Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Remote Desktop Services wikipedia , lookup
Deep packet inspection wikipedia , lookup
Dynamic Host Configuration Protocol wikipedia , lookup
Net neutrality law wikipedia , lookup
Distributed firewall wikipedia , lookup
Piggybacking (Internet access) wikipedia , lookup
List of wireless community networks by region wikipedia , lookup
Cracking of wireless networks wikipedia , lookup
Internet protocol suite wikipedia , lookup
Recursive InterNetwork Architecture (RINA) wikipedia , lookup
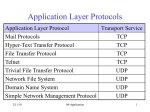
ECES 742 Chapter 1 Internet Practices - Introduction Internet Standards Naming and Addressing The Fundamental Internet Protocols TCP Connectoins The DNS System Resources and URIs Introduction Simply stated, the practice of Distributed Computing is using computers across a networked environment. Although such an environment can be extremely complex, we thankfully have, for most all practical purposes, one network in this environment – the Internet, made up of a standard set of software protocols that are recognized by nearly all computer software creators. Most distributed application therefore run on top of a well understood infrastructure, insulated from the complexities of the physical network. It is because of the advances and innovations in Distributed Computing that the Internet continues to grow at remarkable rates. Just how large the Internet is, is hard to say. However, when designing and developing a distributed applications it is important to keep an eye on the size and scope of the target. Keeping in mind a few fun statistics can often help in this regard. In August 2005, there were over 500M internet addresses in use, 57 M Domain names registered, 8 G webpages indexed by Google, 150M active bloggers, 10M active users of P2P file sharing networks. The following table breaks out the total traffic on the Internet by geographical region. Note the high penetration in the industrial regions, and the tremendous growth rates in the under-industrialized regions.. World Regions Population % Africa 896,721,874 14.0 % Asia 3,622,994,130 56.4 % 323,756,956 183.2 % 8.9 % 34.5 % Europe 731,018,523 11.4 % 269,036,096 161.0 % 36.8 % 28.7 % Middle East 260,814,179 4.1 % 21,770,700 2.3 % North America 328,387,059 5.1 % 223,392,807 106.7 % 68.0 % 23.8 % Latin America 546,723,509 8.5 % 68,130,804 277.1 % 12.5 % 7.3 % 0.5 % 16,448,966 115.9 % 49.2 % 1.8 % Oceania / Australia 33,443,448 WORLD TOTAL 6,420,102,722 Internet Usage Growth Penetration Users% 16,174,600 100.0 % 938,710,929 258.3 % 1.8 % 311.9 % 8.3 % 1.7 % 160.0 % 14.6 % 100.0 % Internet Standards The success of the Internet owes a great deal to a set of open software standards. Such standards are simply a set of publicly available specifications for achieving specific networking tasks. Standardization increases the compatibility between computing components, and is essential in distributed computing and networking because many different groups design run and build hardware and software for such systems. Internationally, the work of all standards bodies is coordinated by the International Organization for Standardization (ISO), which is based in Geneva, Switzerland, of course. Internet standards, in particular, are developed by the Internet Engineering Task Force (IETF), and promoted internationally by the Internet Society (ISOC). A group of people known as RFC Editors (which is overseen by the ISOC) is responsible for preparing and organizing the standards in their final form. The standards may be found at numerous sites distributed throughout the world. The World Wide Web Consortium (W3C), which is based at MIT, plays the leading role in developing and promulgating WWW standards. The Request for Comments documents (RFCs) are working notes of the Internet research and development community. A document in this series may deal with essentially any topic related to computer communication, and may be anything from a meeting report to the specification of a standard. Most RFCs are the descriptions of network protocols or services, often giving detailed procedures and formats for their implementation (see RFC 1206 (1991) ) RFCs tend to be highly technical and difficult to read, but can be a useful source of information about topics concerning specific aspects of the Internet. Many Internet standards are de facto – that is to say that their status as a standard has taken place through common practice, and not necessarily sanctioned by any standards body. There are many informative resources, outside of the technical standards documents, which discuss particular Internet standards. One such searchable resource is the free web encyclopedia Wikipedia, which often has clear explanations and technical details. Architecture of the Internet The architecture of the Internet is on whole quite complex, and so it is often conveniently viewed as layers. Each network layer represents communication of data in a particular format which is understandable to the protocols that operate on that layer. Such layering significantly simplifies the overall design and implementation of the protocols and reduces