Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
CSC242: Intro to AI
Lecture 22
Administrivia
Posters! Tue Apr 24 and Thu Apr 26
Idea!
Presentation!
2-wide x 8-high landscape pages
Learning Probabilistic
Models
Supervised Learning
• Given a training set of N example inputoutput pairs:
(x1, y1), (x2, y2), ..., (xN, yN)
where each yj = f(xj)
• Discover function h that approximates f
Linear Classifiers
• Linear regression for fitting a line to data
• Linear classifiers: use a line to separate the data
• Gradient descent for finding weights
• Hard threshold (perceptron learning rule)
• Logistic (sigmoid) threshold
• Neural Networks: Network of linear classifiers
• Support Vector Machines: State of the art for
learning supervised learning of classifiers
Learning Probabilistic
Models
100% cherry
75% cherry
25% lime
50% cherry
50% lime
25% cherry
75% lime
100% lime
h1
h2
h3
h4
h5
H ∈ {h1 , h2 , h3 , h4 , h5 }
Observations: D1=
D2=
D3=
Goal: Predict the flavor of the next candy
...
D1=
D2=
Bags
Agent, process, disease, ...
Candies
Actions, effects, symptoms,
results of tests, ...
Observations
D3=
Goal
Predict next Predict agent’s next move
candy
Predict next output of process
Predict disease given symptoms
and tests
H ∈ {h1 , h2 , h3 , h4 , h5 }
Observations: D1=
D2=
D3=
Goal: Predict the flavor of the next candy
...
Strategy 1
• Predict (estimate) the underlying
distribution hi
• Use that to predict the next observation
Bayesian
Strategy
Learning
2
• Compute the probability of each hypothesis
distribution
• Use that to compute a weighted estimate
of the possible values for the next
observation
Bayesian Learning
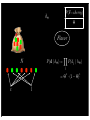
P (hi | d) = αP (d | hi )P (hi )
Likelihood of the data
under the hypothesis
Hypothesis prior
Bayesian
Learning
Likelihood of disease
given symptoms/tests
P (hi | d) = αP (d | hi )P (hi )
Likelihood that the disease
caused the symptoms/tests
Prior probability
of the disease
Bayesian Learning
P (hi | d) = αP (d | hi )P (hi )
Likelihood of the data
under the hypothesis
Hypothesis prior
h1
h2
h3
h4
P(H) = �0.1, 0.2, 0.4, 0.2, 0.1�
h5
h1
h2
h3
h4
h5
P(H) = �0.1, 0.2, 0.4, 0.2, 0.1�
P (d | hi ) =
�
j
P (dj | hi )
if i.i.d.
Independent Identically
Distributed (i.i.d.)
• Probability of a sample is independent of
any previous samples
P(Di |Di−1 , Di−2 , . . .) = P(Di )
• Probability distribution doesn’t change
among samples
P(Di ) = P(Di−1 ) = P(Di−2 ) = · · ·
h1
h2
h3
h4
h5
P(H) = �0.1, 0.2, 0.4, 0.2, 0.1�
P (d | hi ) =
�
j
P (dj | hi )
if i.i.d.
d
P (d | hi )
h1
0
h2
0.2510
h3
0.510
h4
0.7510
h5
1
P (hi | d) = αP (d | hi )P (hi )
Posterior probability of hypothesis
P(H) = �0.1, 0.2, 0.4, 0.2, 0.1�
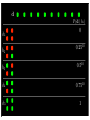
1
P(h1 | d)
P(h2 | d)
P(h3 | d)
P(h4 | d)
P(h5 | d)
0.8
0.6
0.4
0.2
0
0
2
4
6
8
Number of observations in d
10
Bayesian Prediction
P(DN +1 | d) =
=
�
i
�
i
=α
P(DN +1 | d, hi )P(hi | d)
P(DN +1 | hi )P(hi | d)
�
i
P(DN +1 | hi )P (d | hi )P (hi )
Probability that next candy is lime
1
0.9
0.8
0.7
0.6
0.5
0.4
0
2
4
6
8
Number of observations in d
P (dN +1 = lime | d1 , . . . , dN )
10
Bayesian Learning
P(X | d) = α
�
i
P(X | hi )P (d | hi )P (hi )
Maximum A Posteriori
(MAP)
hMAP = argmax P (hi | d)
hi
P(X | d) ≈ P(X | hMAP )
Probability that next candy is lime
1
0.9
0.8
0.7
0.6
0.5
0.4
0
2
4
6
8
Number of observations in d
P (dN +1 = lime | d1 , . . . , dN )
10
Maximum A Posteriori
(MAP)
hMAP = argmax P (hi | d)
hi
P(X | d) ≈ P(X | hMAP )
What About
Overfitting?
