Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
R ESEARCH F E AT UR E
Using Data Mining
Methods to Build
Customer Profiles
The 1:1Pro system constructs personal profiles based on customers’
transactional histories. The system uses data mining techniques to
discover a set of rules describing customers’ behavior and supports
human experts in validating the rules.
Gediminas
Adomavicius
Alexander
Tuzhilin
New York
University
74
ersonalization—the ability to provide content
and services tailored to individuals on the
basis of knowledge about their preferences
and behavior1—has become an important
marketing tool (see the “Personalization”
sidebar). Personalization applications range from personalized Web content presentations to book, CD, and
stock purchase recommendations. Among issues the
personalization community must deal with, the following are of special importance: how to provide personal recommendations based on a comprehensive
knowledge of who customers are, how they behave,
and how similar they are to other customers; and how
to extract this knowledge from the available data and
store it in customer profiles.
Various recommender systems address the recommendation problem.2 Most use either the collaborative-filtering3-5 or the content-based6 approach (see
sidebar). Some systems integrate the two methods.2,6
To address the second issue, we have developed an
approach that uses information learned from customers’ transactional histories to construct accurate,
comprehensive individual profiles.7 One part of the
profile contains facts about a customer, and the other
part contains rules describing that customer’s behavior. We use data mining methods to derive the behavioral rules from the data. We have also developed a
method for validating customer profiles with the help
of a human domain expert who uses validation operators to separate “good” rules from “bad.” We have
implemented the profile construction and validation
methods in a system called 1:1Pro. Our approach differs from other profiling methods in that we include
personal behavioral rules in customer profiles.7
We can judge the quality of rules stored in customer
profiles in several ways. We might call rules “good”
P
Computer
because they are statistically valid, acceptable to a
human expert in a given application, or effective in
that they result in specific benefits such as better decision-making and recommendation capabilities. Here,
we focus on the first two aspects: statistical validity
and acceptability to an expert.
BUILDING CUSTOMER PROFILES
As Figure 1 illustrates, the two main phases of the
profile-building process are rule discovery and validation. Our method of building personalized customer
profiles begins with collecting the data.
Data model
Applications use various kinds of data about individual customers. Many applications classify the data
into two basic types: factual—who the customer is—
and transactional—what the customer does.
For example, in a marketing application based on
customers’ purchasing histories, the factual data
includes demographic information such as name, gender, birth date, address, salary, and social security number. Transactional data consists of records of the
customer’s purchases during a specific period. A purchase record might include the purchase date, product purchased, amount paid, coupon use, coupon
value, and discount applied. Figure 2 shows examples
of factual and transactional data.
Profile model
A complete customer profile has two parts: factual
and behavioral. The factual profile contains information, such as name, gender, and date of birth, that
the personalization system obtained from the customer’s factual data. The factual profile also can contain information derived from the transactional data,
0018-9162/01/$10.00 © 2001 IEEE
such as “The customer’s favorite beer is Heineken”
or “The customer’s biggest purchase last month was
for $237.”
A behavioral profile models the customer’s actions
and is usually derived from transactional data.
Examples of behaviors are “When purchasing cereal,
John Doe usually buys milk” and “On weekends, John
Doe usually spends more than $100 on groceries.”
RULE DISCOVERY
We model individual customer behavior with various types of conjunctive rules, including association8
and classification rules.9 Figure 3 shows an example of
association rules discovered for a particular customer.
For instance, Rule 1 specifies that John Doe usually
buys lemon juice at RiteAid. More specifically, in 95
percent of the cases when he buys lemon juice, he buys
it at RiteAid. In addition, 2.4 percent of all John Doe’s
shopping transactions include purchasing lemon juice
at RiteAid.
Using rules to describe customer behavior has cer-
Factual
Phase 1
Data
Phase 2
Rules
Data mining
Profiles
Validation
tain advantages. Besides being an intuitive and descriptive way to represent behaviors, a conjunctive
rule is a well-studied concept used extensively in data
mining, expert systems, logic programming, and
many other areas. Moreover, researchers have proposed many rule discovery algorithms in the literature, especially for association and classification rules.
