Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
GPU Computing:
Pervasive Massively
Multithreaded
Processors
Michael C Shebanow
Sr. Architecture Manager,
GPUs
Agenda
●
●
●
●
●
GPU Computing
Tesla Products
CUDA
SM: Thread
Multiprocessor
Application
Performance Model
© NVIDIA Corporation 2008
GPU Computing
● GPU = graphics
processing unit
● NVIDIA’s latest
●
products =
88xx/98xx series
Accelerates
Graphics
● GPU Computing
● Using GPUs for
general purpose
computing other
than graphics
© NVIDIA Corporation 2008
GPU Computing is Pervasive
●
Huge #s of deployed
parallel computing engines
●
●
●
NVIDIA has shipped >70M
CUDA-capable GPUs to
date
NVIDIA currently shipping
more than1M CUDAcapable GPUs per week
Wide range of products
ranging from laptops to the
servers
●
Coming soon: cell
phones, PDAs, …
© NVIDIA Corporation 2008
GPU Computing Key Concepts
●
●
●
●
●
Hardware (HW) thread management
●
●
●
●
HW thread launch and monitoring
HW thread switching
Tens of thousands of lightweight, concurrent threads
Real threads: PC, private registers, …
SIMT execution model
Multiple memory scopes
●
●
●
Per-thread private memory
Per-thread-block shared memory
Global memory
Using threads to hide memory latency
Coarse grain thread synchronization
© NVIDIA Corporation 2008
SIMT Multithreaded Execution
●
SIMT: Single-Instruction Multi-Thread
executes one instruction across many
independent threads
●
Single-Instruction Multi-Thread
instruction scheduler
●
time
warp 8 instruction 11
●
warp 1 instruction 42
warp 3 instruction 95
..
.
warp 8 instruction 12
warp 3 instruction 96
© NVIDIA Corporation 2008
●
Warp: a set of 32 parallel threads
that execute a SIMT instruction
SIMT provides easy single-thread scalar
programming with SIMD efficiency
Hardware implements zero-overhead
warp and thread scheduling
SIMT threads can execute independently
●
●
SIMT warp diverges and converges when
threads branch independently
Best efficiency and performance when threads
of a warp execute together
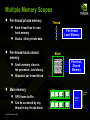
Multiple Memory Scopes
●
Per-thread private memory
●
●
●
●
●
Each thread has its own
local memory
Stacks, other private data
Per-thread-block shared
memory
●
Per-thread
Local Memory
Block
Per-block
Shared
Memory
Small memory close to
the processor, low latency
Allocated per thread block
Main memory
●
●
Thread
GPU frame buffer
Can be accessed by any
thread in any thread block
© NVIDIA Corporation 2008
Kernel 0
.
.
.
Kernel 1
...
Sequential
Blocks
Per-device
Global
Memory
Hiding LOAD Latency
●
●
Principle: Little’s Law:
N l L
●
●
●
W 0T1
Load Req
W 0T2
Load Req
W 0T0
Load Resp
W 0T1
Load Resp
W 0T2
Load Resp
Arrival Rate product of:
●
●
●
N = “number in flight”
l = arrival rate
L = memory latency
W 0T0
Load Req
Desired execution rate
(IPC)
Density of LOAD
instructions (%)
N = # of threads needed to
cover latency L
W kT29
Load Req
W kT30
Load Req
W kT31
Load Req
Time
© NVIDIA Corporation 2008
Hiding LOAD Latency w/ Fewer
Threads
● Use batching
● Group independent
●
LOADs together
Modified law:
N
lL
B
● B = batch size
© NVIDIA Corporation 2008
// batch size 3 example
float *d_A, *d_B, *d_C;
float a, b, c, result;
a = *d_A; b = *d_B; c = *d_C;
result = a * b + c;
●
●
The values ‘a’, ‘b’, and ‘c’ are
loaded independently before being
used
Implication is that we can execute
3 loads from one thread before the
first use (‘a’ in this case) causes a
stall
Thread Synchronization
●
Barrier synchronization among threads of block
●
●
●
●
●
●
Fast single-instruction barrier in Tesla GPUs
void __syncthreads();
Synchronizes all threads in a thread block
Once all threads have reached this point,
