Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
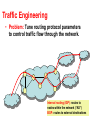
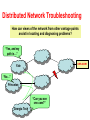
Measurement and Monitoring Nick Feamster Georgia Tech Measurement and Monitoring • Measurement: “Inventory” of network state – Traffic loads on links – End-to-end packet loss rates, throughput, etc. –… • Monitoring: Use of measurement to detect events of (operational) interest – Link failures – Stolen routes (“hijacks”) –… Problem Areas • Traffic Engineering • (Distributed) Network Troubleshooting • Anomaly Detection Good work in pieces of each puzzle. Lots of heuristics. Nothing that unifies these pieces yet. Traffic Engineering • Problem: Tune routing protocol parameters to control traffic flow through the network. Internal routing (IGP): routes to nodes within the network (“AS”) BGP: routes to external destinations Traffic Engineering • Goal: Efficient, offline analysis • Lots of measured inputs OSPF Link Weight Optimization Topology Routes to external destinations Static configuration analysis BGP configuration Routing Model for Network Traffic Flow Traffic matrix estimation Offered traffic TE-Motivated Algorithmic Problem • How to identify large traffic bundles? – Today’s mode: By address block (actually, groups of prefixes, by AS path regular expressions) – Clunky! • Wanted: traffic bundle identification – “To move 10 Mbps from the Sprint peering point in New York to the AT&T peering point in Boston, do X.” – X may depend on timescales of traffic engineering issue (flash crowd, persistent congestion, etc.) What to do once we’ve measured? • IGP link weights and BGP parameters both: – Change the traffic volumes on internal links – Change traffic volumes on links between ASes • Questions – How to explore the parameter search space? – How to decide when to tweak IGP or BGP? • Probable Answer: Intractable – Design for optimization: Could the routing protocol “knobs” be designed so that joint optimization is easier? Network Troubleshooting • Goal: Locate and diagnose network performance (or reachability) problems • Status: Lots of (somewhat imperfect) tools – – – – Ping: “reachability” Traceroute: “IP-layer path to destination” Iperf: throughput Pathchar: per-hop capacity estimation • None of these is prescriptive. They often don’t answer questions that would lead to a solution. – “Why is the traffic not getting there?” (link failure, firewall configuration, etc.) – “Which network caused this event?” Why Troubleshooting is Hard Plethora of causes • Misconfigured filters • Link failures (between ASes or within an AS) • Middlebox problem (NAT, firewall, etc.) • Application-level failures (server crash) • Service failure (DNS failure) Key (currently hard) questions • Is the problem local or global? • If global, where is it? Perhaps asking neighboring networks can help Distributed Network Troubleshooting How can views of the network from other vantage points assist in locating and diagnosing problems? “Yes, and my path is…” cnn.com Yale “No…” Princeton “Can you see cnn.com?” Georgia Tech Some Measurement Problems • Could protocols be augmented/altered to make them more amenable to passive measurement? – What are the accuracy bounds for passive measurement algorithms (e.g., sampled NetFlow) • How many views are needed to locate a problem? – Perhaps this depends on the problem…things like filtering/reachability might be easier than congestion – The answer may also change depending on the topology and failure model (i.e., what if some nodes can’t talk to each other? Measurement and Monitoring • Measurement: “Inventory” of network state – Traffic loads on links – End-to-end packet loss rates, throughput, etc. –… • Monitoring: Use of measurement to detect events of (operational) interest – Link failures – Route hijacks –… Anomaly Detection • State of the art: Threshold-based schemes – Counting the number of BGP updates – Counting the number of failed TCP connections – Measuring the size of a traffic shift • Problem: Many events of interest are small – Route hijacks: one BGP update (small amount of traffic) – Polymorphic worms: e.g., 2-byte common substring Detecting Small Events • What techniques can tease out (low-energy) signal from noise? – Route hijacks: Could exploting correlations across data streams expose deviations? Need distributed algorithms for tracking patterns in real time… – Worm containment: Algorithms for fast (line rate) detection of small common substrings? • What changes might (1) raise the bar for these attacks or (2) facilitate distributed anomaly detection? – e.g., having a better notion of identity than an IP address Real Problem • State of the art distributed debugging protocols…