Ax-b|2
with high probability
Draw S from a k x n random family of matrices, for a
value k << n
Compute S*A and S*b
Output the solution x‘ to minx‘ |(SA)x-(Sb)|2
x’ = (SA)-Sb
14
How to choose the right sketching matrix S?
Recall: output the solution x‘ to minx‘ |(SA)x-(Sb)|2
Lots of matrices work
S is d/ε2 x n matrix of i.i.d. Normal random variables
To see why this works, we
introduce the notion of a
subspace embedding
15
Subspace Embeddings
• Let k = O(d/ε2)
• Let S be a k x n matrix of i.i.d. normal
N(0,1/k) random variables
• For any fixed d-dimensional subspace, i.e.,
the column space of an n x d matrix A
– W.h.p., for all x in Rd, |SAx|2 = (1±ε)|Ax|2
• Entire column space of A is preserved
Why is this true?
Subspace Embeddings – A Proof
• Want to show |SAx|2 = (1±ε)|Ax|2 for all x
• Can assume columns of A are orthonormal
(since we prove this for all x)
• Claim: SA is a k x d matrix of i.i.d. N(0,1/k)
random variables
– First property: for two independent random variables X
and Y, with X drawn from N(0,a2 ) and Y drawn from
N(0,b2 ), we have X+Y is drawn from N(0, a2 + b2 )
X+Y is drawn from N(0,
2
𝑎
+
2
𝑏 )
2
• Probability density function 𝑓𝑧 of Z = X+Y𝑏2is
𝑧
𝑥− 2 2
2
𝑎 +𝑏 𝑓 and 𝑓
𝑧
convolution of probability density
𝑋
𝑌
− 2 functions
−
2
−
•
𝑧−𝑥 2
2𝑎2
2 𝑎 +𝑏
𝑥2
− 2
2𝑏
2
Calculation: 𝑒
= 𝑒
𝑓𝑍 𝑧 = ∫ 𝑓𝑌 𝑧 − 𝑥 𝑓𝑋 𝑥 𝑑𝑥
• 𝑓𝑥 𝑥 =
•Density
𝑓𝑍 𝑧
2 /2𝑎 2
1
−𝑥
𝑒
𝑎 2𝜋 .5
, 𝑓𝑦 𝑦 =
2 /2𝑏2
1
−𝑥
𝑒
2𝑧 2
𝑏
.5
𝑏 2𝜋
𝑥− 2 2
𝑎 +𝑏
−
𝑎𝑏 2
2
/2𝑏2 𝑎2 +𝑏2
.5
𝑎2 +𝑏2 2
2 /2𝑎 2
1
1
−(𝑧−𝑥)
−𝑥
of
distribution:
= Gaussian
∫
𝑒
𝑒
∫
2𝜋 .5 𝑎𝑏
𝑎 2𝜋 .5
𝑏 2𝜋 .5
−
=
1
−𝑧 2 /2 𝑎2 +𝑏2
𝑒
2𝜋 .5 𝑎2 +𝑏2 .5
𝑎𝑏 2
𝑎2 +𝑏2
∫
.5
𝑎2 +𝑏2
2𝜋 .5 𝑎𝑏
𝑒
𝑒 𝑑𝑥
2
𝑏2 𝑧
𝑥− 2 2
𝑎 +𝑏
2
𝑎𝑏 2
𝑎2 +𝑏2
dx
dx = 1
Rotational Invariance
• Second property: if u, v are vectors with <u, v> = 0,
then <g,u> and <g,v> are independent, where g is a
vector of i.i.d. N(0,1/k) random variables
• Why?
• If g is an n-dimensional vector of i.i.d. N(0,1)
random variables, and R is a fixed matrix, then
the probability density function of Rg is
𝑥𝑇 RRT
𝑓
𝑥 =
−
1
𝑒
det(RRT ) 2𝜋 𝑑/2
−1
𝑥
2
– RRT is the covariance matrix
– For a rotation matrix R, the distribution of Rg
and of g are the same
Orthogonal Implies Independent
• Want to show: if u, v are vectors with <u, v> = 0, then
<g,u> and <g,v> are independent, where g is a vector of
i.i.d. N(0,1/k) random variables
• Choose a rotation R which sends u to αe1 , and sends v
to βe2
• < g, u > = < gR, RT u > = < h, αe1 > = αh1
• < g, v > = < gR, RT v > = < h, βe2 > = βh2
where h is a vector of i.i.d. N(0, 1/k) random variables
• Then h1 and h2 are independent by definition
Where were we?
• Claim: SA is a k x d matrix of i.i.d. N(0,1/k) random
variables
• Proof: The rows of SA are independent
– Each row is: < g, A1 >, < g, A2 > , … , < g, Ad >
– First property implies the entries in each row are
N(0,1/k) since the columns Ai have unit norm
– Since the columns Ai are orthonormal, the entries in a
row are independent by our second property
Back to Subspace Embeddings
•
•
•
•
Want to show |SAx|2 = (1±ε)|Ax|2 for all x
Can assume columns of A are orthonormal
Can also assume x is a unit vector
SA is a k x d matrix of i.i.d. N(0,1/k) random variables
• Consider any fixed unit vector 𝑥 ∈ 𝑅𝑑
• SAx 22 = i∈ k < g i , x >2 , where g i is i-th row of SA
• Each < g i , x
>2
is distributed as N
1 2
0,
k
• E[< g i , x >2 ] = 1/k, and so E[ SAx 22 ] = 1
How concentrated is SAx 22 about its expectation?
Johnson-Lindenstrauss Theorem
• Suppose h1 , … , hk are i.i.d. N(0,1) random variables
• Then G = i h2i is a 𝜒 2 -random variable
• Apply known tail bounds to G:
– (Upper) Pr G ≥ k + 2 kx .5 + 2x ≤ e−x
– (Lower) Pr G ≤ k − 2 kx .5 ≤ e−x
• If x =
ϵ2 k
,
16
then Pr G ∈ k(1 ± ϵ) ≥ 1 −
2 k/16
−ϵ
2e
1
δ
• If k = Θ(ϵ−2 log( )), this probability is 1-δ
• Pr SAx 22 ∈ 1 ± ϵ ≥ 1 − 2−Θ d
This only holds for a fixed x, how to argue for all x?