For personalization applications, we apply rule discovery methods individually to every customer’s data.
To discover rules that describe the behavior of individual customers, we can use various data mining algorithms, such as Apriori8 for association rules and CART
(Classification and Regression Trees)9 for classification
rules. Moreover, our profiling approach is not limited
CustomerId
LastName
FirstName
BirthDate
Gender
0721134
0721168
0730021
Doe
Brown
Adams
John
Jane
Robert
11/17/1945
05/20/1963
06/02/1959
Male
Female
Male
Time
Store
Product
10:18am
10:18am
10:29am
07:02pm
08:34pm
08:34pm
01:13pm
01:13pm
GrandUnion
GrandUnion
Edwards
RiteAid
Edwards
Edwards
GrandUnion
GrandUnion
WheatBread
AppleJuice
SourCream
LemonJuice
SkimMilk
AppleJuice
BabyDiapers
WheatBread
Transactional CustomerId Date
0721134
0721134
0721168
0721134
0730021
0730021
0721168
0730021
07/09/1993
07/09/1993
07/10/1993
07/10/1993
07/10/1993
07/10/1993
07/12/1993
07/12/1993
Figure 1. A simplified
view of the profilebuilding process.
CouponUsed
No
Yes
No
No
No
No
Yes
No
Figure 2. Fragments of data in a marketing application showing demographic information (factual data) and records of the customers’ purchases (transactional data).
Discovered rules
(for John Doe)
(1) Product = LemonJuice => Store = RiteAid (2.4%, 95%)
(2) Product = WheatBread => Store = GrandUnion (3%, 88%)
(3) Product = AppleJuice => CouponUsed = YES (2%, 60%)
(4) TimeOfDay = Morning => DayOfWeek = Saturday (4%, 77%)
(5) TimeOfWeek = Weekend & Product = OrangeJuice => Quantity = Big (2%, 75%)
(6) Product = BabyDiapers => DayOfWeek = Monday (0.8%, 61%)
(7) Product = BabyDiapers & CouponUsed = YES => Quantity = Big (2.5%, 67%)
Figure 3. Association rules discovered in a marketing application help to describe the customer’s behavior.
February 2001
75
Personalization
Personalization is a relatively new field,
and different authors provide various definitions of the concept.1 We define personalization as an iterative process consisting of the steps shown in Figure A.
Collecting Customer Data
Personalization begins with collecting
customer data from various sources. This
data might include histories of customers’
Web purchasing and browsing activities,
as well as demographic and psychographic information. After the data is collected, it must be prepared, cleaned, and
stored in a data warehouse.2
Customer Profiling
A key issue in developing personalization applications is constructing accurate
and comprehensive customer profiles
based on the collected data.
Matchmaking
Personalization systems must match
appropriate content and services to indi-
Measuring
customer response
Delivery and presentation
of personalized information
Matchmaking
Building
customer profiles
Collecting
customer data
Figure A. Stages of the personalization
process. Customer response measurements
provide feedback to each of the previous
stages.
76
Computer
vidual customers. This matchmaking
takes various approaches. For example,
BroadVision (http://www.broadvision.
com) and Art Technology Group (http://
www.atg.com) use business rules to specify what content to deliver in particular
situations. To provide personalized recommendations, recommender systems use
technologies such as content-based and
collaborative filtering. Content-based systems recommend items similar to items
the customer preferred in the past. Collaborative-filtering systems recommend
items that other customers with similar
tastes and preferences liked in the past.
