Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
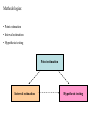
Statistical inference General objective: To draw conclusions about the population of study from observations (a sample) obtained from the population. Probability theory Population Sample Statistical inference Methodologies: • Point estimation • Interval estimation • Hypothesis testing Point estimation Interval estimation Hypothesis testing Point estimation: General objective: To find approximations to the unknown values of one ore more parameters of the population Embedded parts: An approximate value is calculated from the obtained observations. Obtained observations are randomly drawn from the population The current approximate value is “randomly drawn” from the set of all possible approximate values (values from all possible sets of observations) The approximate value is an outcome of a stochastic point estimator. This stochastic point estimator has a probability distribution induced by the population of study and the method of sampling, a so-called sampling distribution. Properties of the point estimator can be investigated and compared between different “competitors” using this sampling distribution.: • Unbiasedness • Consistency • Efficiency • Sufficiency • Completeness Different systematic methods can be derived to find point estimators, sometimes fulfilling certain optimality criteria. • Maximum Likelihood Method • Method of Moments • Least-Squares Method Interval estimation: General objective: To find a numerical interval or set (ellipsoid, hyper-ellipsoid) to which the unknown value of a parameter (one- or multidimensional) belongs with a certain degree of confidence (security) More common term: Confidence intervals (sets) Construction of confidence intervals is done by using a so-called statistic calculated from the observations (the sample). Like a point estimator, a statistic has a sampling distribution depending on the unknown parameter value. The sampling distribution is used to find an interval of parameter values that to a certain (high) probability is consistent with the observed value of the statistic. Hypothesis testing: General objective: To formulate and test statements about • the values of one or more parameters of the population • relationships between corresponding parameters of different populations • other properties of the probability distribution(s) of the values of the population(s) Methodology: Investigation of the consistency between a certain statement and the observed values in the sample (sometimes through a computed confidence interval) Embedded methodology: There are different alternatives for the test of one statement Properties of different tests need to be investigated (power, unbiasedness, consistency, efficiency, invariance,…) Outline of the course: Preliminary Work plan (Course web page) Week Moment Sections in textbook Chapter 2 Recommended exercises 843 Point estimation, Properties of estimators 844 Maximum Likelihood estimation, Moment estimation and LeastSquares estimation Hypothesis testing and Interval estimation Chapter 3 846 The decision-theoretic approach Chapter 6 847 Bayesian inference Chapter 7 848 Non-parametric inference Chapter 8 849 Computer-intensive methods Generalized linear models Chapter 9 4.1, 4.2, 4.3, 4.5, 4.6, 4.10, 4.12, 4.14, 4.17, 4.18, 4.20, 5.1, 5.3, 5.4, 5.6, 5.7, 5.10, 5.13, 5.14, 5.18 6.1, 6.2, 6.4, 6.5, 6.7, 6.8, 6.10, 6.12, 6.15, 6.17, 6.18, 6.21, 6.24, 6.26, 6.30 7.1, 7.2, 7.3, 7.5, 7.7, 7.9, 7.11, 7.13, 7.15, 7.16, 7.18, 7.19, 7.22, 7.28, 7.30, 7.33, 7.35 8.1, 8.2, 8.3, 8.4, 8.5, 8.6, 8.7, 8.8, 8.9, 8.10, 8.12, 8.14, 8.15, 8.16, 8.18, 8.20, 8.22, 8.23, 8.26 To be announced later Chapter 10 10.1, 10.2, 10.3, 10.4, 10.7 845 850 Chapter 4, 5 2.1, 2.2, 2.3, 2.4, 2.6, 2.8, 2.10, 2.13, 2.14, 2.16, 2.18, 2.19, 2.20, 2.21, 2.22, 2.24, 2.27 3.1, 3.2, 3.3, 3.5, 3.7, 3.10, 3.12, 3.14, 3.18, 3.21, 3.23, 3.25, 3.27, 3.28. 3.29, 3.30, Teaching and examination: • Weekly meetings (1 or 2) consisting of lectures and problem seminars • Lectures: Summaries of the moments covered by the corresponding week • Problem seminars: Solutions to selected exercises presented on the white board by students and/or teacher • The students will each week be given a number of exercises to work with. At the problem seminars students are expected to attempt to present solutions on the white board. Upon completing the course every student should have presented at least one solution. Each student should in addition submit written solutions to a number of exercises selected by the teacher from week to week. • The course is ended by a written home exam. Some practical points: • The teacher (Anders Nordgaard) works only part-time at the university and is under normal circumstances present on Thursdays and Fridays (with exception for scheduled classes and meetings that can be read on the door sign) • The easiest way to contact the teacher is by e-mail: [email protected] • E-mail is read all working days of a week (including Monday-Wednesday) • Written solutions to exercises should be submitted either directly at a meeting or electronically by e-mail • The timetable for meetings will be decided successively along the period of the course and published on the course web page • Lectures will by no means cover all necessary details of the course. It will not be sufficient to read the lecture notes for success at the final exam. The course book (or a textbook covering the same topics) is necessary. Some basic concept from inference theory: A population is the group of elements under study. In more detail it is the set of all possible values of a certain property/feature. The