Net for Sphere
• Consider the sphere Sd−1
• Subset N is a γ-net if for all x ∈ Sd−1 , there is a y ∈ N,
such that x − y 2 ≤ γ
• Greedy construction of N
– While there is a point x ∈ Sd−1 of distance larger than
γ from every point in N, include x in N
• The sphere of radius γ/2 around ever point in N is
contained in the sphere of radius 1+ γ around 0d
• Further, all such spheres are disjoint
• Ratio of volume of d-dimensional sphere of radius 1+ γ
to dimensional sphere of radius 𝛾 is 1 + γ d /(γ/2)d , so
N ≤ 1 + γ d /(γ/2)d
Net for Subspace
• Let M = {Ax | x in N}, so M ≤ 1 + γ d /(γ/2)d
• Claim: For every x in Sd−1 , there is a y in M for which
Ax − y 2 ≤ γ
• Proof: Let x’ in S d−1 be such that x − x ′ 2 ≤ γ
Then Ax − Ax ′ 2 = x − x ′ 2 ≤ γ, using that the
columns of A are orthonormal. Set y = Ax’
Net Argument
• For a fixed unit x, Pr SAx 22 ∈ 1 ± ϵ ≥ 1 − 2−Θ d
• For a fixed pair of unit x, x’, SAx 22 , SAx′ 22 , SA x − x ′
are all 1 ± ϵ with probability 1 − 2−Θ d
• SA x − x ′ 22 = SAx 22 + SAx ′ 22 − 2 < SAx, SAx ′ >
• A x − x ′ 22 = Ax 22 + Ax ′ 22 − 2 < Ax, Ax ′ >
– So Pr < Ax, Ax ′ > = < SAx, SAx ′ > ± O ϵ
2
2
= 1 − 2−Θ(d)
• Choose a ½-net M = {Ax | x in N} of size 5𝑑
• By a union bound, for all pairs y, y’ in M,
< y, y′ > = < Sy, Sy′ > ± O ϵ
• Condition on this event
• By linearity, if this holds for y, y’ in M, for αy, βy′ we have
< αy, βy′ > = αβ < Sy, Sy′ > ± O ϵ αβ
Finishing the Net Argument
• Let y = Ax for an arbitrary x ∈ Sd−1
• Let y1 ∈ M be such that y − y1 2 ≤ γ
• Let α be such that α(y − y1 ) 2 = 1
– α ≥ 1/γ (could be infinite)
• Let y2′ ∈ M be such that α y − y1 − y2 ′
• Then y − y1 −
y′2
.
α
y2 ′
α 2
≤
γ
α
2
≤γ
≤ γ2
• Set y2 =
Repeat, obtaining y1 , y2 , y3 , … such that for
all integers i,
y − y1 − y2 − … − yi 2 ≤ γi
• Implies yi 2 ≤ γi−1 + γi ≤ 2γi−1
Finishing the Net Argument
• Have y1 , y2 , y3 , … such that y =
• Sy
2
2
= |S
i yi
and yi
2
≤ 2γi−1
2
|
y
i i 2
=
i
Syi
=
i
yi
2
2
2
2
+2
+2
i,j
i,j
< Syi , Syj >
< yi , yj > ± O ϵ
i,j
yi
2
yj
= | i yi |22 ± O ϵ
= y 22 ± O ϵ
=1±O ϵ
• Since this held for an arbitrary y = Ax for unit x, by
linearity it follows that for all x, |SAx|2 = (1±ε)|Ax|2
2
Back to Regression
• We showed that S is a subspace
embedding, that is, simultaneously for all x,
|SAx|2 = (1±ε)|Ax|2
What does this have to do with regression?
Subspace Embeddings for
Regression
• Want x so that |Ax-b|2 · (1+ε) miny |Ay-b|2
• Consider subspace L spanned by columns of A
together with b
• Then for all y in L, |Sy|2 = (1± ε) |y|2
• Hence, |S(Ax-b)|2 = (1± ε) |Ax-b|2 for all x
• Solve argminy |(SA)y – (Sb)|2
• Given SA, Sb, can solve in poly(d/ε) time
Only problem is computing SA takes O(nd2) time
How to choose the right sketching matrix S? [S]
S is a Subsampled Randomized Hadamard Transform
S = P*H*D
D is a diagonal matrix with +1, -1 on diagonals
H is the Hadamard transform
P just chooses a random (small) subset of rows of H*D
S*A can be computed in O(nd log n) time
Why does it work?
31
Why does this work?
We can again assume columns of A are orthonormal
It suffices to show SAx
2
2
= PHDAx
HD is a rotation matrix, so HDAx
2
2
2
2
= 1 ± ϵ for all x
= Ax
2
2
= 1 for any x
Notation: let y = Ax
Flattening Lemma: For any fixed y,
Pr [ HDy
∞
≥C
log.5 nd/δ
]
n.5
≤
δ
2d
32
Proving the Flattening Lemma
Flattening Lemma: Pr [ HDy
∞
≥C
log.5 nd/δ
]
n.5
≤
δ
2d
Let C > 0 be a constant. We will show for a fixed i in [n],
Pr [ HDy
≥C
i
log.5 nd/δ
]
n.5
≤
δ
2nd
If we show this, we can apply a union bound over all i
HDy i = j Hi,j Dj,j yj
(Azuma-Hoeffding) Pr |
probability 1
t2
)
2 j β2
j
−(
j Zj |
> t ≤ 2e
, where |Zj | ≤ βj with
Zj = Hi,j Dj,j yj has 0 mean
|Zj | ≤
|yj |
n.5
1
2
β
=
j j
n
= βj with probability 1
nd
Pr |