Delivery and Presentation
E-companies deliver personalized information to customers in several ways. One
classification of delivery methods is pull,
push, and passive.3 Push methods reach a
customer who is not currently interacting
with the system—for example, by sending
an e-mail message. Pull methods notify
customers that personalized information
is available but display this information
only when the customer explicitly requests
it. Passive delivery displays personalized
information in the context of the e-commerce application. For example, while
looking at a product on a Web site, a customer also sees recommendations for
related products. The system can present
personalized information in various forms:
narrative, a list ordered by relevance, an
unordered list of alternatives, or various
types of visualization.3
Measuring Customer Response
Companies can use various “e-metrics”
to evaluate the effectiveness of personalization technologies.4 For example, an ecommerce company can determine
whether customers start spending more
time (and money) on its Web site, whether
personalized services attract new customers, and whether customer loyalty
increases.
As Figure A shows, measuring customer response serves as feedback for possible improvements of each of the other
four steps of the personalization process.
In particular, system designers should use
customer response to decide whether to
collect additional data, build better user
profiles, develop better matchmaking
algorithms, and improve information presentation. If organized properly, this iterative process improves relationships with
customers over time by providing a better
understanding of customers, more accurately targeted content, and better recommendations and services.
Implementation Issues
To implement the personalization
process properly, companies must deal
with several issues. Privacy is a big concern to customers, and companies must
reconcile their personalization systems
with this concern. Progress in privacy
preservation will be critical to personalization. Scalability of the personalization
process is another important issue—many
growing companies must be ready to handle millions of customers and tens of
thousands of products. Moreover, providing personalized services in real time
requires efficient profiling and matchmaking methods.
Personalization is a broad field, and
many companies focus only on certain
steps of the process. Overviews of most of
the personalization companies are available at http://www.personalization.com
and http://www.personalization.org.
References
1. Comm. ACM, Special Issue on Personalization, vol. 43, no. 8, 2000.
2. D. Pyle, Data Preparation for Data Mining, Morgan Kaufmann, San Francisco,
1999.
3. J.B. Schafer, J.A. Konstan, and J. Riedl,
“E-Commerce Recommendation Applications,” J. Data Mining and Knowledge
Discovery, Jan. 2001.
4. M. Cutler and J. Sterne, “E-Metrics,”
NetGenesis Corp., 2000; http://www.
netgen.com/emetrics/.
Individual Individual
data
rules
Individual
profiles
Discarded
rules
Rejected
All
rules
Validation
operator +
expert
Accepted
Accepted
rules
Undecided
Phase 1
data mining
Phase 2
validation
Figure 4. An expanded view of the profile-building process. Rule validation is an iterative process in which the expert applies various operators successively to validate rules.
to any specific representation of data mining rules or
discovery method.
Because data mining methods discover rules for
each customer individually, these methods work well
for applications containing many transactions for
each customer, such as credit card, grocery shopping,
online browsing, and stock trading applications. In
applications such as a car purchase or vacation planning, individual rules tend to be statistically less reliable because they are generated from relatively few
transactions.
RULE VALIDATION
Data mining methods often generate large numbers
of rules, many of which, although statistically acceptable, are trivial, spurious, or just not relevant to the
application at hand.10,11 Therefore, validating the discovered rules is an important requirement. For example, assume that a data mining method discovers the
rule that whenever John Doe takes a business trip to
Los Angeles, he stays in an expensive hotel. Assume
that John went to Los Angeles seven times over the
past two years, and five of those times he stayed in
expensive hotels. We must validate this rule—that is,
make sure that it captures John’s behavior rather than
a spurious correlation and that it is not simply irrelevant to the application.
One way to validate discovered rules is to let a
domain expert inspect them and decide how well they
represent customers’ actual behaviors. The expert
accepts some rules and rejects the others, and the
accepted rules form the behavioral profiles.
An important issue in validating rules is scalability.
In many personalization applications, the number of
customers is very large. For example, in a credit-card
application, the number of customers can be measured
in millions. If we discover 100 rules per customer on
average, the total number of rules in that application
would be hundreds of millions. It is simply impossible for a human expert to validate all these rules one
by one.
To address this problem, our system uses validation
operators that let a human expert validate large numbers of rules at a time with relatively little input from
the expert. As Figure 4 shows, rule validation is an
iterative process that lets the expert apply various
operators successively and validate many rules each
time an operator is applied.