the complexity when changes are made in the system.. Application layer Application layer Transport layer Transport layer Internet layer Internet layer Physical layer Physical layer The Internet layer implements the Internet Protocol (IP) which provides the functionalities for allowing data packets to be transmitted between any two hosts on the Internet. The Transport layer implements the Transmission Control Protocol (TCP) which delivers the transmitted data in reliable fashion to a specific process running on an Internet connected host. The Application layer supports the programming interface used for building a program such as a web browser, an instant messaging client, or a peer-topeer file sharing application. Naming and Addressing The Internet consists of a hierarchy of networks, or subnets, interconnected via a network backbone. Each subnetwork has a unique network address. Computers, or hosts, are connected to a network and often given a local address that is a unique ID within its network. In IP version 4, each address is 32 bit long, and this address space can accommodate 232 (4.3 billion) addresses in total. The 32 bits are divided into a network address and a host address. IP network addresses are assigned by the IANA authority to organizations such as universities, or Internet Service Providers (ISPs). Individual organizations determine how to assign and manage the host portion of the address. Universities generally are assigned class B addresses which mean that the first two bytes (16 bits) are reserved for the network address and the remaining two bytes are reserved for the host address within the University. The huge demand for IP addresses has led many organizations to adopt dynamic addressing schemes that allow the pooling of individual addresses. For example, a University that can allocate 2^16 or 64K static hosts can dynamically allocate these to only the active sessions, and thus server much greater numbers of users. DHCP software can be used for this purpose. Subnet Masks and Port Numbers A subnet mask, or simply a netmask, is a 32-bit value that matches an IP addresses in length. It generally is used to subdivide (subnet) a given IP class network into smaller (sub)networks. The Netmask determines which portion of an IP address is the network address and which is the host address. An IP address bit is a network address bit if the corresponding netmask bit is 1 and IP address bit is a host address bit if the corresponding netmask bit is 0 Each process running on a host is associated with zero or more ports. A port is a logical entity for data transmission. Each Internet host uses 16 bits to address these ports, which means there are 65,535 logical ports that are available to be allocated to any particular process. The port numbers are divided into three ranges: the Well Known Ports, the Registered Ports, and the Dynamic and/or Private Ports. The Well Known Ports are those from 0 through 1023 and are reserved for processes which provide well-known services such as finger (79), ftp (21), http (80), email(25, 110, 995, 143, 993), telnet (23), dns (53). The Registered Ports are those from 1024 through 49151 which are used for application registered with IANA, such as Instant Messaging Service (2980). The Dynamic and/or Private Ports are those from 49152 through 65535. Pop Quiz: What is the relationship between the number of bits in the address and the number of possible addresses? Investigate: How does IP version 6 differ from version 4, and what are the barriers to its widespread adoption? The Fundamental Internet Protocols On the Internet there are two standards methods of transporting data between hosts: one that supports so-called connectionless, unreliable delivery – the User Datagram Protocol (UDP) , and one that supports so-called connection-oriented, reliable delivery - the Transmission Control Protocol (TCP). Application programs using UDP are themselves responsible for message loss, duplication, delay, out-of-order delivery, and loss of connectivity. Hence, it is no surprise that most application rely on TCP. Both TCP and UDP rely on the Internet Protocol (IP), the fundamental protocol of the Internet. IP which defines the specific format of packet and the way such packets are communicated between different networks. Pop Quiz: Give a one sentence definition of the Internet. Ans: The Internet is simply the sum of all networks around the world that are linked together by IP protocol. We now give short descriptions of the suite of most common Internet Protocols. We will return to many of these throughout the text. TCP/IP - For most purposes there is no need to carefully separate the functionalities of TCP and IP. Think of TCP/IP as simply the standard way to create a connection between two internet hosts, enabling the exchange of streams of packets delivered in correct order TCP/IP is in reality the commonly used name for a family of over 100 datacommunications protocols used to organize computers and data communications equipment HTTP - Hypertext Transfer Protocol The Hypertext Transfer Protocol is the system used for transferring hypertext documents and other multimedia information