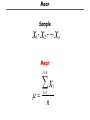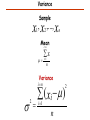Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Introduction to Biostatistics and Bioinformatics
Exploring Data and Descriptive Statistics
Learning Objectives
Python matplotlib library to visualize data:
• Scatter plot
• Histogram
• Kernel density estimate
• Box plots
Descriptive statistics:
• Mean and median
• Standard deviation and inter quartile range
• Central limit theorem
An Example Data Set
0.022
-0.083
0.048
-0.010
-0.125
0.195
-0.071
-0.147
0.033
0.080
0.073
0.016
0.148
0.135
0.006
-0.089
0.165
-0.088
-0.137
0.094
0.022
-0.083
0.048
-0.010
-0.125
0.195
-0.071
-0.147
0.033
0.080
0.073
0.016
0.148
0.135
0.006
-0.089
0.165
-0.088
-0.137
0.094
Measurement
Scatter Plot
Order or Measurement
Measurement
Histogram
Order or Measurement
Number of Measurements
Measurement
Bin size = 0.025
Number of Measurements
Bin size = 0.05
Number of Measurements
Bin size = 0.1
Measurement
Measurement
Measurement
Cumulative Distributions
Cumulative Frequency
Order or Measurement
Measurement
Measurement
Kernel Density Estimate
Number of Measurements
Order or Measurement
Measurement
Measurement
Original Distribution
Order or Measurement
Histogram
Original Distribution
Kernel Density Estimate
Measurement
Number of Measurements
Frequency
Number of Measurements
Bin size = 0.05
Measurement
Measurement
Measurement
More Data
Order or Measurement
Histogram
Original Distribution
Kernel Density Estimate
Measurement
Number of Measurements
Frequency
Number of Measurements
Bin size = 0.05
Measurement
Measurement
Exercise 1
Download ibb2015_7_exercise1.py
(a) Draw 20 points from a normal distribution with mean=0 and standard
deviation=0.1.
import numpy as np
y=0.1*np.random.normal(size=20)
print y
[-0.09946073 -0.19612617 0.03442682 0.02622746
-0.28418124 -0.04245968 0.05922837 0.01199874
0.13454915 -0.07482707 -0.11688758 0.01714036
0.03280043 0.01356022 0.09128649 -0.18923468
0.14536047 -0.07764629 -0.0349553
0.04300367]
Exercise 1
(b) Make scatter plot of the 20 points.
import matplotlib.pyplot as plt
x=range(1,points+1)
fig, (ax1) = plt.subplots(1,figsize=(6,6))
ax1.scatter(x,y,color='red',lw=0,s=40)
ax1.set_xlim([0,points+1])
ax1.set_ylim([-1,1])
fig.savefig('ibb2015_7_exercise1_scatter_points'+str(poi
nts)+'.png',dpi=300,bbox_inches='tight')
plt.close(fig)
Exercise 1
(c) Plot histograms.
for bin in [20,40,80]:
fig, (ax1) = plt.subplots(1,figsize=(6,6))
ax1.hist(y,bins=bin,histtype='step',color='black'
, range=[-1,1], lw=2, normed=True)
ax1.set_xlim([-1,1])
fig.savefig('ibb2015_7_exercise1_bin'+str(bin)+'_
points'+str(points)+'.png',dpi=300,bbox_inches='t
ight')
plt.close(fig)
Exercise 1
(d) Plot cumulative distribution.
y_cumulative=np.linspace(0,1,points)
x_cumulative=np.sort(y)
fig, (ax1) = plt.subplots(1,figsize=(6,6))
ax1.plot(x_cumulative,y_cumulative,color='black', lw=2)
ax1.set_xlim([-1,1])
ax1.set_ylim([0,1])
fig.savefig('ibb2015_7_exercise1_cumulative_points'+
str(points)+'.png',dpi=300,bbox_inches='tight')
plt.close(fig)
Exercise 1
(e) Plot kernel density estimate.
