Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
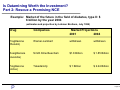
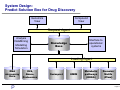
Data Mining as Method to Streamline the Drug Discovery Process Markus Duerring, Predict AG [email protected] http://www.predict.ch P Page 1 Predict AG – Architect for Business Analytical Systems Predict AG • Founded 1998 • Independent corporation • Grown to 30 people • Customers in Finance, Telco, Retail, Pharma Staff Technology Services Know-How combination of and its application in business processes Projects that fit your information needs Experience Knowledge Management Award winning Projects Data Mining Certified SAS Quality Partner Business Data Analysis IT P Decision Support Systems Systems Integration Page 2 The Starting Point: The TheraStrat SafeBase Project Correlation of patterns of genetic polymorphisms and gene expression with drug-induced adverse effects and drug structure. Structures Parent Intermediates Metabolites Adducts Targets Mimics Pathways Structures Similarities Type P Clinical Endpoint Type Frequency Severity Which drug Which population Expression Genes Receptors Promotors Transcriptionfactors Responsive elements Frequencies patterns Function 3D-Structure Adduct target Autoantigen Allelic Variants SNPs Splice Variants Amplifications Functions 3D-Structure Ethnic differences Selectivity Sensitivity Page 3 The Situation: Recent Market Withdrawals or Suspended Development Name Substance Company Therapeutic Area Reaction Posicor Mibefradil Roche Cardiovascular Underestimated effect of Drug/Drug interactions Trovan Trovaflocin Pfizer Antibiotic Unexpected severe liver toxicity with deaths, call for ban of product. Zagam Sparfolxacin RPR Antibiotic Severe phototoxicity and cardiotoxicity. Limited for use in pneumonia in EU. Tempium Lazabemide Roche Alzheimer Severe liver toxicity in Phase III Development aborted Rezulin Warner-Lambert Diabetes II Severe liver toxicity with deaths, withdrawn from the market. P Troglitazone Page 4 Is it Possible to Avoid Adverse Drug Effects? Conventional analysis is not applicable because 1. Amount of data is too large 2. Incidence rate is very low • Increase number of patients to test (The „brute-force“ method) • Use past experience to build consolidated learning sets that allow functional compound profiling of NCE’s (The datamining method) P Page 5 Avoiding Adverse Effects (ADE): The „Brute-Force“ Method - Sample size n = 5000 phase III patients - Incidence rate p = 1/10‘000 - How likely do we encounter an ADE in our safety samples? Probability for at least one occurrence of one ADE in the sample: 1-p(X=0) = 1-exp(-1/2) = 1-0.607 = 0.293 - Estimator l of the Poisson Distribution: l=0.5*2.336=1.183 - upper 0.9-confidence limit for l = 0.5*7.779=3.38895 For n=10‘000, the estimated p:1/8453 Required sample size with upper 0.9 confidence limit for p < 1/10‘000 = 38‘896 P Page 6 Avoiding Adverse Effects: The Datamining Method Deductive Reporting Inductive Reporting • OLAP • Data Mining • Transaction systems • Analytical systems • Retrospective data analysis • Scoring compounds • Known dimensions • Search for new dimensions I.e. Reporting all biological I.e. Prediction of the and chemical results potential risk for a of a given compound new compound P Page 7 Where Datamining makes Sense in the R&D Process? Number of Compounds Development P Drug Discovery Process Research Information per Compound SAR Report Page 8 Is Datamining Worth the Investment? Part One: Identify risky compounds earlier Assuming your scoring model predicts a substance with a potential ADE Development Step Cost (Mio $) No. substances (Ordinary) No. substances (Data Mining) Cost Reduction Lead compound selection 10 300‘000 299‘999 0 Discovery testing 20 300 299 0 Stability and formulation 20 20 19 1 Safety testing 60 10 9 6 Scale-up, Process setup 80 6 5 14 Phase I trials 10 5 4 2 Phase II trials 20 2 1 10 Phase III + IV trials 80 1 0 80 Total P 300 113 Page 9 Is Datamining Worth the Investment? Part 2: Rescue a Promising NCE Example: Market of the future in the field of diabetes, type II: $ 6 billion by the year 2004 (estimates and projection by Lehman Brothers, July 1999) Drug Companies Market Projections 2001 2004 Troglitazone (Rezulin) Warner-Lambert withdrawn withdrawn Rosiglitazone (Avendia) Smith Kline Beecham $1.8 Billion $ 1.85 Billion Pioglitazone (Actos) Takeda/Lilly $ 1 Billion $ 2.24 Billion P Page 10 System Design: Predict Solution Box for Drug Discovery Genomics View Compound View Request Agent Analysis DataMining Modelling Simulation Interface to operational systems Knowledge Base Loading Agent DNA microarray Data P ISIS, Abase, Proteomics Swissprot OMIM Metabolic pathways (KEGG) Domains Motifs (Pfam) Page 11 Linking Your Own Data with External Data: The Affymetrix Data Quality Challenge • Experiment sample and experiment controls are not on the same chip. • Standards across individual chips are rarely used. • Housekeeping genes are often not of sufficient stability to be used as mean for normalisation. • Total fluorescense per chip is used for scaling, assuming that the difference between control and sample is small. • Using further normalisation parameters (Positive ration, pos/neg ratio, Log Avg ratio, etc). for more reliable normalisation? P Page 12 Validating the System: Using DNA Gyrase as Model Target • • DNA Gyrase is an essential prokaryotic type II DNA topoisomerase Involved in many biological processes, e.g. fi DNA replication fi Gene expression fi Recombination P Page 13 Experiment Setup • • • • • • P Novobiocin: 0, 12.5 and 125 µg/ml Ciprofloxacin: 0, 30 and 300 µg/ml Time points: 10, 30 and 60 min RNA isolation DNA microarray (Affymetrix) Fluorescent signals detected by scanning confocal microscopy Page 14 DNA Microarray Results • ~ 2000 H. influenzae genes • In parallel proteins analyzed with 2-D gels (proteomics) P Page 15 DNA Gyrase Data Analysis • Comparison of experiments (antibiotic exposure) versus controls (no antibiotics) (Affymetrix algorithm) • SAS macros to – Import of 37 files into SAS 4870 rows and 36 columns each – Reformat and recalculate variables if necessary – Merge result-files and files containing gene - or protein - or metabolic pathways descriptions – Filtering of data P Page 16 Clustering and Visualisation • Table analyzed in SAS Enterprise Miner - Clustering by Average linkage method or K-means algorithm - Analysis variables = Fold Changes • Visualization by TreeView (Eisen) green = downregulated red = upregulated P Page 17 Linking External Information: Results from Ciprofloxacin Exposure P Page 18 Conclusions • Scoring of NCE‘s can be a valuable method to streamline the overall R&D process • If value in the overall R&D process shall be generated, the correlation of genetic, biological and chemical data must be taken into consideration • The Key success factor to use datamining as a method to streamline the drug discovery process is the consolidation, the normalization and the quality of your data P Page 19 Acknowledgements TheraSTrat AG • Prof. Dr. Joseph Gut, CSO Predict AG • Dr. Patrick Schünemann, CEO • Dr. Hans Gmünder, Datamining Consultant • Thomas Nawrath, Datamining Consultant P Page 20