via the World Wide Web. FTP - File Transfer Protocol is very similar to and predates HTTP. FTP allows people to transfer files between two computers connected via the Internet. Telnet - The virtual terminal protocol allows users of one host to log into a remote host and interact as a normal terminal user of that host. SMTP Electronic mail Among the earliest and most widely used protocols are those governing electronic mail. Some important standards are: SMTP - Simple Mail Transfer Protocol, POP3 and IMAP, X400/X500 (now the official standards) are better suited to commercial use since they provide better message control and protection than SMTP. MIME – The "Multi-purpose Internet Mail Extensions" specifies ways to send many different kinds of information via email. DHCP - Dynamic Host Configuration Protocol is a protocol that provides configuration parameters specific to the client host requesting, generally, information required by the host to participate on the Internet network. DHCP also provides a mechanism for allocation of IP addresses to hosts. There are websites such as www.whatismyip.com, that will inform you of the IP address your machine is using even when your IP address is dynamic generated by DHCP. TCP Connections In these notes we do not cover details on networking technologies; instead we concentrate on distributed applications that run on top of the Internet infrastructure. In the next chapter we will look closely at web applications and discuss the details of the HTTP protocol. However, it is important to understand the basics of setting up connections between nodes across the Internet, and this is the work of the TCP protocol. Detailed information is on TCP is available in RFC793 and RFC 1122. The heart of TCP is to provide the following four services in the delivery of data between nodes: Application identification Reliable delivery Ordered delivery Stream-oriented transmission Application identification is critical since multiple applications may be communicating with multiple host nodes. TCP uses assigned port numbers so that messages are passed to the correct application. We have already seen that web servers typically run on a single well known port 80. So there is still an issue of how a web server knows which client it is to serve. The answer is that each connection has an associated identifier for each end-toend process-to-process connection. The source port number and source IP address define the sender’s socket address; and similarly the destination port number and destination IP address define the destination’s socket address. Together this information uniquely specifies a TCP connection that can establish a link, for example between an HTTP client with an HTTTP server. In practice, TCP connections are established by sending formatted ‘segments’ in order to initiate a handshaking process. Segments contain control bits that inform the receiver of an intention to connect. The handshake involves the exchange of acknowledgments, and agreements on message sequence numbers allow the process of data delivery to begin. The DNS System Naming, addressing, and name resolution are key components to all distributed computing applications. In naming schemes there is often a tension between humanreadability naming and computer-readability. Internet addresses (IP) are not user-friendly and hence there is a need for a layer of human readable domain names. The domain name system (See RFC 1034, 1035) is the most prominent user visible part of Internet naming and addressing. Domain names are dotted sequences of labels, such as aol.com, world.std.com, ftp.gnu.lcs.mit.edu. Domain Names form an important part of most World Wide Web addresses or URLs [RFC 2396], commonly appearing after "//". We will look more closely at URLs in the next section. Let us now look at the system used to resolve user-friendly domain names into machine-friendly IP addresses. Servers organized into what is known as the domain name system (DNS) provide the name resolution or translation service, based on a distributed database of records of names and IP address mappings. Thousands of DNS servers run continually on the Internet, and form what is probably the largest and most successful distributed application in history. Web browsers and client programs such as nslookup can query DNS servers to translate between domain names and IP addresses. Each DNS server is responsible for translating a portion of the space of domain names; each protion is called a zone. The servers that have access to the DNS information (zone file) for a zone are said to have authority for that zone. (The overall structure and delegation of authorities is specified in RFC 1591 and outside our scope.). The DNS groups hosts into a hierarchy of authority that allows addressing and other information to be widely distributed and maintained. A big advantage to the DNS is that using it eliminates dependence on a centrally-maintained file that maps host names to addresses. Although hierarchical zones in the domain name system are locally managed, they need do need to be reachable starting from a small number of top level (root) servers which are controlled