Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Algorithms for Mining
Association Rules
인공지능 연구실
석사 2학기 김 민 정
목차
Association Rule 정의
연관규칙탐사과정
Algorithms for Mining Association Rules
Reference
Algorithm Apriori & DHP
연관규칙 알고리즘 변형
Mining Generalized Association Rules (Srikant et al., VLDB, Sept ‘95)
Mining Association Rules with Item Constraints (Srikant et al., AAAI, 1997)
Cyclic Association Rules (zden et al., IEEE ICDE, Feb ‘98)
Data-mining product
연구 방향과 이용
Association Rule
연관규칙
- 대용량 데이타베이스 내의 단위 트랜잭션에서 빈번하게
발생하는 사건의 유형을 발견
예
“전체 고객 중에 빵과 우유, 그리고 쥬스를 구매한 고객이 10% 이상이고,
‘빵과 우유’를 구매한 고객의 50%가 쥬스도 함께 구매한다. “
{빵, 우유} {쥬스}
antecedent
consequent
10% : 연관규칙의 지지도(support )
50% : 연관규칙의 신뢰도(confidence)
연관규칙탐사과정
Focus on data structures to
speed up scanning the database (탐색공간의 축소문제)
Hash tree, Hash table, etc.
Candidate Itemsets
How to generate
candidate itemsets
Apriori method:
join step + prune step
minimum support
Large itemsets
Scan
Database
minimum
confidence
Association Rules
Algorithms for Association Rule (1/3)
연관규칙 탐사 과정
1. finding Large itemsets
트랜잭션을 대상으로 최소지지도 이상을 만족하는 빈발항목집합을
발견하는 과정에 초점을 둘 알고리즘
- AIS
- SETM
- Apriori / AprioriTid / AprioriHybrid
- DHP (Direct Hashing and Pruning)
- Partition
- Sampling Approach
- DIC (Dynamic Itemset Counting)
Algorithms for Association Rule (2/3)
2. Generating Association rules
발견된 다량 항목 집합 내에 포함된 항목들 중에서 최소신뢰도 이상을
만족하는 항목들 간의 연관규칙을 생성하는 단계
2.1)
- Generalized association rule
- Sequential Pattern
- ...etc
Algorithms for Association Rule (3/3)
2.2) 탐사하는 연관규칙의 조건부나 결과부에 제한을 준 상황에서 빠르게
연관규칙을 찾아
내는 방법
- Cyclic Association Rule
- Negative Associations
- Mining Association Rules with Item Constraints
- ...etc
(전체 항목집합 I에 m개의 항목이 존재한다면 트랜잭션에 포함될 수 있는
부분 항목열의 경우의 수는 최대 2의 m승 개까지 가능하다.)
즉, 다량 항목 집합의 선정을 위한 데이터베이스 탐색 공간의 축소가
연관규칙의 탐사
과정에서 가장 중요한 문제로 인식되고 있다. (1. finding Large itemsets)
Reference (1/4)
introduced by Agrawal
[1]
"Mining association rules between sets of items in large
databases"
- 연관규칙이 처음 소개. AIS Algorithm
R. Agrawal, T. Imielinski, and A. Swami. Mining association rules between
sets of items in large databases. In Proc. of the ACM SIGMOD
Conference on Management of Data, Washington, D.C., May 1993
"Set-oriented mining of association rules" - SETM
M. houtsma and A. Swami. Set-oriented mining of association rules,
Research Report RJ 9567, IBM Almaden Research Center, San Jose,
California, October 1993
Reference (2/4)
broadened by Agrawal
[2] "Fast algorithms for mining association rules in large databases"
- 기본적이며 이후연구에서도 쓰이는 Apriori Algorithm과 개선 및
변형으로 AprioriTid, AprioriHybrid를 제안 구현.
R. Agrawal and S Srikant. Fast Algorithms for Mining Association Rules on
Large Databases. Proceedings of the 20th International Conference on
Very Large Data Bases, September 1994
[3] "An Effective hash-Based Algorithm for Mining Association Rules"
- Apriori를 개선한 algorithm으로 DHP Algorithm을 제안 구현.
Jung Soo Park, Ming-Syan Chen, and Philip S. Yu. An effective hash-based
algorithm for mining association rules. In Proceedings of ACM SIGMOD
Conference on Management of Data (SIGMOD'95), pages 175-186, San
Jose, California, May 1995.