The profile-building process in Figure 4 consists of
two phases. Phase 1, data mining, generates rules for
each customer from the customer’s transactional data.
Phase 2 constitutes the rule validation process performed by the domain expert.
Rule validation, unlike rule discovery, is not a separate process for each customer, but takes place for
all customers at once. As a result, the expert usually
validates many similar or even identical rules for different customers. For example, the rule “When buying cereal, John Doe also buys milk” might be
common to many customers. Similarly, the rule
“When shopping on weekends, John Doe usually
spends more than $100 on groceries” might be common to many customers with big families. Collective
rule validation lets the expert deal with such common
rules just once. On the other hand, separate rule validation for each customer would force the expert to
work on many identical or similar rules repeatedly.
Therefore, at the beginning of Phase 2, the system collects rules from all the customers into one set and tags
each rule with the ID of the customer to which it
February 2001
77
Input:
Set of all discovered rules Rall .
Output: Mutually disjoint sets of rules Racc , Rrej , Runv ,
such that Rall = Racc ∪ Rrej ∪ Runv.
(1)
(2)
(3)
(4)
(5)
(6)
Runv := Rall , Racc := ∅ , Rrej := ∅ .
while (not TerminateValidationProcess()) begin
Expert picks a validation operator (say, O) from the set of
available validation operators.
O is applied to Runv . Result: disjoint sets Oacc and Orej .
Runv := Runv − Oacc − Orej , Racc := Racc ∪ Oacc , Rrej := Rrej ∪ Orej .
end
Figure 5. Basic algorithm for the rule validation process. Applying each validation operator results in the acceptance of some
rules and the rejection of others until the TerminateValidationProcess condition is met.
belongs. After validation, the system places each
accepted rule in that customer’s profile.
Figure 5 describes the rule validation process. All
rules discovered during Phase 1 (denoted Rall in the figure) are considered unvalidated. The expert chooses
various validation operators and applies them successively to the set of unvalidated rules. Applying each validation operator results in the acceptance of some rules
(set Oacc) and the rejection of others (Orej). The expert
then applies the next validation operator to the set of
remaining unvalidated rules (Runv). The process stops
when the TerminateValidationProcess condition is met.
After the validation process, the set of all discovered rules (Rall) is split into three mutually disjoint sets:
accepted rules (Racc), rejected rules (Rrej), and possibly some remaining unvalidated rules (Runv). At the
end of Phase 2, all accepted rules are placed in the
behavioral profiles of their respective customers.
VALIDATION OPERATORS
We have developed several validation operators that
a human expert can use to validate large numbers of
rules.7
Similarity-based rule grouping
This operator puts similar rules into groups according to expert-specified similarity criteria. As a result,
the expert can inspect groups of rules instead of individual rules one by one, and can accept or reject all
rules in the group at once. We developed a method the
expert can use to specify different levels of rule similarity. We also developed an efficient (linear running
time) rule-grouping algorithm.7
For example, according to the attribute structure
similarity condition, all rules that have the same
attribute structure (ignoring attribute values and statistical parameters) are similar. Consider the rules in
Figure 3. Under the attribute structure similarity condition, the grouping operator would place rules 1 and
2 in the same group because they both have the
78
Computer
attribute structure Product => Store. Consequently,
any rule with such an attribute structure would be
placed in the same group as rules 1 and 2. Rule 3,
however, would not be grouped with rules 1 and 2
because it has a different attribute structure: Product
=> CouponUsed. Attribute structure is only one of
many possible similarity conditions that the similaritybased rule-grouping operator can use.
Template-based rule filtering
This operator filters rules that match expert-specified rule templates. The expert specifies accepting
and rejecting templates. Naturally, rules that match
an accepting template are accepted; rules that match
a rejecting template are rejected. Rules that do not
match a template remain unvalidated. For this operator, we developed a rule-template specification language and an efficient (linear running time) matching
algorithm.