kernel execution resumes normally
Use before reading shared memory written by another
thread in the same block
Global synchronization between dependent kernels
●
●
Waits for all thread blocks of kernel grid to complete
Fast synchronization and kernel launch in Tesla GPUs
© NVIDIA Corporation 2008
10
Tesla Series
Products
The Tesla 8-Series Processor
NVIDIA’s 1st Generation CUDA Processor
● 681 million
●
●
●
●
transistors
518 Gigaflops
128 cores (SPs),
12288 threads max
384-bit 800 MHz
GDDR3
76 GB/sec peak
© NVIDIA Corporation 2008
The Tesla 10-Series Processor
NVIDIA’s 2nd Generation CUDA Processor
● 1.4 billion
●
●
●
●
transistors
1 Teraflop
240 cores (SPs),
30720 threads max
512-bit, 800MHz
GDDR3
102 GB/sec peak
© NVIDIA Corporation 2008
Tesla C1060 Computing Processor
© NVIDIA Corporation 2008
Processor
1 x Tesla T10
Number of cores
240
Core Clock
1.33 GHz
On-board memory
4.0 GB
Memory bandwidth
102 GB/sec peak
Memory I/O
512-bit, 800MHz GDDR3
Form factor
Full ATX: 4.736” x 10.5”
Dual slot wide
System I/O
PCIe x16 Gen2
Typical power
160 W
Tesla S1070 1U System
© NVIDIA Corporation 2008
Processors
4 x Tesla T10
Number of cores
960
Core Clock
1.5 GHz
Performance
4 Teraflops
Total system memory
16.0 GB
(4.0 GB per T10)
Memory bandwidth
408 GB/sec peak
(102 GB/sec per T10)
Memory I/O
2048-bit, 800MHz
GDDR3
(512-bit per T10)
Form factor
1U (EIA 19” rack)
System I/O
2 PCIe x16 Gen2
Typical power
700 W
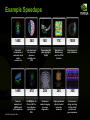
Example Speedups
146X
36X
Interactive
visualization of
volumetric white
matter
connectivity
Ionic placement
for molecular
dynamics
simulation on
GPU
149X
47X
Financial
simulation of
LIBOR model
with swaptions
© NVIDIA Corporation 2008
GLAME@lab: An
M-script API for
linear Algebra
operations on
GPU
18X
17X
100X
Simulation in
Matlab using
.mex file CUDA
function
Astrophysics Nbody simulation
20X
24X
30X
Ultrasound
medical imaging
for cancer
diagnostics
Highly optimized
object oriented
molecular
dynamics
Cmatch exact
string matching
to find similar
proteins and
gene sequences
Transcoding HD
video stream to
H.264
Example: Fluid Simulation
CUDA port of:
Jos Stam, "Stable Fluids", In SIGGRAPH 99 Conference Proceedings,
Annual Conference Series, August 1999, 121-128.
© NVIDIA Corporation 2008
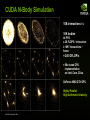
CUDA N-Body Simulation
10B interactions / s
16K bodies
44 FPS
x 20 FLOPS / interaction
x 16K2 interactions /
frame
= 240 GFLOP/s
= 50x tuned CPU
implementation
on Intel Core 2 Duo
GeForce 8800 GTX GPU
Highly Parallel
High Arithmetic Intensity
© NVIDIA Corporation 2008
N-Body Physics on CUDA
●
●
All-pairs gravitational N-body physics of 16,384 stars
240 GFLOPS on NVIDIA GeForce 8800 – see GPU Gems 3
© NVIDIA Corporation 2008
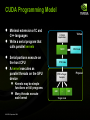
CUDA
CUDA Programming Model
●
●
●
●
Minimal extension of C and
C++ languages
Write a serial program that
calls parallel kernels
NVCC
Serial portions execute on
the host CPU
A kernel executes as
parallel threads on the GPU
device
●
●
Kernels may be simple
functions or full programs
Many threads execute
each kernel
© NVIDIA Corporation 2008
Virtual
C CUDA
Application
CPU Code
PTX Code
Physical
PTX to Target
Compiler
G80
…
Target code
GTX
CUDA Thread Model
●
Thread
●
Thread Block
t0 t1 t2 … tm
●
●
Grid
Thread
●
●
Computes result elements
threadIdx is thread id number
Thread Block
●
●
●
Computes result data Block
1 to 512 threads per Thread Block
blockIdx is block id number
Grid of Blocks
●
●
Computes many result blocks
1 to many blocks per grid
Sequential Grids
●
Compute sequential problem steps
Block 0 Block 1 Block 2
Block n
...