• Expressive hypothesis space allows many
hypotheses that fit the data well
• Solution: Use hypothesis prior to penalize
complexity
• Usually more complex hypotheses have a
lower prior probability than simple ones
Maximum Likelihood
Hypothesis
• Assume uniform hypothesis prior
• No hypothesis preferred to any other a
priori (e.g., all equally complex)
hMAP = argmax P (hi | d)
hi
= argmax P (d | hi ) = hML
hi
Statistical Learning
• Bayesian Learning
• Hypothesis prior
• Likelihood of data given hypothesis
• Weighted average over all hypotheses
• MAP hypothesis: single best hypothesis
• ML hypothesis: uniform hypothesis prior
h1
h2
h3
h4
P(H) = �0.1, 0.2, 0.4, 0.2, 0.1�
h5
D1=
D2=
Bags
Agent, process, disease, ...
Candies
Actions, effects, symptoms,
results of tests, ...
Observations
D3=
Goal
Predict next Predict agent’s next move
candy
Predict next output of process
Predict disease given symptoms
and tests
Bayesian Networks
• A Bayesian network represents a full joint
probability distribution between a set of
random variables
• Uses conditional independence to reduce
the number of probabilities need to specify
it and make inference easier
Learning and Bayesian
Networks
• The distribution defined by the network is
parameterized by the entries in the CPTs
associated with the nodes
• A BN defines a space of distributions
corresponding to the parameter space
Learning and Bayesian
Networks
• If we have a BN that we believe represents
the causality (conditional independence) in
our problem
• In order to find (estimate) the true
distribution
• We learn to find the parameters of the
model from the training data
Burglary
JohnCalls
P(B)
.001
Earthquake
Alarm
B
t
t
f
f
A P(J)
t
f
.90
.05
E
t
f
t
f
P(E)
.002
P(A)
.95
.94
.29
.001
MaryCalls
A P(M)
t
f
.70
.01
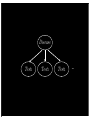
Parameter Learning
(in Bayesian Networks)
hΘ
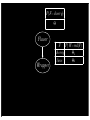
P(F=cherry)
Θ
Flavor
P(F=cherry)
hΘ
Θ
Flavor
N
P (d | hΘ ) =
�
j
P (dj | hΘ )
= Θc · (1 − Θ)l
c
l
Maximum Likelihood
Hypothesis
argmax P (d | hΘ )
Θ
Log Likelihood
P (d | hΘ ) =
�
j
P (dj | hΘ )
= Θc · (1 − Θ)l
L(d | hΘ ) = log P (d | hΘ ) =
�
j
log P (dj | hΘ )
= c log Θ + l log(1 − Θ)
Maximum Likelihood
Hypothesis
L(d | hΘ ) = c log Θ + l log(1 − Θ)
c
c
=
argmax L(d | hΘ ) =
c+l
N
Θ
Flavor
Wrapper
P(F=cherry)
Θ
Flavor
Wrapper
F P(W=red|F)
cherry
Θ1
lime
Θ2
hΘ,Θ1 ,Θ2
P(F=cherry)
Θ
Flavor
Wrapper
F P(W=red|F)
cherry
Θ1
lime
Θ2
P(F=cherry)
hΘ,Θ1 ,Θ2
Θ
Flavor
Wrapper
F P(W=red|F)
cherry
Θ1
lime
Θ2
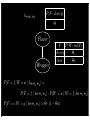
P (F = f, W = w | hΘ,Θ1 ,Θ2 ) =