Consider the following rule template: REJECT
HEAD = {Store = RiteAid}. This template means
“Reject all rules that have Store = RiteAid in their
heads.” Of the seven rules in Figure 3, only rule 1
matches this template and, as a result, would be
rejected. A more complicated rule template is ACCEPT
BODY ⊇ {Product} AND HEAD {DayOfWeek,
Quantity}. This rule means “Accept all rules that have
the attribute Product (possibly among other attributes)
in their bodies, that also have heads restricted to the
attributes DayOfWeek or Quantity.” In Figure 3, rules
5 and 7 match this template and would be accepted
and placed in the profile.
Redundant-rule elimination
This operator eliminates rules that can be derived
from other, usually more general, rules and facts. In
other words, it eliminates rules that by themselves
carry no new information about a customer’s behavior. The operator incorporates an algorithm that
checks rules for certain redundancy conditions.7
1:1Pro server
Database interface
Validation
Data mining
interface
1:1Pro client
GUI
Coordination
Other
interfaces
Communications
Communications
DBMS
Data mining
tools
Visualization
tools
Statisticalanalysis tools
Network (LAN, WAN, Internet)
Figure 6. The 1:1Pro system architecture. 1:1Pro is an open system that incorporates a broad range of data sources as well as
data mining, visualization, and statistical-analysis tools.
Consider the association rule Product = AppleJuice
=> Store = GrandUnion (2%, 100%), which was discovered in the purchasing history of John Doe. This
rule by itself might seem to show the specifics of Doe’s
behavior (he buys apple juice only at Grand Union),
so putting this rule in his behavioral profile might seem
logical. Assume, however, that we also determined
from the data that this customer shops exclusively at
Grand Union. The AppleJuice rule constitutes a special case of this finding. Therefore, keeping the fact
“The customer shops only at Grand Union” in John
Doe’s factual profile eliminates the need to store the
AppleJuice rule in the profile.
In addition to these three operators, we have also
introduced other validation operators, such as visualization, statistical analysis, and browsing.7 The visualization operator lets the expert view subsets of
unvalidated rules in visual representations such as histograms and pie charts. The statistical-analysis operator
computes various statistical characteristics of unvalidated rules, thus providing the expert with important
information to use during validation. The browsing
operator allows the expert to inspect individual rules or
groups of rules directly by viewing them on the screen.
As Figure 5 shows, the expert successively applies
validation operators to the set of unvalidated rules
until the process reaches the stopping criterion
TerminateValidationProcess. The expert can specify
this criterion in several ways. The following are two
examples of stopping criteria:
• The validation process continues until some predetermined percentage of rules (such as 95 percent) is validated.
• The validation process terminates when valida-
tion operators validate only a few rules at a
time—that is, when the costs of selecting and
applying each additional validation operator
exceed the benefits of validating a few more rules
(the law of diminishing returns).
THE 1:1PRO SYSTEM
The 1:1Pro (short for One-to-One Profiling) system
implements our profiling and validation methods. The
system takes as input the factual and transactional data
stored in a database or flat files and generates a set of
validated rules capturing individual customers’ behavior. It can use any relational database management system (DBMS) to store customer data and various data
mining tools to discover rules. In addition, it can incorporate other tools useful in the rule validation process,
such as visualization and statistical-analysis tools that
the validation operators may require.
The 1:1Pro system architecture, shown in Figure 6,
follows the client-server model. The server component consists of the following modules:
• Coordination module—coordinates profile construction, including the rule generation process
and the subsequent validation process.
• Validation module—validates the rules discovered by data mining tools. The system’s current
implementation supports similarity-based grouping, template-based filtering, redundant-rule
elimination, and browsing operators.
• Communications module—handles all communications with the 1:1Pro client.
• Interfaces to external modules such as a DBMS,
data mining tools, and visualization tools. Each
module requires a separate interface (Figure 6).