import scipy.stats as stats
kde_points=1000
kde_x = np.linspace(-1,1,kde_points)
fig, (ax1) = plt.subplots(1,figsize=(6,6))
kde_y=stats.gaussian_kde(y)
ax1.plot(kde_x,kde_y(kde_x),color='black', lw=2)
ax1.set_xlim([-1,1])
fig.savefig('ibb2015_7_exercise1_kde_points'+str(points)
+'.png',dpi=300,bbox_inches='tight')
plt.close(fig)
Comparing Measurements
Comparing Measurements – Cumulative distributions
Systematic Shifts
Exercise 2
Download ibb2015_7_exercise2.py
(a) Generate 5 data sets with 20 data points each from normal
distributions with means = 0, 0, 0.1, 0.5 and 0.3 and standard
deviation=0.1.
y=[]
for j in range(5):
y.append(0.1*np.random.normal(size=20))
y[2]+=0.1
y[3]+=0.5
y[4]+=0.3
print y
Exercise 2
(b) Make scatter plots for the 5 data sets.
sixcolors=['#D4C6DF','#8968AC','#3D6570','#91732B',
'#963725','#4D0132']
fig, (ax1) = plt.subplots(1,figsize=(6,6))
for j in range(5):
ax1.scatter(np.linspace(j+1-0.2,j+1+0.2,20),
y[j],color=sixcolors[6-(j+1)], lw=0,
alpha=1)
ax1.set_xlim([0,6])
ax1.set_ylim([-1,1])
fig.savefig('ibb2015_7_exercise2_scatter_sample'+
str(20),dpi=300,bbox_inches='tight')
plt.close(fig)
Correlation Between Two Variables
Correlation Between Two Variables
Correlation Between Two Variables
Correlation Between Two Variables
Correlation Between Two Variables
Data Visualization
http://blogs.nature.com/methagora/2013/07/data
-visualization-points-of-view.html
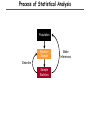
Process of Statistical Analysis
Population
Random
Sample
Describe
Sample
Statistics
Make
Inferences
Distributions
Normal
n=3
n=10
n=100
Skewed
Long tails
Complex
Mean
Sample
x , x ,..., x
1
2
n
Mean
i n
x
i 1
n
i
Mean - Sample Size
Normal Distribution
Mean
0.2
0.0
-0.2
0
20
40
60
80 100
Sample Size
Mean – Sample Size
Normal
Skewed
1
-1
0.2
-0.2
100
Sample Size
Long tails
Complex
Mode, Maximum and Minimum
Sample
x , x ,..., x
1
2
n
Mode
the most common value
Maximum
max( x1 , x2 ,..., xn)
Minimum
min( x1 , x2 ,..., xn)
Median, Quartiles and Percentiles
Sample
,
,...,
x1 x2 xn
Quartiles
Q x for 25% of the sample
Q2 xi for 50% of the sample (median)
Q x for 75% of the sample
i
1
3
i
P x
m
i
Percentiles
for m% of the sample
Median and Mean – Sample Size
Normal
1
Skewed
Median - Gray
-1
0.2
-0.2
100
Sample Size
Long tails
Complex
Variance
Sample
,
,...,
x1 x2 xn
Mean
i n
x
i 1
i
n
Variance
i n
2
( xi )
2
i 1
n
Variance – Sample Size
Normal
Skewed
0.6
0
0.1
0
100
Sample Size
Long tails
Complex
Inter Quartile Range (IQR)
Sample
,
,...,
x1 x2 xn
Quartiles
Q x for 25% of the sample
Q2 xi for 50% of the sample (median)
Q x for 75% of the sample
i
1
3
i
Inter Quartile Range
IQR Q Q
3
1
Inter Quartile Range and Standard Deviation
Normal
Skewed
1.0
IRQ/1.349 - Gray
0
0.4
0
100
Sample Size
Long tails
Complex
Central Limit Theorem
The sum of a large number of values drawn
from many distributions converge normal if:
•
•
•
The values are drawn independently;
The values are from the one distribution; and
The distribution has to have a finite mean and
variance.