j Zj | >
C log.5 δ
n.5
δ
C2 log
nd
−
2
≤ 2e
≤
δ
2nd
33
Consequence of the Flattening Lemma
Recall columns of A are orthonormal
HDA has orthonormal columns
Flattening Lemma implies HDAei
probability 1 −
δ
2d
With probability 1
∞
≤C
log.5 nd/δ
n.5
with
for a fixed i ∈ d
δ
− ,
2
Given this, ej HDA
2
ej HDAei
≤C
≤C
d.5 log.5 nd/δ
n.5
log.5 nd/δ
n.5
for all i,j
for all j
(Can be optimized further)
34
Matrix Chernoff Bound
Let X1 , … , Xs be independent copies of a symmetric random matrix X ∈ Rdxd
1
with E X = 0, X 2 ≤ γ, and E X T X 2 ≤ 𝜎 2 . Let W = s i∈[s] Xi . For any ϵ > 0,
Pr W
2
> ϵ ≤ 2d ⋅ e
(here W
γϵ
3
−sϵ2 /(𝜎2 + )
2
= sup Wx 2 / x 2 )
Let V = HDA, and recall V has orthonormal columns
Suppose P in the S = PHD definition samples uniformly with replacement. If
row i is sampled in the j-th sample, then Pj,i = n, and is 0 otherwise
Let Yi be the i-th sampled row of V = HDA
Let Xi = Id − n ⋅ YiT Yi
E X i = Id − n ⋅
Xi
2
≤ Id
1
j n
ViT Vi = Id − V T V = 0d
2 + n ⋅ max ej HDA
2
2
= 1 + n ⋅ C 2 log
nd
δ
d
⋅ n = Θ(d log
nd
δ
)
35
Matrix Chernoff Bound
Recall: let Yi be the i-th sampled row of V = HDA
Let Xi = Id − n ⋅ YiT Yi
E X T X + Id = Id + Id − 2n E YiT Yi + n2 E[YiT Yi YiT Yi ]
1
i n
nd
T
2
v
v
C
log
i
i i
δ
= 2Id − 2Id + n2
⋅ viT vi viT vi = n
d
⋅ n = C 2 dlog
T
i vi vi
nd
𝛿
⋅ 𝑣𝑖
2
2
Define Z = n
Note that 𝑋 𝑇 𝑋 + 𝐼𝑑 and Z are real symmetric, with non-negative
eigenvalues
Claim: for all vectors y, we have: 𝑦 𝑇 𝑋 𝑇 𝑋𝑦 + 𝑦 𝑇 𝑦 ≤ 𝑦 𝑇 𝑍𝑦
Proof: 𝑦 𝑇 𝑋 𝑇 𝑋𝑦 + 𝑦 𝑇 𝑦 = 𝑛 𝑖 𝑦 𝑇 𝑣𝑖𝑇 𝑣𝑖 𝑦 𝑣𝑖 22 = 𝑛 𝑖 < 𝑣𝑖 , 𝑦 >2 𝑣𝑖 22 and
𝑛𝑑 𝑑
𝑛𝑑
𝑇
𝑇
𝑇
2
2
2
𝑦 𝑍𝑦 = 𝑛
𝑦 𝑣𝑖 𝑣𝑖 𝑦 𝐶 log
⋅ =𝑛
< 𝑣𝑖 , 𝑦 > 𝐶 log
𝛿
𝑛
𝛿
𝑖
𝑋𝑇 𝑋
Hence, 𝐸
Hence, E X T X
𝐼𝑑
𝑖
2
2
≤ 𝐸 𝑋 𝑇 𝑋 + 𝐼𝑑
= |𝐸 𝑋 𝑇 𝑋 + 𝐼𝑑 |2 + 1
𝑛𝑑
2
≤ 𝑍 2 + 1 ≤ 𝐶 𝑑 log
+1
𝛿
= O d log
nd
δ
2
+ 𝐼𝑑
2
36
Matrix Chernoff Bound
nd
δ
Hence, E X T X
Recall: (Matrix Chernoff) Let X1 , … , Xs be independent copies of a
symmetric random matrix X ∈ Rdxd with E X = 0, X 2 ≤ γ, and E X T X
≤ 𝜎 2 . Let W =
2
1
s
= O d log
i∈[s] X i .
Pr |Id − PHDA
d
Set s = d log
nd log δ
δ
ϵ2
T
For any ϵ > 0, Pr W
PHDA
2
> ϵ ≤ 2d ⋅ e
−s ϵ2 /(Θ(d log
2
2
γϵ
−sϵ2 /(𝜎2 + 3 )
> ϵ ≤ 2d ⋅ e
nd
)
δ
δ
, to make this probability less than 2
37
SRHT Wrapup
Have shown |Id − PHDA
T
|2 < ϵ using Matrix
PHDA
Chernoff Bound and with s = d log
d
nd log δ
δ
ϵ2
samples
Implies for every unit vector x,
|1− PHDAx 22 | = x T x − x PHDA
so PHDAx
2
2
T
PHDA x < ϵ ,
∈ 1 ± ϵ for all unit vectors x
Considering the column span of A adjoined with b, we can
again solve the regression problem
The time for regression is now only O(nd log n) +
𝑑 log 𝑛
poly(
𝜖
38
). Nearly optimal in matrix dimensions (n >> d)
Faster Subspace Embeddings S [CW,MM,NN]
CountSketch matrix
Define k x n matrix S, for k = O(d2/ε2)
S is really sparse: single randomly chosen non-zero
entry per column
[
[
0010 01 00
1000 00 00
0 0 0 -1 1 0 -1 0
0-1 0 0 0 0 0 1
nnz(A) is number of non-zero entries of A
Can compute
S ⋅ A in nnz(A)
time!
39
Simple Proof [Nguyen]
Can assume columns of A are orthonormal
Suffices to show |SAx|2 = 1 ± ε for all unit x
For regression, apply S to [A, b]
SA is a 2d2/ε2 x d matrix
Suffices to show | ATST SA – I|2 · |ATST SA – I|F · ε
Matrix product result shown below:
Pr[|CSTSD – CD|F2 · [3/(𝛿(# rows of S))] * |C|F2 |D|F2] ≥ 1 − 𝛿
Set C = AT and D = A.
Then |A|2F = d and (# rows of S) = 3 d2/(δε2)
40
Matrix Product Result [Kane, Nelson]
Show: Pr[|CSTSD – CD|F2 · [3/(𝛿(# rows of S))] * |C|F2 |D|F2] ≥ 1 − 𝛿
(JL Property) A distribution on matrices S ∈ Rkx n has the (ϵ, δ, ℓ)-JL
moment property if for all x ∈ Rn with x 2 = 1,
ES Sx 22 − 1
ℓ
≤ ϵℓ ⋅ δ
(From vectors to matrices) For ϵ, δ ∈ 0,
1
2
, let D be a distribution on
matrices S with k rows and n columns that satisfies the (ϵ, δ, ℓ)-JL