P (F = f | hΘ,Θ1 ,Θ2 ) · P (W = w | W = f, hΘ,Θ1 ,Θ2 )
P (F = c, W = g | hΘ,Θ1 ,Θ2 ) = Θ · (1 − Θ1 )
F
W
P(F=f,W=w| hΘ,Θ1,Θ2)
cherry
red
Θ Θ1
cherry
green
Θ (1-Θ1)
lime
red
(1-Θ) Θ2
lime
green
(1-Θ) (1-Θ2)
N
c
rc
l
gc
rl
gl
F
W
P
N=c+l
cherry
red
Θ Θ1
rc
cherry
green
Θ (1-Θ1)
gc
lime
red
(1-Θ) Θ2
rl
lime
green
(1-Θ) (1-Θ2)
gl
F
W
P
N=c+l P (d | hΘ,Θ1 ,Θ2 )
cherry
red
Θ Θ1
rc
(ΘΘ1 )rc
cherry
green
Θ (1-Θ1)
gc
(Θ(1 − Θ1 ))gc
lime
red
(1-Θ) Θ2
rl
((1 − Θ)Θ2 )rl
rl
((1 − Θ)(1 − Θ2 ))gl
lime
green
(1-Θ) (1-Θ2)
P (d | hΘ,Θ1 ,Θ2 ) =
(ΘΘ1 )rc · (Θ(1 − Θ1 ))gc · ((1 − Θ)Θ2 )rl · ((1 − Θ)(1 − Θ2 ))gl
= Θc (1 − Θ)l · Θr1c (1 − Θ1 )gc · Θr2l (1 − Θ2 )gl
L(d | hΘ,Θ1 ,Θ2 ) = c log Θ + l log(1 − Θ)+
[rc log Θ1 + gc log(1 − Θ1 )]+
[rl log Θ2 + gl log(1 − Θ2 )]
c
c
=
Θ=
c+l
N
rc
rc
Θ1 =
=
rc + g c
c
rl
rl
Θ2 =
=
rl + g l
l
hΘ,Θ1 ,Θ2
P(F=cherry)
Θ
Flavor
Wrapper
F P(W=red|F)
cherry
Θ1
lime
Θ2
c
c
=
Θ=
c+l
N
rc
rc
Θ1 =
=
rc + g c
c
rl
rl
Θ2 =
=
rl + g l
l
argmax L(d | hΘ,Θ1 ,Θ2 ) = argmax P (d | hΘ,Θ1 ,Θ2 )
Θ,Θ1 ,Θ2
Θ,Θ1 ,Θ2
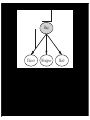
Naive Bayes Models
Class
Attr1
Attr2
Attr3
...
Naive Bayes Models
{ mammal, reptile, fish, ... }
Class
Furry
Warm
Blooded
Size
...
Naive Bayes Models
Class
Attr1
Attr2
Attr3
...
Naive Bayes Models
{ mammal, reptile, fish, ... }
Class
Furry
Warm
Blooded
Size
...
Naive Bayes Models
{ terrorist, tourist }
Class
Arrival
Mode
One-way
Ticket
Furtive
Manner
...
Naive Bayes Models
Disease
Test1
Test2
Test3
...
Learning Naive Bayes
Models
• Naive Bayes model with n Boolean
attributes requires 2n+1 parameters
• Maximum likelihood hypothesis h
ML
found with no search
• Scales to large problems
• Robust to noisy or missing data
can be
Learning with
Complete Data
• Can learn the CPTs for a Bayes Net from
observations that include values for all
variables
• Finding maximum likelihood parameters
decomposes into separate problems, one
for each parameter
• Parameter values for a variable given its
parents are the observed frequencies
• 20.2.3: Maximum likelihood parameter
learning: Continuous models
• 20.2.4: Bayesian parameter learning
• 20.2.5: Learning Bayes net structure
• 20.2.6: Density estimation with
nonparametric models
{ terrorist, tourist }
Class
Arrival
Mode
One-way
Ticket
Furtive
Manner
...
Arrival One-Way Furtive
...
Class
taxi
yes
very
...
terrorist
car
no
none
...
tourist
car
yes
very
...
terrorist
car
yes
some
...
tourist
walk
yes
none
...
student
bus
no
some
...
tourist
Disease
Test1
Test2
Test3
...
Test
Test2
Test3
...
Disease
T
F
T
...
?
T
F
F
...
?
F
F
T
...
?
T
T
T
...
?
F
T
F
...
?
T
F
T
...
?
