Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
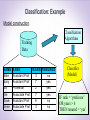
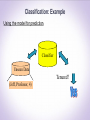
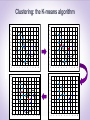
3rd International Conference Frontiers in Diagnostic Technologies November 25-27, 2013, Laboratori Nazionali di Frascati From Patterns in Data to Knowledge Discovery: what Data Mining can do Francesco Gullo Barcelona [email protected] 1 What is Data Mining ? Several definitions: • “Automated yet non-trivial extraction of implicit, previously unknown, and potentially useful information from data” • “Automated exploration and analysis of large quantities of data in order to discover meaningful patterns” • “Computational process of automatically extracting useful knowledge from large amounts of data” Keywords: large amounts of data, automation, knowledge What is Data Mining ? The analysis step of the "Knowledge Discovery in Databases" (KDD) process Why Data Mining ? • Lots of data is being collected/stored • web-data • e-commerce data • purchases • bank transactions • Lots of data is being processed at enormous speeds (GB/minutes) • remote sensors on a satellite • telescopes scanning the skies • microarray generating gene expression data • scientific simulations generating terabytes of data Data analysis in such a challenging contexts cannot be performed with traditional data-analysis techniques, neither manual nor automated Data Mining: an inter-disciplinary field Artificial Intelligence Statistics Data Mining Database systems Machine Learning Data-Mining Tasks • Predictive tasks • Use some variables to predict unknown or future values of other variables • Classification • Regression • Deviaton detection • Descriptive tasks • Find human-interpretable patterns that well-describe the data • Clustering • Association-rule discovery • Pattern discovery Data-Mining Tasks • Predictive tasks • Use some variables to predict unknown or future values of other variables • Classification • Regression • Deviaton detection • Descriptive tasks • Find human-interpretable patterns that well-describe the data • Clustering • Association-rule discovery • Pattern discovery Classification • Given a collection of records (i.e., the training set) • Each record contains a set of attributes, one of the attributes denotes the class of the record • Find a model (i.e., train a classifier) for class attribute as a function of the values of the other attributes • Goal: predict the class attribute of previously unobserved records based on the model found • A test set of records is often used in order to evaluate the accuracy of the model Classification: Example Model construction: Training Data NAME M ike M ary B ill Jim D ave A nne RANK YEARS TENURED A ssistant P rof 3 no A ssistant P rof 7 yes P rofessor 2 yes A ssociate P rof 7 yes A ssistant P rof 6 no A ssociate P rof 3 no Classification Algorithms Classifier (Model) IF rank = ‘professor’ OR years > 6 THEN tenured = ‘yes’ Classification: Example Using the model for prediction: Classifier Unseen Data Tenured? (Jeff, Professor, 4) Classification: Application 1 Fraud Detection • Goal: Predict fraudolent cases in credit-card transactions • Approach: • Use credit-card transactions and the information about its account-holder as attributes • e.g., when/what/where does the account-holder buy ? • Assign a {fraud, fair} class attribute value to each transaction based on historical data • Learn a model based on this data • Process each new transaction with this model in order to predict whether the transaction is fraudolent or fair Classification: Application 2 Sky Survey Cataloging • Goal: Predict class type (e.g., star or galaxy) of sky objects based on telescopic-survey images • Approach: • Segment each image and represent each segment as a set of attributes, such as RGB values, color intensity, brightness • Assign a {star,galaxy} class attribute value to each image • Learn a model based on this data • Predict the class type of unlabeled images based on the model learnt Classification: Decision Trees A decision tree is a tree where: • Internal nodes: test on a single attribute • Branch: an outcome of the test • Leaf nodes: class A? B? D? C? Yes Decision Trees: example (“Play tennis?”) Training set (from Quinlan’s book) : Outlook sunny sunny overcast rain rain rain overcast sunny sunny rain sunny overcast overcast rain Temperature Humidity Windy Class hot high false N hot high true N hot high false Y mild high false Y cool normal false Y cool normal true N cool normal true Y mild high false N cool normal false Y mild normal false Y mild normal true Y mild high true Y hot normal false Y mild high true N Decision Trees: example (“Play tennis?”) Decision tree obtained with the ID3 algorithm: outlook sunny overcast humidity rain windy Y high normal true false N Y N Y Clustering • Given a set of data points, each having a set of attributes, and a similarity measure among them, find groups of objects (i.e., clusters) such that: • Data points in the same cluster are highly-similar to each other (high intra-cluster compactness) • Data points in different clusters are highly-dissimilar