Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Chapter 3
Data Mining:
Classification
& Association
Chapter 4 in the text box
Section: 4.3 (4.3.1), 4.4
1
2
Introduction
Data mining is a component of a
wider process called knowledge
discovery from databases.
Data mining techniques include:
Classification
Clustering
3
What is Classification?
Classification is concerned with generating a
description or model for each class from the
given dataset of records.
Classification can be:
Supervised (Decision Trees and Associations)
Unsupervised (more in next chapter)
4
Supervised Classification
Training
set (pre-classified data)
Use the training set, the classifier
generates a description/model of the
classes which helps to classify unknown
records.
How can we evaluate how good the
classifier is at classifying unknown records?
Using a test dataset
5
Decision Trees
A decision tree is a tree with the following
properties:
An inner node represents an attribute
An edge represents a test on the
attribute of the father node
A leaf represents one of the classes
Construction of a decision tree:
Based on the training data
Top-Down strategy
6
Decision Trees
The set of records available for classification
is divided into two disjoint subsets:
a training set
a test set
Attributes whose domain is numerical are
called numerical attributes
Attributes whose domain is not numerical
are called categorical attributes.
7
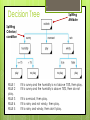
Training dataset
8
Test dataset
Decision Tree
9
Splitting
Attribute
Splitting
Criterion/
condition
RULE 1
RULE 2
play.
RULE 3
RULE 4
RULE 5
If it is sunny and the humidity is not above 75%, then play.
If it is sunny and the humidity is above 75%, then do not
If it is overcast, then play.
If it is rainy and not windy, then play.
If it is rainy and windy, then don't play.
10
Confidence
Confidence
in the classifier is determined
by the percentage of the test data that is
correctly classified.
Activity:
Compute the confidence in Rule-1
Compute the confidence in Rule-2
Compute the confidence in Rule-3
11
Decision Tree Algorithms
ID3
algorithm
Rough Set Theory
12
Decision Trees
ID3
Iterative Dichotomizer (Quinlan 1986),
represents concepts as decision trees.
A decision tree is a classifier in the form of
a tree structure where each node is either:
a leaf node, indicating a class of instances
OR
a decision node, which specifies a test to
be carried out on a single attribute value,
with one branch and a sub-tree for each
possible outcome of the test
13
Decision Tree development
process
Construction
phase
Initial tree constructed from the training
set
Pruning
phase
Removes some of the nodes and
branches to improve performance
Processing
phase
The pruned tree is further processed to
improve understandability
14
Construction phase
Use Hunt’s method:
T : Training dataset with class labels { C1,
C2,…,Cn}
The tree is built by repeatedly partitioning the
training data, based on the goodness of the
split.
The process is continued until all the records in
a partition belong to the same class.
15
Best Possible Split
Evaluation
of splits for each attribute.
Determination of the splitting condition on
the selected splitting attribute.
Partitioning the data using best split.
The best split: the one that does the best
job of separating the records into groups,
where a single class predominates.
16
Splitter choice
To choose a best splitter,
we consider each attribute in turn.
If an attribute has multiple values, we sort it,
measure the goodness, and evaluate each
split.
We compare the effectiveness of the split
provided by the best splitter from each
attribute.
The winner is chosen as the splitter for the root
node.
17
Iterative Dichotimizer (ID3)
Uses Entropy: Information theoretic approach
to measure the goodness of a split.
The algorithm uses the criterion of information
gain to determine the goodness of a split.
The attribute with the greatest information
gain is taken as the splitting attribute, and the
data set is split for all distinct values of the
attribute.
18
Entropy
19
Information measure
Information needed to identify the class of
an element in T, is given by:
Info(T)= Entropy (P)
Where P is the probability distribution of the
partition C1, C2, C3,…Cn.
𝑷=
𝑪𝟏 𝑪𝟐 𝑪𝟑
𝑪𝒏
( , , ,.., )
𝑻 𝑻 𝑻
𝑻
20
Example-1
T : Training dataset, C1=40, C2=30, C3=30
Compute Entropy of (T) or Info(T)
T
C1
C2
C3
100
40
30
30
21
Info (X,T)
If T is partitioned based on attribute X, into
sets T1, T2, …Tn, then the information
needed to identify the class of an element
of T becomes:
𝑛
𝐼𝑛𝑓𝑜 𝑋, 𝑇
=
𝑖=1
𝑇𝑖
𝐼𝑛𝑓𝑜(𝑇𝑖 )
𝑇
22
Example-2
If T is divided into 2 subsets S1, S2, with n1,
and n2 number of records according to
attribute X.
If we assume n1=60, and n2=40, the
splitting can be given by:
S1
C1
C2
C3
S2
C1
C2
C3
40
0
20
20
60
40
10
10
Compute
Entropy(X,T) or Info (X,T) after
segmentation
23
Information Gain
24
Example-3
Gain (X,T)
=Info(T)-Info(X,T)
=1.57-1.15
=0.42
25
Example-4
Assume
we have another splitting on
attribute Y:
S1
C1
C2
C3
S1
C1
C2
C3
40
20
10
10
60
20
20
20
Info
(Y,T)=1.5596
Gain= Info(T)-Info(Y,T)=0.0104
26
Splitting attribute X or Y?