February 2001
79
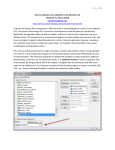
Figure 7. Graphical user interface window for a filtering operator. The expert uses the GUI to specify validation operations and
view the results of the iterative validation process.
ResultId
...
6
7
8
9
...
Operator
...
Filter
Group
Browse
Filter
...
SourceId
...
5
3
7
3
...
Date/Time
...
11/23/1998 5:26pm
11/23/1998 5:37pm
11/23/1998 5:51pm
11/23/1998 6:28pm
...
Notes
...
Rejecting: demogr. in the body
Used attribute-level setting here
Accepted: 7 groups, rejected: 11
Rejecting: ‘age’ in the head
...
Figure 8. A 1:1Pro system log file fragment. The log file captures the entire validation process, allowing the expert to keep
track of all validation activities.
The client component contains the graphical
user interface and the communications modules.
The expert uses the GUI to specify validation operations and view the results of the iterative validation process. Figure 7 shows an example of the
GUI window for the template-based filtering operator.
The client communication module sends the
expert-specified validation request to the server. The
server receives validation operators and passes them
through the coordination module to the validation
component for subsequent processing. Some validation operators, such as the statistical-analysis operator, generate outputs. The communications modules
send these outputs from the validation module to the
GUI module.
We wanted 1:1Pro to be an open system that easily
incorporates a broad range of data sources as well as
data mining, visualization, and statistical-analysis
tools. In particular, we designed a database interface
that supports relational databases (such as Oracle and
SQL Server), flat files, and Web logs, as well as other
data sources.
In 1:1Pro’s current implementation, we used association rule discovery methods to build customer
profiles. However, our methods are not restricted to
a particular rule structure or discovery algorithm.
We can plug in commercial and experimental data
mining tools that use methods other than association
rule discovery, such as decision tree methods.9 One
problem with using external data mining tools is that
80
Computer
their rule representation formats differ from ours.
We overcame this problem by developing rule converters for the external data mining tools that interface with 1:1Pro.
The expert specifies validation operators through
the GUI module, and a log file records the operators
as they are applied. Figure 8 shows the log file structure. The log file captures the entire validation process,
allowing the expert to keep track of all validation
activities. The expert can also retrace validation steps
that were not useful by selecting a validation operator
in the log file and running the process forward from
that operator on. The major fields in the log file record
are
• ResultId—the instance of the validation operator used in the current validation step,
• Operator—this operator’s type (grouping, browsing, filtering),
• SourceId —the instance of the previously applied
validation operator,
• Date/Time—the time stamp when the validation
operator was created, and
• Notes—the domain expert’s comments.
The 1:1Pro system’s server component, implemented in C++ and Perl, runs on a Linux or Unix platform. The client component, implemented in Java, can
run on the same machine as the server or on a different machine. It can also run from an applet viewer or
as a stand-alone application.
Table 1. A validation process for the seasonality analysis of market research
data.
Validation
operator
EXPERIMENTS
We tested 1:1Pro on a real-world marketing application that included data on 1,903 households purchasing various nonalcoholic beverages over a
one-year period. The data set contained 21 fields
characterizing the purchase transactions and 353,421
records (on average, 186 records per household).
In our case study, we performed a seasonality analysis. That is, we constructed customer profiles containing individual rules describing season-related
customer behaviors. For example, such rules might
describe the types of products a customer buys under
specific temporal circumstances (only in winter, only
on weekends) or the temporal circumstances under
which a customer buys specific products.
The system’s data mining module generated
1,022,812 association rules—on average, about 537
rules per household. We observed that most rules pertain to a very small number of households. For example, nearly 40 percent of the 407,716 discovered rules
pertain to five or fewer of the 1,903 households. Of
that 40 percent, nearly half (196,384 rules) apply to
only one household. This demonstrates that many discovered rules capture truly idiosyncratic behavior of
individual households. Because the traditional segmentation-based approaches to building customer
profiles do not capture idiosyncratic behavior, they
would not identify many of the rules discovered in our
application. On the other extreme, several discovered
rules were applicable to a significant portion of the
households. For example, nine rules pertained to more
than 800 households. In particular, DayOfWeek=
Monday => Shopper=Female was applicable to 859
households.