Reference (3/4)
4] "An Efficient Algorithm for Mining Association Rules in Large
Databases"
- Apriori를 개선한 algorithm으로 Partition을 제안 구현
Ashok Savasere, Edward Omiecinski, and Shamkant Navathe. An efficient
algorithm for mining association rules in large databases. In Proceedings of
the 21st International Conference on Vary Large Data Bases(VLDB'95),
pages 432-444, Zurich, Swizerland, 1995.
[5] "Sampling Large Databases for Association Rules"
- The concept of negative border
Hannu Toivonen. Sampling large databases for association rules. In
Proceedings of the 22st International Conference on Vary Large Data
Bases(VLDB'96), Mumbai(Bombay), India, 1996
Reference (4/4)
[6] "Dynamic Itemset Counting and Implication Rules for Market Basket
Data"
- DIC를 제안 구현
Sergey Brin, Rajeev Motwani, Jeffrey D. Ulman, Shalom Tsur. Dymamic itemset
counting and implication rules for market basket data. In Proceedings of
ACM SIGMOD Conference on Management of Data (SIGMOD'97), 1997.
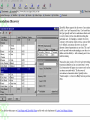
Algorithm Apriori
for Mining Association Rule
Ex : Determining “large itemsets”
minimum support = 2
C1
Database D
TID
100
200
300
400
Items
ACD
BCE
ABCE
BE
Scan
D
C2
Itemset
{A B}
{A C}
{A E}
{B C}
{B E}
{C E}
C3
Itemset
{B C E}
Itemset
{A}
{B}
{C}
{D}
{E}
L1
Sup.
2
3
3
1
3
C2
Scan
D
Scan
D
Itemset
{A B}
{A C}
{A E}
{B C}
{B E}
{C E}
Sup.
2
3
3
3
L2
Sup.
1
2
1
2
3
2
C3
Itemset
{B C E}
Itemset
{A}
{B}
{C}
{E}
Itemset
{A C}
{B C}
{B E}
{C E}
Sup.
2
2
3
2
L3
Sup.
2
Itemset
{B C E}
Sup.
2
Algorithm DHP
for Mining Association Rule
Hash Table H 2 와 후보 2-항목집합 C 2 를 생성하는 예 (DHP)
Variations on Association Rules
Lots of variations exist
- Generalized Association Rules
- Numerical Association Rules
- Constraint Based Association Rules
- Negative Association Rules
- Extra Long Association Rules
- Cyclic Association Rules
Mining Generalized Association
Rules
Taxonomy, New interesting measure
Rules
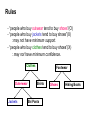
- “people who buy outwear tend to buy shoes”(O)
- “people who buy jackets tend to buy shoes”(X)
: may not have minimum support.
- “people who buy clothes tend to buy shoes”(X)
: may not have minimum confidence.
Clothes
Outerwear
Jackets
Footwear
Shirts
Ski Pants
Shoes
Hiking Boots
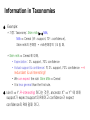
Information in Taxonomies
Example:
* 가정: Taxonomy: Skim milk is-a Milk,
Milk Cereal ( 8% support, 70% confidence),
Skim milk의 판매량 = milk판매량의 1/4 일 때,
* Skim milk Cereal 에 대해,
• Expectation: 2% support, 70% confidence
• Actual support & confidence: 약 2% support, 70% confidence ==>
redundant & uninteresting!!
• We can expect the rule: Skim Milk Cereal
• It is less general than the first rule.
rule X Y R-interesting 하다는 것은, ancestor X^ Y^ 에 비해
support가 expect support의 R배이고 confidence가 expect
confidence의 R배 일때 이다.
Algorithms
Three Parts:
1. minimum support를 가지는 :빈발항목집합 찾기
(taxonomy의 어떤 수준에서 빈발항목집합을 찾는 algo.)
2. minimum confidence.를 가지는 rule 찾기
(이전의 algo사용)
3. R-interesting 하지 못한 규칙들 잘라내기
Algorithms
Basic, Cumulate, Stratification
결론
이전의 연구들 - 결과부나 조건부의 support가 기대하던
support보다 얼마나 많은가에 초점.
– 많은 중복 규칙을 prun할 수 없음.
Information in taxonomies to derive a new interest measure:
– prunes out 40% to 60% of the rules as “redundant” rules.
Mining Association Rules
with Item Constraints
specific item(constraint)을 boolean expression을 사용하여 표현하
고 이것을 포함하는 규칙을 찾는 것으로 execution time를 줄이자.