Gain (X,T) =0.42
Gain (Y, T)=0.0104
The splitting attribute is chosen to be the
one with the largest gain.
X
27
Gain-Ratio
Gain
tends to support attributes which
have a large number of values
If attribute X has a distinct value for each
record, then
Info(X,T)=0
Gain (X,T)=maximal
To balance this, we use the gain-ratio
instead of gain.
𝐺𝑎𝑖𝑛(𝑋, 𝑇)
𝐺𝑎𝑖𝑛_𝑅𝑎𝑡𝑖𝑜(𝑋, 𝑇) =
𝐼𝑛𝑓𝑜(𝑋, 𝑇)
28
Index of Diversity
A
high index of diversity
set contains even distribution of classes
A low index of diversity
Members of a single class predominates
)
29
Which is the best splitter?
The best splitter is one that decreases the
diversity of the record set by the greatest
amount.
We want to maximize:
[Diversity before split(diversity-left child + diversity right child)]
30
Index of Diversity
31
Numerical Example
For the play golf example, compute the
following:
Entropy of T.
Information Gain for the following attributes:
outlook, humidity, temp, and windy.
Based on ID3, which will be selected as the
splitting attribute?
32
Association
33
Association Rule Mining
The
data mining process of identifying
associations from a dataset.
Searches for relationships between items
in a dataset.
Also called market-basket analysis
Example:
90% of people who purchase bread also
purchase butter
34
Why?
Analyze
customer buying habits
Helps retailer develop marketing
strategies.
Helps inventory management
Sale promotion strategies
35
Basic Concepts
Support
Confidence
Itemset
Strong
rules
Frequent Itemset
36
Support
IF A B
Support (AB)=
#of tuples containing both (A,B)
Total # of tuples
The support of an association pattern is the
percentage of task-relevant data transactions for
which the pattern is true.
37
Confidence
IF
A B
Confidence (AB)=
#of tuples containing both (A,B)
Total # of tuples containing A
Confidence is defined as the measure of certainty or
trustworthiness associated with each discovered
pattern.
38
Itemset
A
set of items is referred to as itemset.
An itemset containing k items is called k
itemset.
An itemset can also be seen as a
conjunction of items (or a predicate)
39
Frequent Itemset
Suppose
min_sup is the minimum support
threshold.
An itemset satisfies minimum support if the
occurrence frequency of the itemset is
greater than or equal to min_sup.
If an itemset satisfies minimum support,
then it is a frequent itemset.
40
Strong Rules
Rules that satisfy both a minimum support
threshold and a minimum confidence
threshold are called strong.
41
Association Rules
Algorithms that obtain association rules from
data usually divide the task into two parts:
Find the frequent itemsets and
Form the rules from them:
Generate strong association rules from the
frequent itemsets
42
A priori algorithm
Agrawal
and Srikant in 1994
Also called the level-wise algorithm
It is the most accepted algorithm for finding all
the frequent sets
It makes use of the downward closure property
The algorithm is a bottom-up search,
progressing upward level-wise in the lattice
Before
reading the database at every
level, it prunes many of the sets, sets
which are unlikely to be frequent sets.
43
A priori Algorithm
Uses
a Level-wise search, where kitemsets are used to explore (k+1)itemsets,
to mine frequent itemsets from
transactional database for Boolean
association rules.
First, the set of frequent 1-itemsets is
found. This set is denoted L1. L1 is used to
find L2, the set of frequent 2-itemsets,
which is used to fine L3, and so on,
44
A priori Algorithm steps
The first pass of the algorithm simply counts
item occurrences to determine the frequent
itemsets.
A subsequent pass, say pass k, consists of two
phases:
The frequent itemsets Lk-1 found in the (k-1)th
pass are used to generate the candidate item
sets Ck, using the a priori candidate generation
function.
the database is scanned and the support of
candidates in Ck is counted.
45
Join Step
Assume
that we know frequent itemsets of
size k-1. Considering a k-itemset we can
immediately conclude that by dropping
two different items we have two frequent
(k-1) itemsets.
From another perspective this can be
seen as a possible way to construct kitemsets. We take two (k-1) item sets
which differ only by one item and take
their union. This step is called the join step
and is used to construct POTENTIAL
frequent k-itemsets.
46
Join Algorithm
47
Pruning Algorithm
48
Pruning Algorithm Pseudo code
49
Tuples represent
transactions (15
transactions)
Columns represent
items (9 items)
Min-sup = 20%
Itemset should be
supported by 3
transactions at least
50
51
52
53
Example
Source: http://webdocs.cs.ualberta.ca/~zaiane/courses/cmput499/slides/Lect10/sld054.htm