Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
COMP3740 CR32:
Knowledge Management
and Adaptive Systems
Data Mining outputs:
What “knowledge” can Data Mining learn?
By Eric Atwell, School of Computing,
University of Leeds
(including re-use of teaching resources from other sources, esp.
Knowledge Management by Stuart Roberts,
School of Computing, University of Leeds)
Data Mining, Knowledge Discovery,
Text Mining
• Data mining is about discovering “knowledge”: patterns,
correlations, predictive rules in a large data-set or corpus.
• For this we need:
– Data mining techniques, algorithms, tools, eg WEKA, R, MatLab, …
– A methodological framework to guide us in collecting data and finding
“useful” models, CRISP-DM
• Data Mining was originally about “learning” patterns from
DataBases, data structured as Records, Fields
• Knowledge Discovery is “exotic term” for DM???
• Increasingly, data is unstructured text (WWW), so
• Text Mining is a new subfield of DM/KD, focussing on
Knowledge Discovery from unstructured text data
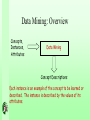
Data Mining: Overview
Concepts,
Instances,
Attributes
Data Mining
Concept Descriptions
Each instance is an example of the concept to be learned or
described. The instance is described by the values of its
attributes.
instances
• Input to a data mining algorithm is in the form of
a set of examples, or instances.
• Each instance is represented as a set of features or
attributes.
• Usually this set takes the form of a flat file; each
instance is a record in the file, each attribute is a
field in the record.
• In text-mining, instance is word/term in a corpus.
• The concepts to be learned are formed from
patterns discovered within the set of instances.
concepts
The types of concepts we try to ‘learn’ include:
• Key “differences” between 2 (or more) data-sets
– Eg difference in sales by region this year compared to previous
- Eg terms important in one corpus but not another
• Clusters or ‘Natural’ partitions;
– Eg cluster customers according to their shopping habits;
- Eg semantic clusters: “synonyms” with similar COLLOCATIONS
• Rules for classifying examples into pre-defined classes.
–
-
Eg successful PhD student?: Mature student, IS, AI3n, 2i/1st => PhD
Eg predicting Part-of-Speech word-class of each word in a corpus:
Adj + X + Verb => X=Noun;
“to” + X + Adverb => X=Verb
More concepts
The types of concepts we try to ‘learn’ include:
• General Associations
– Eg “People who buy nappies are in general likely to also buy beer”
- Eg high-frequency terms tend to be “grammatical”, not “meaningful”
• Numerical prediction
– Eg look for rules to predict what salary a graduate will get, given A
level results, age, gender, programme of study and degree result – this
may give us an equation:
Salary = a*A-level + b*Age + c*Gender + d*Prog + e*Degree
DB Example: weather to play?
/usr/local/weka-3-4-5/data/weather.arff
@relation weather
@attribute outlook {sunny,overcast,rainy}
@attribute temperature real
@attribute humidity real
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
@data
sunny,85,85,FALSE,no
sunny,80,90,TRUE,no
overcast,83,86,FALSE,yes
rainy,70,96,FALSE,yes
rainy,68,80,FALSE,yes
rainy,65,70,TRUE,no
overcast,64,65,TRUE,yes
sunny,72,95,FALSE,no
sunny,69,70,FALSE,yes
rainy,75,80,FALSE,yes
In general, any DB records can be ARFFed
• Save records as plain text
file, comma-separated
values (csv format)
• Add HEADER:
@relation <filename>
@attribute <name><type>
@attribute<name><type>
…
@data
… then the data (instances)
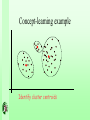
Concept-learning example
Start with set of instances
Use clustering algorithm to
partition set
Concept-learning example
Identify cluster centroids
Concept-learning example
Clusters, represented by centroids are the learned
concepts
Example use of clustering
• Point of sale data contains information about the buyer
and the ‘basket’.
• We want to target advertising to different types of
shopper.
• Cluster analysis groups shoppers into classes, each with
distinctive characteristics.
• Cluster characteristics are examined to interpret what
kind of advertising each group will respond to.
• Groups then related to where they live.