essentially by ICANN and the US Department of Commerce. DNS is usefully thought of as a tree-structure with each node having its own label. A fully qualified domain name (fqdn) for a specific node would be its label followed by the labels of all the other nodes between it and the root of the tree. For example, for a host, a fqdn would include the string that identifies the particular host, plus all domains of which the host is a part up to and including the top-level domain (the root domain is always null). For example, cayley.ececs.uc.edu is a fully qualified domain name for the host machine in Dr. Annexstein’s office. The web site www.internic.net has been established to provide public information about Internet domain name registration services. Domain names beginning with “www” denote that they belong to a websever or more typically to an alias for a webserver. For example, the name www.ececs.uc.edu is an alias that allows flexibility in mapping the service, in this case serving departmental web pages. A change of machine does not require a change of all references to it. The alias allows a change to the nameserver entry that point to it. Hence, the same machine can have many different aliases, one for each service concerned. Also, it is possible for many machines to have the same alias. Providing this functionality is a job for DNS server software. Over the past several years, a software package known as BIND (Berkeley Internet Name Domain) has served as the de facto standard for a DNS server software, especially on Unix-like systems. Recently, much work has focused on security vulnerabilities and fixes for BIND. Security for the domain name system is being standardized [RFC 2535], but this has not been deployed to any significant extent. Investigate: What are the standard DNS server software packages today? How do they address the security issues involved in the DNS system? Delegation is an important general concept in distributed name resolution applications. Delegation is the process of giving the responsibility of completing a task to another party. The Domain Name System uses hierarchical delegation that complements the hierarchical organization of the space of domain names. In the next section we see how name servers are organized to delegate hierarchically. In contrast, Net news [RFC 977, 2980] uses hierarchically structured newsgroup names that are similar in appearance to domain names, except that the most significant label is on the left and the least on the right, the opposite of domain names. In fact this left to right ordering is a superior design since, for example, standard lexicographic sorting methods can easily sort names in accordance with the hierarchy. While the Net news names are structured hierarchically like domain names, there is no centralized control or hierarchical delegation. Instead, news servers periodically connect to other news servers that have agreed to exchange messages with them and they update each other on message only in those newsgroups in which they wish to exchange messages. With no such central point or points in the net news world, any set of news servers anywhere in the world can agree to exchange news messages under any news group names they like, including duplicates of those used elsewhere in the net. DNS Name Servers In the DNS system no server has every hostname-to-IP address mapping, however every host is registered with at least one authoritative server that stores that host’s IP address and name. The authoritative name server can perform name/address translation for that host’s name/address. Each ISP, university, company, has a local (default) name server authoritative for its own hosts. Resolvers always query a name server local to it to resolve any host name. A root name server is contacted when a local name server can not resolve a name. The root server either resolves the name or provides pointers to authoritative servers at lower level of name hierarchy. There are approximately 10-20 root name servers worldwide. To resolve a non-local name the local name server queries the root server (if necessary). The root server contacts the authoritative server (if necessary) and the results of the resolution propagate back to the original requestor. In short, this is how the process of delegation works in DNS. The DNS supports two modes of queries which impacts on the way that the name server responds. These two modes are called recursive and iterative. The simplest mode for the server is iterative, since it can answer queries using only local information: the response contains the answer, or a referral to some other server "closer" to the answer (or possibly an error message). All DNS name servers must implement iterative queries. The simplest mode for the client is recursive, since in this mode the name server acts in the role of a resolver and returns the answer, or an error message, but never referrals. This service is optional in a name server, and the name server may also choose to restrict the clients which can use recursive mode. Recursive service is helpful in several situations, for example, when a relatively simple requester lacks the