moment property for some ℓ ≥ 2. Then for A, B matrices with n rows,
Pr AT S T SB − AT B
S
F
≥3ϵ A
F
B
F
≤δ
41
From Vectors to Matrices
1
(From vectors to matrices) For ϵ, δ ∈ 0, 2 , let D be a distribution on matrices
S with k rows and n columns that satisfies the (ϵ, δ, ℓ)-JL moment property
for some ℓ ≥ 2. Then for A, B matrices with n rows,
Pr AT S T SB − AT B
S
Proof: For a random scalar X, let X
Sometimes consider X = T
| T
F
|p = E T
p
F
F
p
≥3ϵ A
= EX
F
B
F
≤δ
p 1/p
for a random matrix T
1/p
Can show |. |p is a norm
Minkowski’s Inequality: X + Y
F
p
≤ X
p
+ Y
p
For unit vectors x, y, need to bound |〈Sx, Sy〉 - 〈x, y〉|ℓ
42
From Vectors to Matrices
For unit vectors x, y, |〈Sx, Sy〉 - 〈x, y〉|ℓ
=
≤
≤
1
(
2
1
(
2
1
2
Sx 22 −1 + Sy
Sx
2
2
2
2
− 1 ℓ + Sy
1
ℓ
−1 − S x−y
2
2
1
ℓ
−1 ℓ+ S x−y
(ϵ ⋅ δ +ϵ ⋅ δ + x − y
≤3ϵ⋅δ
2
2
2
2
− x−y
2
2
2
2
− x−y
|ℓ
2
2 ℓ)
1
ℓ
ϵ⋅δ )
1
ℓ
Sx,Sy − x,y ℓ
x2y2
1
ℓ
By linearity, for arbitrary x, y,
Suppose A has d columns and B has e columns. Let the columns of A be
A1 , … , Ad and the columns of B be B1 , … , Be
Define Xi,j =
AT S T SB
−
1
Ai 2 Bj
2
2
AT B F
=
≤3ϵ⋅δ
⋅ ( SAi , SBj − Ai , Bj )
i
2
j Ai 2
⋅
2 2
Bj Xi,j
2
43
From Vectors to Matrices
Have shown: for arbitrary x, y,
For Xi,j =
| AT ST SB − A B F |ℓ/2 =
1
Sx,Sy − x,y ℓ
x2y2
SAi , SBj − Ai , Bj : AT S T SB − AT B
⋅
Ai 2 Bj
2
T 2
i
≤
j
2
2
2
⋅ Bj Xi,j
j
Ai
2
2
2 |
⋅ Bj |Xi,j
ℓ/2
j
Ai
2
2
⋅ Bj
i
≤ 3ϵδ
1
ℓ
= 3 ϵδ
T T
T
Since E A S SB − A B
Pr
AT S T SB
−
AT B
F
ℓ
F
1
ℓ
2
F
=
i
j
Ai
2
2
2
2
⋅ Bj Xi,j
2
ℓ/2
2
2
2
2
Xi,j
Ai
2
2
2
i
2
A
j
2
F
B
2
ℓ
2
Bj
2
2
F
T T
T
= A S SB − A B
> 3ϵ A
2
2
Ai
i
=
≤3ϵ⋅δ
1
ℓ
ℓ/2
2
F ℓ
, by Markov’s inequality,
2
F
B
F
≤
1
3ϵ A F B F
ℓ
E |AT S T SB − AT B|ℓF ≤ δ
44
Result for Vectors
Show: Pr[|CSTSD – CD|F2 · [3/(𝛿(# rows of S))] * |C|F2 |D|F2] ≥ 1 − 𝛿
(JL Property) A distribution on matrices S ∈ Rkx n has the (ϵ, δ, ℓ)-JL moment
property if for all x ∈ Rn with x 2 = 1,
ES Sx
2
2
−1
ℓ
≤ ϵℓ ⋅ δ
1
(From vectors to matrices) For ϵ, δ ∈ 0, 2 , let D be a distribution on matrices
S with k rows and n columns that satisfies the (ϵ, δ, ℓ)-JL moment property
for some ℓ ≥ 2. Then for A, B matrices with n rows,
Pr AT S T SB − AT B
S
F
≥3ϵ A
F
B
F
≤δ
Just need to show that the CountSketch matrix S satisfies JL property and
bound the number k of rows
45
CountSketch Satisfies the JL Property
(JL Property) A distribution on matrices S ∈ Rkx n has the (ϵ, δ, ℓ)-JL moment
property if for all x ∈ Rn with x 2 = 1,
ES Sx
2
2
−1
ℓ
≤ ϵℓ ⋅ δ
We show this property holds with ℓ = 2. First, let us consider ℓ = 1
For CountSketch matrix S, let
h:[n] -> [k] be a 2-wise independent hash function
σ: n → {−1,1} be a 4-wise independent hash function
Let δ E = 1 if event E holds, and δ E = 0 otherwise
E[ Sx 22 ] =
j∈ k
E[
i∈ n
δ h i = j σi x i
=
j∈ k
i1,i2∈[n] E[δ
=
j∈ k
i∈[n] E[δ
=
1
k
j∈[k[
i∈ n
2
]
h i1 = j δ h i2 = j σi1 σi2 ]xi1 xi2
h i = j 2 ]xi2
xi2 = x
2
2
46
CountSketch Satisfies the JL Property
E[ Sx 42 ] = 𝐸[
𝑗1 ,𝑗2 ,𝑖1 .𝑖2 ,𝑖3 ,𝑖4
𝑗′∈
j∈ k
i∈ n
𝑘
δ h i = j σi xi
2
2
i′∈ n
δ h i′ = j′ σi′ xi′ ] =
𝐸[𝜎𝑖1 𝜎𝑖2 𝜎𝑖3 𝜎𝑖4 𝛿 ℎ 𝑖1 = 𝑗1 𝛿 ℎ 𝑖2 = 𝑗1 𝛿 ℎ 𝑖3 = 𝑗2 𝛿 ℎ 𝑖4 = 𝑗2 ]𝑥𝑖1 𝑥𝑖2 𝑥𝑖3 𝑥𝑖4
We must be able to partition {𝑖1 , 𝑖2 , 𝑖3 , 𝑖4 } into equal pairs
Suppose 𝑖1 = 𝑖2 = 𝑖3 = 𝑖4 . Then necessarily 𝑗1 = 𝑗2 . Obtain
Suppose 𝑖1 = 𝑖2 and 𝑖3 = 𝑖4 but 𝑖1 ≠ 𝑖3 . Then get
Suppose 𝑖1 = 𝑖3 and 𝑖2 = 𝑖4 but 𝑖1 ≠ 𝑖2 . Then necessarily 𝑗1 = 𝑗2 . Obtain
1
1
2 2
4
𝑥
𝑥
≤
𝑥
2 . Obtain same bound if 𝑖1 = 𝑖4 and 𝑖2 = 𝑖3 .
𝑗 𝑘 2 𝑖1 ,𝑖2 𝑖1 𝑖2
𝑘
Hence, E[ Sx 42 ] ∈ [ x 42 , 𝑥 42 (1 + 𝑘)] = [1, 1 + k]
So, ES Sx
2
2
2
−1
2
2
1
𝑗𝑘
4
𝑖 𝑥𝑖
1 2 2
𝑗1 ,𝑗2 ,𝑖1 ,𝑖3 𝑘 2 𝑥𝑖1 𝑥𝑖3
= 𝑥
= 𝑥
4
2
4
4
− 𝑥
4
4
2
2
1
≤ 1 + 𝑘 − 2 + 1 = 𝑘 . Setting k = 2𝜖2 𝛿 finishes the proof
47
Where are we?