© NVIDIA Corporation 2008
CUDA: Basics
●
Declaration specifiers to indicate where things live
__global__
__device__
__device__
__shared__
●
void
void
int
int
KernelFunc(...);
DeviceFunc(...);
GlobalVar;
SharedVar;
// 500 blocks, 128 threads each
Special variables for thread identification in kernels
dim3 threadIdx;
●
kernel callable from host
function callable on device
variable in device memory
in per-block shared memory
Extend function invocation syntax for parallel kernel launch
KernelFunc<<<500, 128>>>(...);
●
//
//
//
//
dim3 blockIdx;
dim3 blockDim;
Intrinsics that expose specific operations in kernel code
__syncthreads();
© NVIDIA Corporation 2008
// barrier synchronization
CUDA: Extended Features
●
Standard mathematical functions
sinf, powf, atanf, ceil, etc.
●
Built-in vector types
float4, int4, uint4, etc. for dimensions 1..4
●
Atomics
atomicAdd(int *pmem; int value), etc.
add, sub, min, max, and, or, xor ...
●
Texture accesses in kernels
texture<float,2> my_texture; // declare texture reference
float4 texel = texfetch(my_texture, u, v);
© NVIDIA Corporation 2008
CUDA Memory Management
// allocate host memory
unsigned int numBytes = N * sizeof(float)
float* h_A = (float*) malloc(numBytes);
// allocate device memory
float* d_A = 0;
cudaMalloc((void**)&d_A, numbytes);
// copy data from host to device
cudaMemcpy(d_A, h_A, numBytes, cudaMemcpyHostToDevice);
// copy data from device back to host
cudaMemcpy(h_A, d_A, numBytes, cudaMemcpyDeviceToHost);
// free device memory
cudaFree(d_A);
© NVIDIA Corporation 2008
25
Example: Vector Addition Kernel
Device Code
// Compute vector sum C = A+B
// Each thread performs one pair-wise addition
__global__ void vecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
// Run N/256 blocks of 256 threads each
vecAdd<<< N/256, 256>>>(d_A, d_B, d_C);
}
© NVIDIA Corporation 2008
Example: Vector Addition Kernel
// Compute vector sum C = A+B
// Each thread performs one pair-wise addition
__global__ void vecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
C[i] = A[i] + B[i];
}
Host Code
int main()
{
// Run N/256 blocks of 256 threads each
vecAdd<<< N/256, 256>>>(d_A, d_B, d_C);
}
© NVIDIA Corporation 2008
Example: Host code for vecAdd
// allocate and initialize host (CPU) memory
float *h_A = …,
*h_B = …;
// allocate
float *d_A,
cudaMalloc(
cudaMalloc(
cudaMalloc(
device (GPU) memory
*d_B, *d_C;
(void**) &d_A, N * sizeof(float));
(void**) &d_B, N * sizeof(float));
(void**) &d_C, N * sizeof(float));
// copy host memory to device
cudaMemcpy( d_A, h_A, N * sizeof(float),
cudaMemcpyHostToDevice) );
cudaMemcpy( d_B, h_B, N * sizeof(float),
cudaMemcpyHostToDevice) );
// execute the kernel on N/256 blocks of 256 threads each
vecAdd<<<N/256, 256>>>(d_A, d_B, d_C);
© NVIDIA Corporation 2008
Example #2:
Adding matrices with 2D grids
CPU C program
CUDA C program
void addMatrix(float *a, float *b,
float *c, int N)
{
int i, j, index;
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
index = i + j * N;
c[index]=a[index] + b[index];
}
}
}
__global__
void addMatrix(float *a, float *b, float *c, int N)
{
int i=blockIdx.x*blockDim.x+threadIdx.x;
int j=blockIdx.y*blockDim.y+threadIdx.y;
int index = i + j * N;
if ( i < N && j < N)
c[index]= a[index] + b[index];
}
void main()
{
.....