ability to use anything other than a direct answer to the question. Further, recursion is useful in a network where we want to concentrate the cache rather than having a separate cache for each client. The use of recursive mode is limited to cases where both the client and the name server agree to its use. The agreement is negotiated through the use of two control bits in query and response messages. Iterative service is appropriate if the requester is capable of pursuing referrals and interested in information which will aid future requests. On the other hand, Iterative queries require local more local resources, and are generally more reliable and more secure than recursive service. Problems Not Addressed by DNS DNS queries carry no information about the client that triggered the name resolution. This creates a number of problems for certain name resolution applications. It is difficult to resolve names in the context of the client making the request. Often we would like to direct a client to a resource that lies near them to take advantage of locality. The best we can often achieve is to assume that the requesting DNS server is close to the originating client, since all that the service-side DNS server knows is the network address of the DNS server that asks about the service location. Yet another complication can be caused by caching answers in DNS. To avoid contacting the service domain DNS server too often, and to resolve repetitive queries faster, each answer can be assigned a TTL value (Time To Live). The TTL specifies the maximum time for which the answer can be stored in the network and considered valid. Thus, as long as a DNS server has such an answer in its cache, it can respond to a client immediately without bothering the service domain DNS server that previously produced the answer. Since regular domain names seldom change, DNS servers usually use large TTL values (the suggested value is 3 days, and the maximum - one week). The problem is that all responses of the redirector are time-dependent and can expire shortly. If we cannot control their lifetime, we can end up in the situation in which the clients are redirected to replicas which are not optimal, or even no longer exist. A fundamental issue for our approach is how to choose TTL values. Large values favor caching, therefore efficiency. Small values, however, favor accuracy. Resources, URIs, and XRIs As we have seen, the current Internet infrastructure is based primarily on two layers of identifiers – machine-friendly IP addresses and human-friendly DNS names. One of the main reasons that the Internet continues to evolve at a rapid pace is that people find great value in the sharing of computing and data resources within groups large and small. To support sharing, resources must be uniquely and meaningfully identifiable. On the Internet we use names known as a URI (Uniform Resource Identifiers) for this purpose. A URI is a formatted character string, usually involving a domain name, which names and/or locates a particular resource. When a URI points to a specific resource at a specific location we call it a URL (Uniform Resource Locator), and when it points to a specific resource at a nonspecific location we call it a URN (Uniform Resource Name). URIs are based on DNS (and IP) and is the linking syntax for the World Wide Web. Some examples follow (see definition in RFC 2396) • • • ftp://ftp.example.com/directory/file.tar mailto:[email protected] http://www.ins.usdoj.gov/index.html Since links tend to break when resources move on the network we can use URN (Uniform Resource Name) to provide location-independent identifiers (see definition in RFC 2141) urn:isbn:0-395-36341-1 urn:ietf:rfc:2141 urn:us:gov:doj:ins:someschema URNs allow only one type of abstract identifier – those requiring absolute persistence. However, designers are finding that new distributed applications require more flexible naming models. Consider an application of sharing business cards and creating dynamic address books electronically, to support dynamic business relationships. The dependence on traditional Internet naming, addressing, and name resolution makes solving such problems difficult. Locating and adding new contacts, and updating old contacts are tricky when relying on URLs, since contact information is typically embedding into it. Applications such as these have focused a need for other types of abstract identifier. One project addressing the naming issues is on work to define XRIs – extensible resource identifiers. The goals of XRIs are to create a unified syntax for abstract identifiers and a unified Internet-based resolution protocol, including support for secure resolution. Major challenges for such a system are to support reassignable names that are human-friendly. Another issue is to provide cross-context support that would allow for a more uniform or standardized way to locate certain types of generally recognized contact information, such as phone numbers and email addresses. Investigate: Find other examples of where the existence of human-friendly name resolution would enable the design of (radically) new distributed information applications.