Uncertainty in Determining the Mean
Normal
Skewed
Long tails
Complex
n=3
n=3
n=3
n=10
n=10
n=10
n=10
n=100
n=100
n=100
n=100
n=1000
Mean
Standard Error of the Mean
Sample
,
,...,
x1 x2 xn
Mean
i n
x
i 1
Variance
( xi )
i n
i
n
2
2
i 1
n
Standard Error of the Mean
s.e.m
n
Exercise 3
Download ibb2015_7_exercise3.py
(a) Generate skewed data sets.
sample_size=10
x_test=np.random.uniform(-1.0,1.0,size=30*sample_size)
y_test=np.random.uniform(0.0,1.0,size=30*sample_size)
y_test2=skew(x_test,-0.1,0.2,10)
y_test2/=max(y_test2)
x_test2=x_test[y_test<y_test2]
x_sample=x_test2[:sample_size]
1.
2.
3.
4.
5.
Generate a pair of random numbers within the range.
Assign them to x and y
Keep x if the point (x,y) is within the distribution.
Repeat 1-3 until the desired sample size is obtained.
The values x obtained in this was will be distributed according to the
original distribution.
Exercise 3
(b) Calculate the mean of samples drawn from the skewed data set and the
standard error of the mean, and plot the distribution of averages.
for repeat in range(1000):
…
average.append(np.mean(x_sample))
sem=np.std(average)
fig, (ax1) = plt.subplots(1,figsize=(6,6))
ax1.set_title('Sample size = '+str(sample_size)+', SEM = '
+str(sem))
ax1.hist(average,bins=100,histtype='step',color='red',range=
[-0.5,0.5],normed=True,lw=2)
ax1.set_xlim([-0.5,0.5])
Box Plot
M. Krzywinski & N. Altman, Visualizing samples with box plots, Nature Methods 11 (2014) 119
Box Plots
Normal
Skewed
Long tails
n=5
n=5
n=5
n=10
n=10
n=10
n=100
n=100
n=100
Complex
n=5
n=10
n=100
Box Plots with All the Data Points
Normal
Skewed
Long tails
n=5
n=5
n=5
n=10
n=10
n=10
n=100
n=100
n=100
Complex
n=5
n=10
n=100
Box Plots, Scatter Plots and Bar Graphs
Normal Distribution
Error bars: standard deviation
error bars: standard deviation
error bars: standard error
error bars: standard error
Box Plots, Scatter Plots and Bar Graphs
Skewed Distribution
Error bars: standard deviation
error bars: standard deviation
error bars: standard error
error bars: standard error
Exercise 4
Download ibb2015_7_exercise4.py and plot box plots for a skewed data set.
fig, (ax1) = plt.subplots(1,figsize=(6,6))
ax1.scatter(np.linspace(1-0.1, 1+0.1,sample_size),
x_sample, facecolors='none',
edgecolor=thiscolor, lw=1)
bp=ax1.boxplot(x_samples, notch=False, sym='')
plt.setp(bp['boxes'], color=thiscolor, lw=2)
plt.setp(bp['whiskers'], color=thiscolor, lw=2)
plt.setp(bp['medians'], color='black', lw=2)
plt.setp(bp['caps'], color=thiscolor, lw=2)
plt.setp(bp['fliers'], color=thiscolor, marker='o', lw=0)
fig.savefig(…)
Descriptive Statistics - Summary
• Example distribution:
• Normal distribution
• Skewed distribution
• Distribution with long tails
• Complex distribution with several peaks
• Mean, median, quartiles, percentiles
• Variance, Standard deviation, Inter Quartile Range (IQR), error bars
• Box plots, bar graphs, and scatter plots
Descriptive Statistics – Recommended Reading
http://blogs.nature.com/methagora/2013/08/giving_statistics_the_attention_it_deserves.html
Homework
Plot the ratio of the standard error of the mean and the standard deviation
as a function of sample size (use sample sizes of 3, 10, 30, 100, 300, 1000)
for the skewed distribution in Exercise 3. Modify ibb2015_7_exercise3.py
to generate this plot and email both the script and the plot.
Next Lecture: Sequence Alignment Concepts