2
Smoking
2
Diet
2
Exercise
2
Smoking
2
Diet
2
Exercise
54 HeartDisease
6
Symptom 1
6
Symptom 2
6
Symptom 3
(a)
78 parameters
54
Symptom 1
162
Symptom 2
486
Symptom 3
(b)
708 parameters
Hidden (Latent)
Variables
• Can dramatically reduce the number of
parameters required to specify a Bayes net
• Reduces amount of data required to
learn the parameters
• Values of hidden variables not present in
training data (observations)
• “Complicates” the learning problem
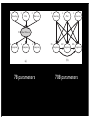
EM
Expectation-Maximization
• Repeat
• Expectation: “Pretend” we know the
parameters and compute (or estimate)
likelihood of data given model
• Maximization: Recompute parameters
using expected values as if they were
observed values
• Until convergence
Flavor
cherry
lime
Wrapper
red
green
Hole
true
false
P(F,W,H)
Flavor
cherry
Wrapper
red
green
lime
red
green
Hole
t
f
t
f
t
f
t
f
P(f,w,h)
pc,r,t
pc,r,f
pc,g,t
pc,g,f
pl,r,t
pl,r,f
pl,g,t
pl,g,f
P1(F,W,H)
P2(F,W,H)
Lorem ipsum dolor sit amet, consectetur adipiscing
elit. Etiam euismod euismod facilisis. Aliquam erat
volutpat. Maecenas nisl ligula, dignissim et volutpat
ac, pharetra blandit augue. Maecenas id ligula in leo
tristique viverra. Curabitur lacinia nulla in nibh
bibendum laoreet. Morbi a est mi, mattis imperdiet
risus. Quisque quam felis, facilisis ac semper vel,
viverra vitae nulla. Donec nisl lectus, faucibus
vehicula tincidunt nec, ultrices nec eros. Proin non
felis nec urna pellentesque tempor at sit amet est.
P1(X1,X2,X3)
P2(X1,X2,X3)
P(F,W,H)
Flavor
cherry
Wrapper
red
green
lime
red
green
Hole
t
f
t
f
t
f
t
f
P(f,w,h)
pc,r,t
pc,r,f
pc,g,t
pc,g,f
pl,r,t
pl,r,f
pl,g,t
pl,g,f
P(Bag=1)
θ
Bag P(F=cherry | B)
1
θF1
2
θF2
Flavor
Bag
Wrapper
(a)
C
Hole
X
(b)
P(Bag=1)
θ
Bag
Bag P(F=cherry | B)
1
θF1
2
θF2
Flavor
Wrapper
(a)
Bag P(W=red|B)
C
X
Hole
(b)
Bag P(H=true|B)
1
ΘW1
1
ΘH1
2
ΘW2
2
ΘH2
P(Bag=1)
θ
Bag
Bag P(F=cherry | B)
1
θF1
2
θF2
Flavor
C
Wrapper
(a)
Bag P(W=red|B)
X
Hole
Bag P(H=true|B)
1
ΘW1
1
ΘH1
2
ΘW2
2
ΘH2
(b)
Flavor
Wrapper
Hole
Bag
cherry
red
true
?
cherry
red
true
?
lime
green
false
?
cherry
green
true
?
lime
green
true
?
cherry
red
false
?
lime
red
true
?
N=1000
W=red
W=green
H=1
H=0
H=1
H=0
F=cherry
273
93
104
90
F=lime
79
100
94
167
EM
Expectation-Maximization
• Repeat
• E: Use the current values of the
parameters to compute the expected
values of the hidden variables
• M: Recompute the parameters to
maximize the log-likelihood of the data
given the values of the variables
(observed and hidden)
EM
Expectation-Maximization
• Repeat
• E: Use the current values of the
parameters to compute the expected
values of the hidden variables
• M: Recompute the parameters to
maximize the log-likelihood of the data
given the values of the variables
(observed and hidden)
Summary
• Statistical Learning
• Bayesian Learning
• Maximum A Posteriori (MAP) hypothesis
• Maximum Likelihood (ML) hypothesis
• Learning the parameters of a Bayesian Network
• Complete data: Maximum Likelihood learning
• Hidden variables: EM
For Next Time:
21.0-21.3; 21.5 fyi
Posters!