addMatrix(a, b, c, N);
}
© NVIDIA Corporation 2008
void main()
{
.....
dim3 dimBlk (blocksize, blocksize);
dim3 dimGrd (N/dimBlk.x, N/dimBlk.y);
addMatrix<<<dimGrd,dimBlk>>>(a, b, c, N);
}
The SM:
Thread
Multiprocesor
Tesla 10-Series Architecture
●
●
Scales parallel performance 2X beyond Tesla 8-series
240 multithreaded thread processors at 1.5 GHz, 1 TFLOPS peak
Host CPU
Bridge
System Memory
Tesla T10
Work Distribution
``
``
SMC
``
SMC
``
SMC
``
SMC
``
SMC
``
SMC
``
SMC
``
SMC
``
SMC
SMC
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
I-Cache
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
MT Issue
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
C-Cache
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP ` SP
SP
SP
SP
SP
SP ` SP
SP
SP
SP
SP
SP ` SP
SP
SP
SP
SP
SP ` SP
SP
SP
SP
SP
SP ` SP
SP
SP
SP
SP
SP ` SP
SP
SP
SP
SP
SP ` SP
SP
SP
SP
SP
SP ` SP
SP
SP
SP
SP
SP ` SP
SP
SP
SP
SP
SP ` SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SFU SFU
SP
SFU SFU
SFU SFU
SFU SFU
SP
SFU SFU
SFU SFU
SFU SFU
SP
SFU SFU
SFU SFU
SFU SFU
SP
SFU SFU
SFU SFU
SFU SFU
SP
SFU SFU
SFU SFU
SFU SFU
SP
SFU SFU
SFU SFU
SFU SFU
SP
SFU SFU
SFU SFU
SFU SFU
SP
SFU SFU
SFU SFU
SFU SFU
SP
SFU SFU
SFU SFU
SFU SFU
SP
SFU SFU
SFU SFU
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
DP
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Shared
Memory
Texture Unit
Texture Unit
Texture Unit
Texture Unit
Texture Unit
Texture Unit
Texture Unit
Texture Unit
Texture Unit
Texture Unit
Tex L1
Tex L1
Tex L1
Tex L1
Tex L1
Tex L1
Tex L1
Tex L1
Tex L1
Tex L1
Interconnection Network
ROP
L2
ROP
DRAM
© NVIDIA Corporation 2008
L2
DRAM
ROP
L2
DRAM
ROP
L2
DRAM
ROP
L2
DRAM
ROP
L2
DRAM
ROP
L2
DRAM
ROP
L2
DRAM
T10 Multithreaded Multiprocessor
SM
I-Cache
●
●
MT Issue
C-Cache
SP SP
TPC
●
Geometry Controller
SMC
I-Cache
I-Cache
I-Cache
MT Issue
MT Issue
MT Issue
C-Cache
C-Cache
C-Cache
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SP
SFU SFU
SFU SFU
SFU SFU
DP
DP
DP
Shared
Memory
Shared
Memory
Shared
Memory
SP SP
SP SP
●
Texture Unit
Tex L1
SP SP
SFU SFU
●
DP
Shared
Memory
© NVIDIA Corporation 2008
●
Scalar register-based ISA
Multithreaded Instruction Unit
●
●
●
●
1024 threads, hardware multithreaded
32 SIMT warps of 32 threads
Independent thread execution
Hardware thread scheduling
8 SP Thread Processors
●
●
●
IEEE 754 32-bit floating point
32-bit and 64-bit integer
16K 32-bit registers
2 SFU Special Function Units
●
●
●
RCP, RSQRT, EXP2, LOG2, SIN, COS
2 SFUs per SM yields ¼ instruction throughput
Accuracy ranges from 22.5 to 24.0 bits
1 DP Double Precision Unit
●
●
●
IEEE 754 64-bit floating point
Fused multiply-add
Full-speed denormalized operands and results
16KB Shared Memory
●
●
Concurrent threads share data
Low latency load/store
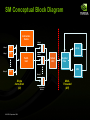
SM Conceptual Block Diagram
Instruction
Cache
Warp 0
Warp 0
PC
Warp 1
PC
ALUs
Warp 1
Fetch
Unit
Warp K
Sched
Unit
Register
Files
LSU
PC
Warp K
Single
Instruction
(SI)
© NVIDIA Corporation 2008
Instruction
Buffers
MultiThreaded
(MT)
Application
Performance
Limiter Theory
●
●
●
SM a form of queuing system
Use “limiter theory” to predict
SM performance
There are three types of limits
on the performance of the SM:
●
●
●
●
Bandwidth resource limiters
Per-thread-block space
limiters
Per-thread space limiters
The most constraining limiter