Problem Statement
Let B be a boolean expression over L
in disjunctive normal form(DNF), D1 ∨ D2 ∨ … ∨ Dm
Di is of the form αi1 ∧αi2 ∧ … ∧ αini
For example, let the set of items L = {1, 2, 3, 4, 5}
consider B = (1 ∧ 2) ∨ ¬ 3
: S = {1, 3} or {2, 3} or {1, 2, 3, 4, 5}
Candidate Generation
-기존의 Gen은 constraints가 존재하는 빈발항목집합을
generate하지 못한다.
Ex : (constraint - item2를 포함하는 것을 찾고 싶을 때 )
L2 ={ {12},{23} }
after the join step, C3 = {123}
(subset {13} does not contain 2)
Algorithms
Taxonomy 를 고려하지 않은 algo.
Phase1 를 만족하는 모든 빈발항목 집합들 찾기.
– First approaches: 선택된 items에 사용
• 1. Selected item을 적어도 하나 포함하고 를 만족하는
itemset을 generate한다.
• 2. 선택된 items을 포함하는 후보집합에 한하여 계산하도록
candidate generation procedure를 수정한다.
: MultipleJoin” and “Reorder”
• 3. 를 만족하지 않는 빈발항목집합을 Discard.
– Second approaches: “Direct”
• 직접 를 사용하기 위해 candidate generation procedure를
수정해서, 를 만족하는 후보항목집합에 한하여 계산한다.
Phase 2 빈발항목 집합에서 rule을 generate
Phase 3 Apriori algorithm 을 이용하여 confidences계산
Cyclic Association Rules
specific periodic time interval, cycles
Cyclic Association Rule
Example
– coffee and doughnut의 경우 최소지지도를 가지지 못한다.
However, hourly and weekly sales figures
• “coffee doughnuts” during the time interval 7AM-9AM every day.
• “coffee doughnuts” during weekends.
Cycle c is a tuple (l, o), 0 ≤ o < l
– length l (in multiples of the time unit)
– offset o (the first time unit in which the cycle occurs)
ex] “coffee doughnuts” has a cycle (24, 7),
• if the unit of time is an hour and “coffee doughnuts” holds during
the interval 7AM-8AM everyday (i.e., every 24 hours).
• Multiple time unit 7AM-8AM, 4PM-5PM every day.
C1=(24, 7), C2=(24, 16)
Cycle-Pruning, Cycle-Skipping and
Cycle-Elimination
sequential algo의 경우 running time의 많은 부분을 items의 support를
계산하는데 사용한다. Cycle-pruning, cycle-skipping, cycleelimination을 사용하여 support를 계산해야 하는 itemsets의 수를
줄여보자.
Cycle-skipping
– time unit ti 에서 cycle이 아닌 부분은 support를 계산하지 말자.
– 그러나, itemset X의 cycle에 관한 정보를 알고 있을 때만 유용하다.
Cycle-pruning
– “If an itemset X has a cycle (l, o), then any of the subsets of X has
the cycle (l, o).”
Cycle-elimination
– “If the support for an itemset X is below supmin in time segment D[I],
then X cannot have any of the cycles (j, I mod j), lmin ≤ j ≤ lmax .”
Data-mining product
Link Analysis (Association)
1. Bayesian Knowl. Disc. (Open U.)
2. Brute (Univ. Of Washington)
3. BusinessMiner (Business Objects)
4. Claudien (K. U. Leuven)
5. Clementine (Integral Solutions Ltd.)
6. CN2 (Univ. Of Texas)
7. Darwin (Thinking Machines)
8. Data Surveyor (Data Destilleries)
9. DBMiner (SFU)
10. Delta Miner (Bissantz)
11. DI Diver (Dimensional Insight)
12. IDIS (Information Discovery)
13. Kepler (GMD)
14. MineSet (Silicon Graphics)
15. MLC++ (Silicon Graphics)
16. Mobal (GMD)
17. MSBN (Microsoft)
18. PolyAnalyst (Megaputer)
19. Q-Yield (Quadrillion)
20. Ripper (AT&T)
21. Rosetta (NTNU)
22. Rough Enough (Troll Data)
23. Scenario (Cognos)
24. Sipina-W (Univ. Of Lyon)
25. SuperQuery (AZMY)
26. Weka (Univ. of Waikato)
27. WizRule (WizSoft)
연구 방향
• 연관 규칙 탐사
– Sampling approach, parallel method, distributed algorithm등의
연구
– Candidate itemsets을 효율적으로 관리하고 scanning에 효과적인
자료구조 연구
– 규칙의 흥미도 또는 중요도 측정
– 연관 규칙의 응용으로 구체적인 적용 방법.
• Other patterns
– pattern의 정의와 적용에 관한 문제 연구
– Similarity search
– WWW에서 path traversal patterns등의 연구