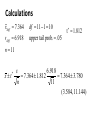Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
AP Statistics Section 10.2 B Comparative studies are more convincing than single-sample investigations. For that reason, one-sample inference is less common than comparative inference. Paired t procedures are called for in the following situations A matched pairs design experiment. 1. Subjects are matched in pairs and each treatment is given to one subject in each pair. 2. Each subject receives both treatments in some order. Before-and-after observations on the same subjects. To compare the responses to the two treatments in a matched pairs design or before-and-after measurements on the same subjects, apply one-sample t procedures to the observed difference. Example: Our subjects are 11 people diagnosed as being dependent on caffeine. Each subject was barred from coffee, colas and other substances containing caffeine for the duration of the experiment. During one 2-day period subjects took capsules containing their normal caffeine intake. During a different 2-day period, they took placebo capsules. The order in which subjects took caffeine and the placebo was randomized. At the end of each 2-day period, a test (Beck Depression Inventory) was given to all 11 subjects. The table at the right contains data on the subjects’ scores on the depression test. Higher scores show more symptoms of depression. Construct a 90% confidence interval for the mean change in depression score. Parameter The population of interest is all people dependent on caffeine. We want to estimate the mean difference in depression score of individuals in the population who take both the caffeine capsule and the placebo. Conditions Since the population standard deviation of the differences in depression scores is not known we will use ___________________________to one sample t procedures construct a confidence interval. SRS: Subjects not an SRS - usually volunteers Conclusions may not generalize to the population. Normality: Unknown if population is Normal. Sample too small for CLT. if not normal: boxplot? Normal probability plot? No serious deviations from Normal, so I will proceed. If the distribution of x is not Normal, results may not be accurate. Independence: Based on the randomized design of the experiment, it is reasonable to assume that the differences are independent. Also safe to assume that the population is at least 10 times as large as our sample size. Calculations xdiff 7.364 sdiff 6.918 df 11 1 10 upper tail prob. .05 t 1.812 n 11 x t s 6.918 7.364 1.812 7.364 3.780 n 11 (3.584, 11.144) Interpretation We are 90% confident that the mean difference in depression scores for the population of people dependent on caffeine is between 3.584 and 11.144.