Because we were familiar with this application, we
performed the expert’s role and validated the discovered rules ourselves. Table 1 summarizes the validation
process. We started by eliminating redundant rules
and then applied several filtering operators, most of
which were rule elimination filters. Eliminating redundant rules and repeatedly applying rule filters helped
us validate 93.4 percent of the rules.
After validating a large number of rules with relatively few filtering operators, we decided to switch
to a different validation approach—applying the
grouping operator to the remaining unvalidated rules.
The grouping operator generated 652 groups. Then,
we examined several of the largest groups and validated their rules. As a result, we managed to validate
all but 37,370 rules. We then applied a grouping operator based on a different rule structure to these
remaining rules and validated a set of additional
8,714 rules. At this point, we encountered the law of
diminishing returns—each subsequent application of
a validation operator validated a smaller number of
rules—and we stopped the validation process. It took
Accepted
rules
Rejected
rules
Unvalidated
rules
Redundancy elimination
Filtering
Filtering
Filtering
Filtering
Grouping (652 groups)
Grouping (4,765 groups)
0
0
0
0
10,052
23,417
7,181
186,727
285,528
424,214
48,682
0
6,822
1,533
836,085
550,557
126,343
77,661
67,609
37,370
28,656
Total
40,650
953,506
1,724,281
us one hour to perform the whole process (including
the software running time and the expert validation
time). We validated 97.2 percent of the rules—4.0
percent were accepted and 93.2 percent rejected. Our
results demonstrate that our system can validate a
significant number of rules in medium-size personalization applications.
As a result of the validation process, we reduced
the average customer profile size from 537 unvalidated rules to 21 accepted rules. An example of an
accepted rule for one household is Product=
FrozenYogurt & Season=Winter => CouponUsed=
YES—in other words, during the winter, this household buys frozen yogurt, mostly using coupons. We
accepted this rule because it reflects an interesting seasonal coupon-use pattern. A rejected rule for one
household is Product=Beer => Shopper=Male—the
predominant beer buyer in this household is male.
We rejected this rule because it is unrelated to the seasonality analysis.
Because we had performed the validation process
ourselves in the previous case study, we decided to use
the help of a marketing expert in another seasonality
analysis of the same data. The expert started the
analysis by applying redundant-rule elimination and
several template-based filtering rejection operators
(for example, operators that reject all rules not referring to the Season or DayOfWeek attributes). Then,
she grouped the remaining unvalidated rules, examined several resulting groups, and stopped the validation process. At that point, she found nothing more to
reject and decided to accept all the remaining unvalidated rules. As a result, she accepted 42,496 rules (4.2
percent of all discovered rules) and spent about 40
minutes on the entire process.
The marketing expert noted that our rule evaluation process is inherently subjective because different
experts have different experiences and understandings of the application. She believes that different
experts can arrive at different evaluation results using
the same validation process.
e must point out that the accepted rules,
although valid and relevant to the expert,
may not be effective. That is, they might not
guarantee actionable results, such as decisions, rec-
W
February 2001
81
ommendations, and other user-related actions. We
are currently working on incorporating the concept
of effectiveness in 1:1Pro.
We are also dealing with the problem of generating
many irrelevant rules that are subsequently rejected
during the validation process. One way to handle the
problem is for the domain expert to specify constraints
on the types of rules of interest before the rule discovery stage. Ramakrishnan Srikant, Quoc Vu, and
Rakesh Agrawal have presented methods for specifying such constraints,12 and thus reducing the number
of discovered rules that are irrelevant to the expert.
Since it is difficult for an expert to anticipate all the
relevant and irrelevant rules in advance, validating the
discovered rules is still necessary. Thus, the ideal solution is to combine the constraint specification, data
mining, and rule validation stages in one system. We
are currently working on integrating the three stages
in 1:1Pro. ✸
References
1. P. Hagen, “Smart Personalization,” The Forrester
Report, Forrester Research, Cambridge, Mass., July
1999.