(JL Property) A distribution on matrices S ∈ Rkx n has the (ϵ, δ, ℓ)-JL
moment property if for all x ∈ Rn with x 2 = 1,
ES Sx
2
2
−1
ℓ
≤ ϵℓ ⋅ δ
1
(From vectors to matrices) For ϵ, δ ∈ 0, 2 , let D be a distribution on
matrices S with k rows and n columns that satisfies the (ϵ, δ, ℓ)-JL moment
property for some ℓ ≥ 2. Then for A, B matrices with n rows,
Pr AT S T SB − AT B
S
2
F
≥ 3 ϵ2 A
2
F
B
2
F
≤δ
2
We showed CountSketch has the JL property with ℓ = 2, 𝑎𝑛𝑑 𝑘 = 𝜖2 𝛿
Matrix product result we wanted was:
Pr[|CSTSD – CD|F2 · (3/(𝛿k)) * |C|F2 |D|F2] ≥ 1 − 𝛿
We are now down with the proof CountSketch is a subspace embedding
48
Course Outline
Subspace embeddings and least squares regression
Gaussian matrices
Subsampled Randomized Hadamard Transform
CountSketch
Affine embeddings
Application to low rank approximation
High precision regression
Leverage score sampling
49
Affine Embeddings
Want to solve min 𝐴𝑋 − 𝐵 2𝐹 , A is tall and thin with d columns, but B has a large
𝑋
number of columns
Can’t directly apply subspace embeddings
Let’s try to show SAX − SB
we need of S
Can assume A has orthonormal columns
Let 𝐵 ∗ = 𝐴𝑋 ∗ − 𝐵, where 𝑋 ∗ is the optimum
F
= 1 ± ϵ AX − B
F
for all X and see what properties
𝑆 𝐴𝑋 − 𝐵 2𝐹 − 𝑆𝐵 ∗ 2𝐹 = 𝑆𝐴 𝑋 − 𝑋 ∗ + 𝑆 𝐴𝑋 ∗ − 𝐵 2𝐹 − 𝑆𝐵 ∗ 2𝐹
= 𝑆𝐴 𝑋 − 𝑋 ∗ 2𝐹 − 2𝑡𝑟[ 𝑋 − 𝑋 ∗ 𝑇 𝐴𝑇 𝑆 𝑇 𝑆𝐵∗ ]
∈ 𝑆𝐴 𝑋 − 𝑋 ∗ 2𝐹 ± 2 𝑋 − 𝑋 ∗ 𝐹 𝐴𝑇 𝑆 𝑇 𝑆𝐵 ∗ 𝐹 (use 𝑡𝑟 𝐶𝐷 ≤ 𝐶 𝐹 𝐷 𝐹 )
∈ 𝑆𝐴 𝑋 − 𝑋 ∗ 2𝐹 ±2𝜖 𝑋 − 𝑋 ∗ 𝐹 B ∗ F (if we have approx. matrix product)
∈ 𝐴 𝑋 − 𝑋 ∗ 2𝐹 ± 𝜖( 𝐴 𝑋 − 𝑋 ∗ 2𝐹 + 2 𝑋 − 𝑋 ∗ 𝐹 𝐵 ∗ ) (subspace embedding for50A)
Affine Embeddings
We have 𝑆 𝐴𝑋 − 𝐵
2
𝐹
− 𝑆𝐵∗
2
𝐹
∈ 𝐴 𝑋 − 𝑋∗
2
𝐹
± 𝜖(|𝐴(𝑋
51
Affine Embeddings
Know: 𝑆 𝐴𝑋 − 𝐵 2𝐹 − 𝑆𝐵∗ 2𝐹 − 𝐴𝑋 − 𝐵
±2𝜖 𝐴𝑋 − 𝐵 2𝐹
Know: 𝑆𝐵∗ 2𝐹 = 1 ± 𝜖 𝐵∗ 2𝐹
𝑆 𝐴𝑋 − 𝐵
2
𝐹
= (1 ± 2𝜖) 𝐴𝑋 − 𝐵 2𝐹 +𝜖 𝐵∗
= 1 ± 3𝜖 𝐴𝑋 − 𝐵 2𝐹
2
𝐹
− 𝐵∗
2
𝐹
∈
2
𝐹
Completes proof of affine embedding!
52
Affine Embeddings: Missing Proofs
Claim: A + B
2
F
= A
2
F
Proof: A + B
2
F
=
Ai + Bi
2
2
2
2
Bi
=
i
Ai
+ B
+
i
= A
2
F
+ 2Tr(AT B)
2
2
+ 2〈Ai , Bi 〉
i
2
F
+ B
2
F
+ 2Tr(AT B)
53
Affine Embeddings: Missing Proofs
Claim: Tr AB ≤ A
i
Ai
2
≤
2
i
i A 2
= A
F
B
B
F
i
i〈A , Bi 〉
Proof: Tr AB =
≤
F
Bi
1
2
2
for rows Ai and columns Bi
by Cauchy-Schwarz for each i
1
2 2
B
i i 2
another Cauchy-Schwarz
F
54
Affine Embeddings: Homework Proof
Claim: SB ∗ 2F = 1 ± ϵ B ∗ 2F with constant probability if
1
CountSketch matrix S has k = O( 2 ) rows
ϵ
Proof:
SB ∗ 2F =
i
SBi∗
2
2
By our analysis for CountSketch and linearity of expectation,
E SB ∗ 2F = i E SBi∗ 22 = B ∗ 2F
E[ SB ∗ 4F ] =
i,j
E[ SBi∗
2
2
2
SBj∗ ]
2
By our CountSketch analysis,E[
SBi∗ 42 ]]
≤
For cross terms see Lemma 40 in [CW13]
2
∗ 4
Bi 2 (1 + )
k
55
Low rank approximation
A is an n x d matrix
Think of n points in Rd
E.g., A is a customer-product matrix
Ai,j = how many times customer i purchased item j
A is typically well-approximated by low rank matrix
E.g., high rank because of noise
Goal: find a low rank matrix approximating A
Easy to store, data more interpretable
56
What is a good low rank approximation?
Singular Value Decomposition (SVD)
Any matrixAAk == argmin
U ¢ Σ ¢ rank
V k matrices B |A-B|F
U has orthonormal columns
Σ is diagonal with non-increasing
positive
1/2
2
(|C|
)
F = (Σ
i,jVC
i,j )
The
rows
of
are
k
entries down the diagonal
the orthonormal
top k principal
V has
rows
components
Computing
Ak exactly is
expensive
Rank-k approximation:
Ak = Uk ¢ Σk ¢ Vk
57
Low rank approximation
Goal: output a rank k matrix A’, so that
|A-A’|F · (1+ε) |A-Ak|F
Can do this in nnz(A) + (n+d)*poly(k/ε) time [S,CW]
nnz(A) is number of non-zero entries of A
58
Solution to low-rank approximation [S]
Given n x d input matrix A
Compute S*A using a random matrix S with k/ε << n
rows. S*A takes random linear combinations of rows of A
A
SA
Project rows of A onto SA, then find best rank-k
approximation to points inside of SA.
59
What is the matrix S?
