Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
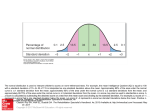
Chapter 6 1 Standard Deviation as a Ruler • The z-score, or standardized value, of an observation y is its distance from the mean measured in units of standard deviations; y− y z= . s Positive z-scores lie above the mean, negative zscores below the mean. A z-score is unchanged even after € shifting or rescaling the data Chapter 6 2 The Normal Distribution The most commonly occurring distributions are symmetric and “bell-shaped”. Mathematicians have devised a theoretical model for such distributions, the normal model. It faithfully describes many real data sets and is the basis for most statistical inference techniques. A normal curve is symmetric and bell-shaped, and is characterized by the position of its mean and the size of its standard deviation. Its mean, always denoted µ (mu, the Greek letter m), lies at the position of the central peak. The points on either side of the mean at which the curve changes concavity are located one standard deviation away from the mean. We denote the standard deviation of a normal model by σ (sigma, the Greek letter s). The normal distribution with mean and standard deviation is denoted N(µ, σ). Chapter 6 3 The 68–95–99.7 Rule For the normal model, • 68% of the data will lie within one standard deviation of the mean (between µ – σ and µ + σ); • 95% of the data will lie within two standard deviations of the mean (between µ – 2σ and µ + 2σ); • 99.7% of the data will lie within three standard deviations of the mean (between µ – 3σ and µ + 3σ). In situations where the normal model is applied to a given situation, sketch a graph of the model and identify the appropriate scale by indicating on the horizontal axis the seven values µ – 3σ, µ – 2σ, µ – σ, µ, µ + σ, µ + 2σ, µ + 3σ. Chapter 6 4 Working with the Normal Model • More general percentages associated with the normal model N(µ, σ) can be found with your calculator (or other statistical software): the percentage of values lying between two particular values a and b ( a ≤ y ≤ b ) is computed as DISTR normalcdf( a , b , µ , σ ) (If no upper bound b is given, it is understood that b = ∞ — use 1E99 for ∞; if no lower bound is given, it is understood that a = –∞ — use -1E99 for –∞.) • The standard normal distribution N(0, 1) has mean 0 and standard deviation 1. If a normal model N(µ, σ) applies to a data set, then the corresponding standardized values z will obey the standard normal distribution N(0, 1). Percentages associated with the standard normal model N(0, 1) can also be found with your calculator (or other statistical software): the percentage of values lying between two particular values a and b ( a ≤ y ≤ b ) is computed as DISTR normalcdf( a , b ) [TI-83: DISTR normalcdf] Chapter 6 5 • Technology can also be used to work with the inverse problem: to determine data values or zscores that correspond to particular percentages [TI-83: DISTR invNorm] Checking for normality • The Nearly Normal Condition If a data set has unimodal and symmetric shape, we may be able to apply the normal model to its study; check by consulting a histogram or a normal probability plot [TI-83: STATPLOT Type]