more stochastic description of a population is the following: Consider the case were one single element is drawn from the population. Denote its value by X. X is then a random variable with a probability distribution corresponding with how common each unique value is in the population. A population may be • finite Contains a limited number of values although duplicates are possible • countable infinite Contains an infinite number of values but the numbers are enumerable. • uncountable infinite Contains an infinite number of non-enumerable values. The values vary continuosly. A random sample is a set of n values drawn from the population. x1, … , xn General case: Population is infinite (or drawing is with replacement). Each value in the sample is an outcome of a particular random variable. The random variables X1, … , Xn are independent with identical probability distribution. Special case: Population is finite (and drawing is without replacement). Each value in the sample is an outcome of a particular random variable but the random variables X1, … , Xn are non-independent and with different probability distributions. Detailed theory about this case may be find in higher-level textbooks on survey sampling and it will not be covered by this course. The population is usually characterized by a parameter, generically denoted by (very often one-dimensional but multi-dimensional cases will also be treated) In a particular population, the parameter is fixed. Typical examples of population parameters are: The mean The variance 2 The parameters are at the same time parameters of the corresponding probability distribution, where we can find more, less physically interpretable parameters. E.g. N(, 2) Normal distribution B(n, p ) or Bi(n, p) Binomial distribution P( ) or Po ( ) Poisson distribution U(a, b ) Uniform distribution The sample can similarly be characterized by a statistic (one- or multidimensional) In a particular sample the statistic is fixed E.g. Sample mean 1 n x xi n 1 xi n i 1 Sample variance s 2 n 11 xi x 2 In the theoretical investigation of statistics and their properties we will always consider a particular statistic as a random variable as it is a function of the observations of a sample which in turn are outcomes of individuals random variables. 1 n X X i n 1 X i n i 1 s 2 n 11 X i X 2 Generally we may denote a statistic by T. Considering the statistic as a numerical value based on the values of the sample it can be written as a function of the sample values: T = T (x1, … , xn ) Considering the statistic as a random variable we just replace the values in the argument of with their random variable counterparts: T = T (X1, … , Xn ) The so-induced probability distribution of T is called the sampling distribution of the statistic. A specific statistic is the order statistic: T = ( X(1), … , X(n) ) Where X(1) depicts the lowest value of the sample, X(2) the second lowest etc. Note that we need n dimensions to fully represent this statistic. The likelihood function The probability distribution of each of the random variables in a sample is characterized by • the probability mass function Pr(X = x ) if the random variable is discrete (i.e. the population is countable infinite) • the probability density function f (x) if the random variable is continuous (i.e. the population is uncountable infinite) Throughout the course (and the textbook) we will use the term probability density function (abbreviated p.d.f.) for both functions and it should be obvious when this p.d.f. in fact is a probability mass function. We will sometimes also need the cumulative probability distribution function: F(x ) = Pr(X x ) which has the same defintion no matter if the random variable is discrete or continuos. It is abbreviated c.d.f. As the probability distribution will depend on the unknown parameter we will write f (x; ) for the p.d.f. and F(x; ) for the c.d.f The likelihood function obtained from a sample x = (x1, ,,, , xn) is defined as n L ; x f xi ; f x1; f xn ; i 1 i.e. the product of the p.d.f. evaluated in all sample values. Note that this is considered to be a function of the parameter and not of the sample values. Those are in a particular sample considered to be known. The likelihood function is related to how probable the current sample is, and with discrete random variables it is exactly the probability of the sample. For analytical purposes it is often more convenient to work the natural logarithm of L, i.e. n l ; x ln L ; x ln f xi ; i 1 As f(x; ) > 0 for all possible sample values and the log transformation is one-to-one the two functions are equivalent from an information point-of-view. Point estimation Assume a random sample x =(x1, … , xn) from a population (distribution) with probability density function (p.d.f) f (x; ) We search for a function of the sample values that is a (good) approximation to the unknown value of . Assume ˆ ˆx1,, xn is such a function. ˆ is called the point estimate of ˆx1,, xn is the (numerical ) value θˆ X1,, X n is the correspond ing random variable , the point estimator The point estimator has a probability distribution induced by the sampling (and the probability distribution of the sample values) Referred to as the sampling distribution. Measures of location and dispersion of the point estimator are of particular interest, e.g. E ˆ , Var ˆ By investigating such measures and more generally the sampling distribution, certain properties of a point estimator may be obtained. Unbiasedness The bias of a point estimator measures its mean deviation from . bias ˆ E ˆ If bias ˆ 0, ˆ is said to be unbiased Consistency If for any 0 Pr ˆ 0 as n ˆ is said to be consistent