S can be a k/ε x n matrix of i.i.d. normal random
variables
[S] S can be a k/ε x n Fast Johnson Lindenstrauss
Matrix
Uses Fast Fourier Transform
[CW] S can be a poly(k/ε) x n CountSketch matrix
[
[
0010 01 00
1000 00 00
0 0 0 -1 1 0 -1 0
0-1 0 0 0 0 0 1
S ¢ A can be
computed in
nnz(A) time
60
Why do these Matrices Work?
Consider the regression problem min Ak X − A
Write Ak = WY, where W is n x k and Y is k x d
Let S be an affine embedding
Then SAk X − SA
By normal equations, argmin SAk X − SA
X
F
= 1 ± ϵ Ak X − A
F
X
− SA −
for all X
F
= SAk
So, Ak SAk
But Ak SAk
Let’s formalize why the algorithm works now…
− SA
A
F
≤ 1 + ϵ Ak − A
F
− SA
F
is a rank-k matrix in the row span of SA!
61
Why do these Matrices Work?
min
rank−k X
XSA − A
2
F
≤ Ak SAk
−
SA − A|2F ≤ 1 + ϵ A − A_k|2F
By the normal equations,
XSA − A 2F = XSA − A SA − SA
Hence,
min
rank−k X
XSA − A
2
F
= A SA − SA − A
2
F
2
F
+
+ A SA − SA − A
min
rank−k X
2
F
XSA − A SA − SA
Can write SA = U ΣV T in its SVD, where U, Σ are k x k and V T is k x d
Then, min
rank−k X
XSA − A SA − SA
2
F
=
=
min
XUΣ − A SA − UΣ
min
Y − A SA − UΣ
rank−k X
rank−k Y
2
F
2
F
2
F
Hence, we can just compute the SVD of A SA − UΣ
But how do we compute A SA
− UΣ
quickly?
62
Caveat: projecting the points onto SA is slow
Current algorithm:
1. Compute S*A
2. Project each of the rows onto S*A
3. Find best rank-k approximation of projected points
inside of rowspace of S*A
minrank-k X |X(SA)R-AR|F2
Bottleneck is step 2
Can solve with affine embeddings
[CW] Approximate the projection
Fast algorithm for approximate regression
minrank-k X |X(SA)-A|F2
Want nnz(A) + (n+d)*poly(k/ε) time
63
Using Affine Embeddings
2
F
We know we can just output arg min
Choose an affine embedding R:
XSAR − AR 2F = 1 ± ϵ XSA − A
rank−k X
XSA − A
Note: we can compute AR and SAR in nnz(A) time
Can just solve
min
rank−k X
min
rank−k X
XSAR − AR
2
F
XSAR − AR
= AR SAR
−
2
F
for all X
2
F
−
SAR − AR
2
F
2
F
+
min
rank−k X
XSAR − AR SAR
k
ϵ
−
SAR
2
F
Compute
Necessarily, Y = XSAR for some X. Output Y SAR − SA in factored form. We’re done!
min
rank−k Y
Y − AR SAR
SAR
using SVD which is n + d poly
time
64
Low Rank Approximation Summary
1. Compute SA
2. Compute SAR and AR
3. Compute
min
rank−k Y
Y − AR SAR
−
SAR
2
F
using SVD
4. Output Y SAR − SA in factored form
Overall time: nnz(A) + (n+d)poly(k/ε)
65
Course Outline
Subspace embeddings and least squares regression
Gaussian matrices
Subsampled Randomized Hadamard Transform
CountSketch
Affine embeddings
Application to low rank approximation
High precision regression
Leverage score sampling
66
High Precision Regression
Goal: output x‘ for which |Ax‘-b|2 · (1+ε) minx |Ax-b|2
with high probability
Our algorithms all have running time poly(d/ε)
Goal: Sometimes we want running time poly(d)*log(1/ε)
Want to make A well-conditioned
κ A = sup Ax 2 / inf Ax 2
x 2 =1
x 2 =1
Lots of algorithms’ time complexity depends on κ A
Use sketching to reduce κ A to O(1)!
67
Small QR Decomposition
Let S be a 1 + ϵ0 - subspace embedding for A
Compute SA
Compute QR-factorization, SA = QR−1
Claim: κ AR =
1+ϵ0
1−ϵ0
For all unit x, 1 − ϵ0 ARx
2
≤ SAR x 2 = 1
For all unit x, 1 + ϵ0 ARx
2
≥ SARx
So κ AR = sup ARx 2 / inf ARx
x 2 =1
x 2 =1
2
2
=1
≤
1+ϵ0
1−ϵ0
68
Finding a Constant Factor Solution
Let S be a 1 + ϵ0 - subspace embedding for AR
Solve x0 = argmin SARx − Sb
x
2
Time to compute AR and x0 is nnz(A) + poly(d) for constant ϵ0
xm+1 ← xm + RT AT b − AR xm
AR xm+1 − x ∗ = AR (xm + RT AT b − ARxm − x ∗ )
= AR − ARRT AT AR xm − x ∗
= U Σ − Σ 3 V T (xm − x ∗ ),
where AR = U ΣV T is the SVD of AR
AR xm+1 − x ∗
ARxm − b
2
2
2
=
Σ − Σ 3 V T xm − x ∗
= AR xm −
x∗
2
2
+
2
ARx ∗
= O ϵ0 |AR(xm − x ∗ )|2
−b
2
2
69
Course Outline
Subspace embeddings and least squares regression
Gaussian matrices
Subsampled Randomized Hadamard Transform
CountSketch
Affine embeddings
Application to low rank approximation
High precision regression
Leverage score sampling
70
Leverage Score Sampling
This is another subspace embedding, but it is based on sampling!
If A has sparse rows, then SA has sparse rows!
Let A = U ΣV T be an n x d matrix with rank d, written in its SVD
Define the i-th leverage score ℓ i
What is
iℓ
of A to be Ui,∗
2
2
i ?
Let q1 , … , qn be a distribution with qi ≥
βℓ i
d
, where β is a parameter
Define sampling matrix S = D ⋅ ΩT , where D is k x k and Ω is n x k
Ω is a sampling matrix, and D is a rescaling matrix
For each column j of Ω, D, independently, and with replacement, pick a row
index i in [n] with probability qi , and set Ωi,j = 1 and Dj,j = (qi k)^(.5) 71
Leverage Score Sampling
Note: leverage scores do not depend on choice of orthonormal
basis U for columns of A
Indeed, let U and U’ be two such orthonormal bases
Claim: ei U
2
2
= ei U′
2
2
for all i
Proof: Since both U and U’ have column space equal to that of A,
we have U = U ′ Z for change of basis matrix Z
Since U and U’ each have orthonormal columns, Z is a rotation
matrix (orthonormal rows and columns)
Then ei U
2
2
= ei U′ Z
2
2
= ei U′
2
2
72
Leverage Score Sampling gives a Subspace Embedding
2
2
2
2
Want to show for S = D ⋅ ΩT , that SAx
Writing A = U ΣV T in its SVD, this is equivalent to showing
= 1 ± ϵ Uy 22 = 1 ± ϵ y 22 for all y
As usual, we can just show with high probability, U T S T SU − I
How can we analyze U T S T SU?