is called the critical limiter
●
= min(all limiters)
© NVIDIA Corporation 2008
Instruction
Cache
Warp 0
Warp 0
PC
Warp 1
PC
ALUs
Warp 1
Fetch
Unit
Warp K
Sched
Unit
Register
Files
LSU
PC
Warp K
Single
Instruction
(SI)
Instruction
Buffers
MultiThreaded
(MT)
Bandwidth Limiters
●
●
●
●
●
Thread blocks arrive at some rate λTB
Threads composed of some distribution of operations
Each arriving thread block of S threads contributes a
distribution of operations to be performed
Per operation type, the offered load, or BW DEMAND, is the
product of:
●
●
●
Thread block arrival rate λTB
# of threads S in a block
Operation density δ in each thread
BW CAPACITY is an upper bound on BW DEMAND
// Compute vector sum C = A+B
// Each thread performs one pair-wise addition
__global__ void vecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
C[i] = A[i] + B[i];
}
2
1
0
FADD
© NVIDIA Corporation 2008
IADD
IMUL
LOAD
STORE
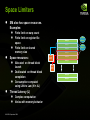
Space Limiters
●
SM also has space resources.
Examples:
●
●
●
●
Space resources:
●
●
●
●
Finite limit on warp count
Finite limit on register file
space
Finite limit on shared
memory size
Allocated on thread block
launch
Deallocated on thread block
completion
Consumption computed
using Little’s Law (N = λL)
Thread Latency (L)
●
●
Complex computation
Varies with memory behavior
© NVIDIA Corporation 2008
Warp 0
Warp 1
Warp 2
Warp 3
Registers,
Shared
Memory
Warp 4
Warp 5
Registers,
Shared
Memory
Warp 30
Warp 31
Thread
Block 0
Thread
Block 1
Limitations of Limiter Theory
● Limiter theory
●
●
assumes uniform
workloads
Breaks down if
“traffic jam”
behavior
Limiter theory is an
ok 1st order
approximation
// Compute vector sum C = A+B
// Each thread performs one pair-wise addition
__global__ void vecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
C[i] = A[i] + B[i];
}
2
1
0
FADD
IADD
IMUL
LOAD
STORE
Instruction
Cache
Warp 0
Warp 0
PC
Warp 1
PC
ALUs
Warp 1
Fetch
Unit
Warp K
Sched
Unit
Register
Files
LSU
PC
Warp K
Single
Instruction
(SI)
© NVIDIA Corporation 2008
Instruction
Buffers
MultiThreaded
(MT)
Implications of Limiter Theory
●
●
Kernel code has to pay careful attention to Operation “mix”
●
●
●
Don’t “freeway jam” kernel code
●
●
●
●
Math-to-memory operation ratios for example
Do not want to bottleneck on one function unit leaving other
units idling
Ideal: all units equally critical
Making thread blocks too large so that only a few execute on the
SM at a time a bad idea
“Bunching” operations of a similar type in one section of a
kernel will aggravate the problem
Ideal: lots of small thread blocks with uniform distribution of
operation densities
Focus on space resource consumption
●
Ideal: use as few resources necessary to “load the SM”
© NVIDIA Corporation 2008
Final Thoughts
●
●
●
Threads are free
●
●
●
●
●
●
A common mistake in GPU Computing kernels is to make
threads do too much
Keep them short and sweet
Example: one thread per vector element
HW provides LOTs of them (10s of thousands)
HW launch => near zero overhead to create them
HW context switching => near zero overhead scheduling
Barriers are cheap
●
●
●
●
Single instruction
HW synchronization of thread blocks
Partition kernel code into producer-consumer
DON’T use spin locks!
Partition on results, not sources
© NVIDIA Corporation 2008
Questions?
[email protected]
http://www.nvidia.com/CUDA
http://www.nvidia.com/TESLA