Output: Clusters
• Output can take the form of:
– Classification of each instance according to the cluster
number/name (like a dictionary/thesaurus)
– Cluster centroids
– Dendrogram depicting hierarchical partitioning:
x
c
f
y
d
p
o
k
a
e m b
l
s
Example use: comparing data-sets
•
•
•
•
•
•
•
•
Finding specialist terms, UK v US?
Compare this month’s data with last month’s
Compare with several previous months
Notice new sales growth areas
Trends – rise, fall, cyclical (eg turkey sales?)
Key differences may denote clusters (eg ise/ize)
“size/scale” of difference
“Aligned”, “parallel” corpora used in Statistical
Machine Translation, eg Google Translate
Output: differences between data-sets
• Key instances/attributes with most significant
difference, eg highest Log-Likelihood score
• Groups or clusters of significant terms, eg names
• Trends over several data-sets: graphs
• Overall metrics of difference
Example use of classifying
• A large database of symptoms and diagnoses is available
from medical records.
• We seek rules that will predict which disease someone
has, given their symptoms.
Or
• Given information about physical environment and crop
yields – seek rules that will help us understand why some
areas give higher yields than others.
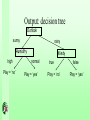
Output: decision tree
Outlook
sunny
rainy
Humidity
high
Play = ‘no’
Windy
normal
Play = ‘yes’
true
Play = ‘no’
false
Play = ‘yes’
About decision trees
• Non-leaf node represents a test on a particular attribute.
• Arcs represent the outcomes of the test.
• Tests on numerical attributes usually have binary
outcome
• Tests on nominal attributes usually have one outcome for
each element in the domain.
• The leaf nodes represent a class.
• Each path down the tree represents a prediction for
assigning instances to classes
Output: classification rules
If outlook = sunny and humidity = high then play = no
If outlook = rainy and windy = true
then play = no
If outlook = overcast
then play = yes
If humidity = normal
then play = yes
Default
play = yes
About Classification rules
• Alternative to decision trees:
– If <antecedent> then <consequent>
– Consequent indicates a class.
– Usually the antecedent is a conjunction of conditions on attribute
values.
– Usually we interpret the set of rules to be a disjunction of the
individual rules.
• Evaluation: Accuracy of a rule:
– Ratio of number of instances it predicts correctly to total number of
instances that match the antecedent.
• Advantages of rules:
– Easier to read than trees
– Can be more compact
– Each rule represents a ‘nugget’ of knowledge, with its own accuracy
A variant: rules with exceptions
• General form:
– If A then B except if C then D
• Advantages:
– Can be more compact than rules without exceptions
– Closer to the way we organise our knowledge
– Scales well as new instances are introduced.
Output: association rules
• Given point of sales data, seek any kind of
dependencies between data items that will help us
understand shopping behaviour.
“People who live by the sea and buy pet food go
on fewer holidays”
• ‘Learned’ rules may or may not be interesting!
About association rules
• Similar to classification rules, but now consequent
can predict any attribute, not just the class.
• Evaluation: Coverage (or support) of a rule:
– The number of instances it correctly predicts
• Evaluation: Accuracy (or confidence) of a rule:
– Ratio of number of instances it predicts correctly to
total number of instances that match the antecedent.
Output: numerical prediction
•
•
•
•
Best-fit equation
e.g.linear: length = a + b*width + c*height
Widely used in maths and stats
?not “really” data mining?
Example use of numerical prediction
• Given numerical information about physical
environment and crop yields – seek rules that will
help us predict crop yields for some new set of
conditions.
Key points
• Data Mining tools semi-automate the process of
discovering patterns in data.
• Tools differ in terms of what concepts they
discover (differences, clusters, decision-trees,
rules, numerical prediction)…
• … and in terms of the output they provide (eg
clustering algorithms provide a set of centroids or
a dendrogram)
• Selecting the right tools for the job is based on
business objectives: what is the USE for the
knowledge discovered
Self-test
• You should be able to:
– Decide what attributes are relevant to the given data
mining task
– Decide which is the appropriate data mining technique
for a given a problem defined in terms of business
objectives.
– Decide which is the most appropriate form of output.