(Matrix Chernoff) Let X1 , … , Xk be independent copies of a symmetric
random matrix X ∈ Rdxd with E X = 0, X 2 ≤ γ, and E X T X 2 ≤ σ2 . Let W
1
=k
j∈[k] X j .
= 1 ± ϵ Ax
for all x
SUy
2
2
2
≤ϵ
For any ϵ > 0,
γϵ
Pr W
(here W
2
= sup
Wx 2
.
x2
2
−kϵ2 /(σ2 + 3 )
> ϵ ≤ 2d ⋅ e
Since W is symmetric, W
2
= sup x T Wx . )
x 2 =1
73
Leverage Score Sampling gives a Subspace Embedding
Let i(j) denote the index of the row of U sampled in the j-th trial
UT
i(j) Ui(j)
Let Xj = Id −
The Xj are independent copies of a symmetric matrix random variable
E
2
≤ Id
XTX
2
+
UT
i j Ui j 2
qi j
= Id − 2E
=
, where Ui(j) is the j-th sampled row of U
UT
i Ui
i qi
qi
E X j = Id −
Xj
qi(j)
= Id − Id = 0d
≤ 1 + max
UT
i j Ui j
qi j
T
UT
i Ui Ui Ui
i
q i
i
+E
− Id ≤
Ui 22
qi
d
≤1+β
T
UT
i j Ui j Ui j Ui j
q2i j
d
β
T
T
i Ui Ui − Id ≤
d
β
− 1 Id ,
where A ≤ B means x T Ax ≤ x Bx for all x
d
Hence, |E X T X |2 ≤ β − 1
74
Applying the Matrix Chernoff Bound
(Matrix Chernoff) Let X1 , … , Xk be independent copies of a symmetric
random matrix X ∈ Rdxd with E X = 0, X 2 ≤ γ, and E X T X 2 ≤ σ2 . Let W
1
=k
j∈[k] X j .
For any ϵ > 0,
Pr W
(here W
2
= sup
d
γ = 1 + β, and σ2 =
X j = Id −
UT
i j Ui j
qi j
Wx 2
.
x2
d
β
2
γϵ
3
−kϵ2 /(σ2 + )
> ϵ ≤ 2d ⋅ e
Since W is symmetric, W
2
= sup x T Wx . )
x 2 =1
−1
, and recall how we generated S = D ⋅ ΩT : For each
column j of Ω, D, independently, and with replacement, pick a row index i in
[n] with probability qi , and set Ωi,j = 1 and Dj,j = (qi k)^(.5)
Implies W = Id − UT S T SU
Pr Id −
U T S T SU
β
2
> ϵ ≤ 2d ⋅
−kϵ2 Θ d
e
d log d
)
βϵ2
. Set k = Θ(
and we’re done.
75
Fast Computation of Leverage Scores
Naively, need to do an SVD to compute leverage scores
Suppose we compute SA for a subspace embedding S
Let SA = QR−1 be such that Q has orthonormal columns
Set ℓ′i = ei AR
2
2
Since AR has the same column span of A, AR = UT −1
1 − ϵ ARx 2 ≤ SARx 2 = x 2
1 + ϵ ARx 2 ≥ SARx 2 = x 2
1 ± O(ϵ ) x 2 = ARx 2 = UT −1 x 2 = T −1 x 2 ,
ℓi = ei ART
2
2
= 1 ± O(ϵ) ei AR
2
2
= 1 ± O(ϵ) ℓi ′
But how do we compute AR? We want nnz(A) time
76
Fast Computation of Leverage Scores
ℓi = 1 ± O(ϵ) ℓi ′
Suffices to set this ϵ to be a constant
Set ℓ′i = ei AR 22
This takes too long
Let G be a d x O(log n) matrix of i.i.d. normal random variables
For any vector z, Pr[ zG
2
2
= 1±
1
2
z 2] ≥ 1 −
1
n2
Instead set ℓ′i = ei ARG 22 .
Can compute in (nnz(A) + d2 ) log n time
Can solve regression in nnz(A) log n + poly(d(log n)/ε) time
77
Course Outline
Subspace embeddings and least squares regression
Gaussian matrices
Subsampled Randomized Hadamard Transform
CountSketch
Affine embeddings
Application to low rank approximation
High precision regression
Leverage score sampling
Distributed Low Rank Approximation
78
Distributed low rank approximation
We have fast algorithms for low rank approximation, but
can they be made to work in a distributed setting?
Matrix A distributed among s servers
For t = 1, …, s, we get a customer-product matrix from
the t-th shop stored in server t. Server t’s matrix = At
Customer-product matrix A = A1 + A2 + … + As
Model is called the arbitrary partition model
More general than the row-partition model in which each
customer shops in only one shop
79
The Communication Model
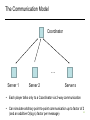
Coordinator
…
Server 1
Server 2
Server s
• Each player talks only to a Coordinator via 2-way communication
• Can simulate arbitrary point-to-point communication up to factor of 2
80
(and an additive O(log s) factor per message)
Communication cost of low rank approximation
Input: n x d matrix A stored on s servers
Server t has n x d matrix At
A = A1 + A2 + … + As
Assume entries of At are O(log(nd))-bit integers
Output: Each server outputs the same k-dimensional space W
C = A1 PW + A2 PW + … + As PW , where PW is the projector onto W
|A-C|F · (1+ε)|A-Ak|F
Application: k-means clustering
Resources: Minimize total communication and computation.
Also want O(1) rounds and input sparsity time
81
Work on Distributed Low Rank Approximation
[FSS]: First protocol for the row-partition model.