to each other (high inter-cluster separation) • Clustering is also known as unsupervised classification: unlike (supervised) classification, clustering does not rely on any labeled data • Often used as a preliminary (exploratory) step of more-complex tasks Clustering Euclidean-distance-based clustering in 2D space Clustering: Application 1 Market segmentation • Goal: subdivide a market into distinct subsets of customers where any subset may be selected as a market target to be reached with a distinct marketing mix • Approach: • Collect different attributes of customers based on their, e.g., geographical and lifestyle-related information • Define an appropriate measure of distance among customers based on such attributes • Find clusters of similar customers Clustering: Application 2 Find topic-coherent documents • Goal: find groups of documents that are about the same (set of) topic(s) • Approach: • Represent each document as a set of attributes, each of which corresponding to the frequency of a term in the document • Define a proper distance measure among term-frequencyrepresented documents • Cluster the documents • Eventually use clusters to relate new documents to the clustered ones Clustering: the K-means algorithm Clustering: the K-means algorithm 10 10 9 9 8 8 7 7 6 6 5 5 4 4 3 3 2 2 1 1 0 0 0 1 2 3 4 5 6 7 8 9 10 10 10 9 9 8 8 7 7 6 6 5 5 4 4 3 3 2 2 1 1 0 1 0 1 2 3 4 5 6 7 8 5 6 7 8 9 10 0 0 0 1 2 3 4 5 6 7 8 9 10 2 3 4 9 10 Association-rule discovery • Given a set of records (transactions), each of which containing a number of items from a given collection, produce dependency rules which will predict occurrence of an item based on occurrences of other items Association-rule discovery: Application 1 Marketing and sales promotion • Assume to have learnt a rule {Milk, Cheese} {Chips}: • Milk, and Cheese can be used to boost the sales of Chips (e.g., by storing the former items close to Chips) • The sale of Chips will be affected if Milk and Cheese will not be sold anymore • Putting Milk in bundle promotion with Cheese will boost the sale of Chips Data Mining in emerging domains: Graph Mining Graph Data • G = (V, E), where V is a set of vertices (nodes), and E V x V is a set of edges (arcs) • G can b directed or undirected • Additional information can be present on vertices and/or edges: weight, label, timestamp, probability of existence, feature vector, … Graphs are ubiquitous • Computational biology • Protein-protein interaction (PPI) networks • Chemical data analysis • Chemical compounds • Communication networking • Device networks, road networks • Social network analysis • Web link analysis • Recommender systems Mining graph data: Tasks • Graph clustering • Graph search • Dense-subgraph extraction • Graph classification • Graph pattern mining • Graph matching • Graph querying • Influence maximization •… Graph clustering • Partition the input graph in order to maximize some notion of density • Notions of density: • Average degree • Ratio cut • Normalized cut • Conductance • (Quasi-)clique condition •… • Applications • Community detection in a social network • Identifying high-cohesive structures in biological networks • Packet delivery on communication networks • Detecting highly-correlated stocks • ... Graph search • Given a set of graphs {G1, ... , Gn}, and a graph query Q, find all graphs in {G1, ... , Gn} that are supergraphs of Q • Applications • Chemical compound search • Molecules represented in terms of atoms and bonds between atoms • Context-based image retrieval • Images represented in terms of object properties and relationships between objects • 3D protein structure search • Proteins represented as a set of amino acids related to each other Thanks! [email protected] 30 Backup slides Association-rule discovery: Application 2 Prediction of drug side effects • Goal: detect combinations of drugs that result in particular side-effects • Approach: • Model each patient as a record of two types of items: items representing drugs taken and items representing side effects observed • Employ an association-rule-discovery method to detect rules like: {Marijuana, Heroin} {Depressed respiration} • Use the rules discovered for early diagnoses Mining graph data: Challenges • Small-dimensional graphs, but lots of graphs • Chemical data graphs • Small number of graphs, but huge dimensionality • Social networks, the Web • Dynamic graphs (i.e., graphs changing over time) • PPI networks • Time-dependent graphs • Road networks Classification: Application 1 Direct marketing • Goal: Reduce cost of mailing by targeting a set of consumers likely to buy a new cell-phone product • Approach: • Use past data from a (set of) similar product(s) introduced before • Consider the information about which customers bought and which customers did not. This {buy, don’t buy} decision forms the class attribute • Describe each customer according to several other attributes, such as demographic, lifestyle, company-interaction information and so on • Use this information to train a classifier that can be used to infer the {buy, don’t buy} class of the various customers for the new product