2001
EDITORIAL CALENDAR
IT Professional is looking for contributions about the following cover
feature topics for 2001:
Mar./Apr. The Paperless Environment
Faster and increasingly powerful networks are making it easy
to pass documents back and forth electronically. But security
and authentication remain a concern for commercial companies
and governments alike.
Find out how banks, courts, and others are using encryption,
and electronic documents and signatures.
May/June Wireless
A bewildering array of wireless technologies—Bluetooth
and WAP among them—are making inroads into corporate
communications. Making it all work together with existing
systems is IT’s headache, but will be a boon to global
communications and a company’s competitive edge.
July/Aug. IT Projections and Market Models
Reinventing the wheel is never fun, yet IT departments do it
every time they make projections for manpower, project
costs, and future technologies. Find out what data and tools
to avoid reading “data analysis” use to look beyond the
next week’s work to make strategic calls.
82
Computer
2. Comm. ACM, Special Issue on Recommender Systems,
vol. 40, no. 3, 1997.
3. P. Resnick et al., “GroupLens: An Open Architecture for
Collaborative Filtering of Netnews,” Proc. 1994 Computer-Supported Cooperative Work Conf., ACM Press,
New York, 1994, pp. 175-186.
4. U. Shardanand and P. Maes, “Social Information Filtering: Algorithms for Automating ‘Word of Mouth,’” Proc.
Conf. Human Factors in Computing Systems (CHI 95),
ACM Press, New York, 1995, pp. 210-217.
5. W. Hill et al., “Recommending and Evaluating Choices
in a Virtual Community of Use,” Proc. Conf. Human
Factors in Computing Systems (CHI95), ACM Press,
New York, 1995, pp. 194-201.
6. M. Pazzani, “A Framework for Collaborative, ContentBased and Demographic Filtering,” Artificial Intelligence
Review, Dec. 1999, pp. 393-408.
7. G. Adomavicius and A. Tuzhilin, “Expert-Driven Validation of Rule-Based User Models in Personalization
Applications,” J. Data Mining and Knowledge Discovery, Jan. 2001, pp. 33-58.
8. R. Agrawal et al., “Fast Discovery of Association Rules,”
Advances in Knowledge Discovery and Data Mining,
AAAI Press, Menlo Park, Calif., 1996, chap. 12.
9. L. Breiman et al., Classification and Regression Trees,
Wadsworth, Belmont, Calif., 1984.
10. G. Piatetsky-Shapiro and C.J. Matheus, “The Interestingness of Deviations,” Proc. AAAI-94 Workshop
Knowledge Discovery in Databases, AAAI Press, Menlo
Park, Calif., 1994, pp. 25-36.
11. A. Silberschatz and A. Tuzhilin, “What Makes Patterns
Interesting in Knowledge Discovery Systems,” IEEE
Trans. Knowledge and Data Engineering, Dec. 1996,
pp. 970-974.
12. R. Srikant, Q. Vu, and R. Agrawal, “Mining Association Rules with Item Constraints,” Proc. Third Int’l
Conf. Knowledge Discovery and Data Mining, AAAI
Press, Menlo Park, Calif., 1997, pp. 67-73.
Gediminas Adomavicius is a PhD candidate in computer science at Courant Institute of Mathematical
Sciences, New York University, where he received an
MS. He received a BS in mathematics from Vilnius
University, Lithuania. He is a recipient of a Fulbright
Fellowship. His research interests include data mining, personalization, and scientific computing. Contact him at [email protected].
Alexander Tuzhilin is an associate professor of information systems at the Stern School of Business, New
York University. His research interests include knowledge discovery in databases, personalization, and temporal databases. Tuzhilin received a PhD in computer
science from the Courant Institute of Mathematical
Sciences, NYU. Contact him at [email protected].
edu.