O(sdk/ε) real numbers of communication
Don’t analyze bit complexity (can be large)
SVD Running time, see also [BKLW]
[KVW]: O(skd/ε) communication in arbitrary partition model
[BWZ]: O(skd) + poly(sk/ε) words of communication in
arbitrary partition model. Input sparsity time
Matching Ω(skd) words of communication lower bound
Variants: kernel low rank approximation [BLSWX], low rank
approximation of an implicit matrix [WZ], sparsity [BWZ]
82
Outline of Distributed Protocols
[FSS] protocol
[KVW] protocol
[BWZ] protocol
83
Constructing a Coreset [FSS]
Let A = U ΣV T be its SVD
Let m = k + k/ϵ
Let Σm agree with Σ on the first m diagonal entries, and be 0
otherwise
Claim: For all projection matrices Y=I-X onto (n-k)-dimensional
subspaces,
Σm V T Y
where c = A −
2
F
Am 2F
= 1 ± ϵ AY
2
F
+ c,
does not depend on Y
T so that SA = U T UΣV T = Σ V T is a sketch
We can think of S as Um
m
m
84
Constructing a Coreset
Claim: For all projection matrices Y=I-X onto (n-k)-dimensional subspaces,
Σm V T Y
where c = A − Am
Proof: AY
2
F
= AX
=
2
F
2
TX
−
Σ
V
m
F
− Σm V T X
Σ − Σm V T X
+ U Σ − Σm V T Y
F
+ A − Am
F
+ A − Am
F
= Σm V T
does not depend on Y
2
2
Also, Σm V T Y
2
+
c
=
1
±
ϵ
AY
F,
F
2
= UΣm V T Y
≤ Σm V T Y
2
F
2
2
F
2
− AY
2
F
2
F
= Σm V T Y
2
F
+c
2
F
+ A − Am
F
2
F
− A
2
F
+ AX
2
F
2
F
2
F
2
≤ Σ − Σm V T 2 ⋅
≤ σ2m+1 k ≤ ϵ σ2m+1
X
2
F
m−k+1 ≤ϵ
2
i∈{k+1,..,m+1} σi
≤ ϵ A − Ak
2
F
85
Unions of Coresets
Suppose we have matrices A1 , … , As and construct
1 T,1 2 T,2
s T,s
Σm
V , Σm V , … , Σm
V as in the previous slide, together with c1 , … , cs
i T,i
Then i
Σm
V Y F + ci = 1 ± ϵ AY 2F , where A is the matrix formed by
concatenating the rows of A1 , … , As
Let B be the matrix obtained by concatenating the rows of
1 V T,1 , Σ 2 V T,2 , … , Σ s V T,s
Σm
m
m
Suppose we compute B = U ΣV T and compute Σm V T and B − Bm
Then Σm V T Y
So Σm V T and the constant c +
2
2
+c+
F
i ci
= 1 ± ϵ BY
i ci
2
F
+
i ci
= 1 ± O(ϵ) AY
2
F
2
F
are a coreset for A
86
[FSS] Row-Partition Protocol
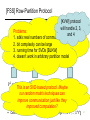
[KVW] protocol
will handle 2, 3,
Problems:
Coordinator and 4
1. sdk/ε real numbers of communication
2. bit complexity can be large
3. running time for SVDs [BLKW]
4. doesn’t work in arbitrary partition model
…
P s ∈ Rn s x d
P 2 ∈ Rn2 x d
P1 ∈ Rn1 x d
This is an SVD-based protocol. Maybe
our random matrix techniques can t
Server t sends the top k/ε + k principal components of P , scaled by the top
improve communication just like they
k/ε + k singular values Σ t , together with 𝑐 𝑡
improved computation?
Coordinator returns top k principal components of Σ1 V1 ; Σ 2 V 2 ; … ; Σ s V s
87
[KVW] Arbitrary Partition Model Protocol
Inspired by the sketching algorithm presented earlier
Fix:
Problems:
Let S be
one ofofthe
k/ε x n random
matrices
Instead
projecting
A onto SA,
recalldiscussed
2 small seed
Can’t
output
projection
of At onto
SA
since
Scan
be
generated
pseudorandomly
from
T
we can solve min A SA XSA − A F
rank−k X
the rank is too
large
Coordinator
sends
small seed for S to all servers
Let 𝑇1 , 𝑇2 be affine embeddings, solve
2
T
Could
communicate
this
projection
min T1 A SA XSAT2 − T1 AT2 F to the
t and sends it to Coordinator
rank−k
X
Server
t
computes
SA
coordinator
whoproblem
could find
a k-dimensional
(optimization
is small
and has a
space, form
but communication
depends on n
closed
solution)
s SAt = SA to all servers
Coordinator
sends
Σ
t=1
Everyone can then compute XSA and
then output k directions
There is a good k-dimensional subspace inside of SA. If
we knew it, t-th server could output projection of At onto it88
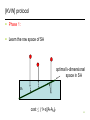
[KVW] protocol
Phase 1:
Learn the row space of SA
optimal k-dimensional
space in SA
SA
cost · (1+ε)|A-Ak|F
89
[KVW] protocol
Phase 2:
Find an approximately optimal space W inside of SA
optimal space in SA
approximate
space W in SA
SA
cost · (1+ε)2|A-Ak|F
90
[BWZ] Protocol
Main Problem: communication is O(skd/ε) + poly(sk/ε)
We want O(skd) + poly(sk/ε) communication!
Idea: use projection-cost preserving sketches [CEMMP]
Let A be an n x d matrix
If S is a random k/ε2 x n matrix, then there is a constant
𝑐 ≥ 0 so that for all k-dimensional projection matrices P:
SA I − P F + c = 1 ± ϵ A I − P F
91
[BWZ] Protocol
Let S be a k/ε2 x n projection-cost preserving sketch
Let T be a d x k/ε2 projection-cost
preserving
sketch
Intuitively,
U looks like
top k
t
Server t sends SA T to Coordinator
left singular vectors of SA
Coordinator sends back SAT =
t
t SA T
to servers
Thus, U T SA looks like2 top k
Each right
server
computes
k/ε of
x kSA
matrix U of top k left singular
singular
vectors
vectors of SAT
Server t sends U T SAt Top
to Coordinator
k right singular vectors of SA
work because S is a projectioncost preserving sketch!
Coordinator returns the space U T SA =
tU
T SAt
to output
92
[BWZ] Analysis
Let W be the row span of UT SA, and P be the projection onto W
Want to show A − AP
F
≤ 1 + ϵ A − Ak
F
Since T is a projection-cost preserving sketch,
(*)
SA − SAP
F
≤ SA − UUT SA
F
+ c1 ≤ 1 + ϵ SA − SA
k F
Since S is a projection-cost preserving sketch, there is a scalar c >
0, so that for all k-dimensional projection matrices P,
SA − SAP
F
+ c = 1 ± ϵ A − AP
Add c to both sides of (*) to conclude A − AP
F
F
≤ 1 + ϵ A − Ak
F
93
Conclusions for Distributed Low Rank Approximation
[BWZ] Optimal O(sdk) + poly(sk/ε) communication protocol for low
rank approximation in arbitrary partition model
Handle bit complexity by adding Tao/Vu noise
Input sparsity time
2 rounds, which is optimal [W]
Optimal data stream algorithms improves [CW, L, GP]
Communication of other optimization problems?
Computing the rank of an n x n matrix over the reals
Linear Programming
Graph problems: Matching
etc.
94
Additional Time-Permitting Topics
Will cover some recent topics at a research-level (many
details omitted)
Weighted Low Rank Approximation
Regression and Low Rank Approximation with MEstimator Loss Functions
Finding Heavy Hitters in a Data Stream optimally
95