Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
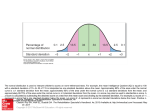
MTTC Professional Readiness Examination Statistics and Probability Review Populations versus samples: A population is all members of a group or set. A sample is a subset or portion of the population. o Population parameters are measures of the entire population. Every member of the population must be measured for the value to be considered a population parameter. Examples of population parameters are the population mean (𝜇) and population standard deviation (𝜎). o Sample statistics are measures from a sample of the population. In others words not all members of the population are included in the sample. The sample mean (𝑥̅ ) and sample standard deviation (𝑠) are two such statistics. o Why use samples? We are always interested in population parameters; however, typically every member of a population cannot be measured or is impractical to measure. So, we measure a representative sample of the population and then apply statistical ideas to those measures to make inferences about the population parameters. For example, we measure the sample mean and then use statistical concepts to draw conclusions about the population mean. Examples: Which of the following are samples and which are population measures? a) the average age of all citizens of the United States b) the proportion of voters in a poll who voted for the President in the most recent election c) average GPA in a subset of all math classes at SVSU d) the proportion of SVSU students who average more than seven hours of sleep per night during the fall semester. Answers: a) population, because the group of people is a census of all citizens of the US b) sample, because the voters are from a poll which is sample of all voters c) sample, because a subset of all math classes is a sample d) population, because it is a census of all SVSU students (editorial note, this proportion is probably rather small.) Bias is a difference between the population parameter and sample statistic that is not caused by random error. Sources of bias arise from how the sample is selected and how the data is collected. In others words bias can come from sampling and measurement errors. o Sampling errors produce samples that do not represent the population and thereby produce false measures and conclusions about the population. For this reason, sample selection is critically important to collecting useful data. For example, sample selection is often responsible for discrepancies between different political polls. o Data collection errors produce nonrandom, inaccurate measurements of individuals in the sample. Calibration errors of physical measurement tools are one source of such errors. Another source of such errors is biased or leading questions in surveys. Examples: Determine the type of error and explain how the error could be prevented: Math & Physics Tutoring Center – Saginaw Valley State University MTTC Professional Readiness Review Statistics and Probability p. 2 a) A voluntary survey of local news viewers found that the majority saw that station as having the best local news. b) The blood cholesterol levels of a random sample of people from a city were measured using an improperly calibrated instrument. c) A random sample of the US population was asked the following question: do you think road funding should be increased given the horrible state of our roads? Answers: a) The survey is self-selected and not random, so it does not represent the views of the population. The bias could be eliminated with a well-constructed sample of randomly selected viewers of all local news from the entire local population. Voluntary and convenience sampling is easily conducted, but is dangerous because it can easily lead to false inferences. b) An inaccurate calibration produces a non-random, systematic error. As a result the mean value will be lower or greater than the actual value. This problem can be corrected by properly calibrating the instrument and verifying the calibration. c) The emotionally charged phrase “given the horrible state of our roads” will likely influence some respondent’s answers. Questions need to be written in as neutral a manner as possible. For example the question, “Should road funding be decreased, unchanged or increased?” would be less biased. Observational and experimental studies are two broad types of statistical studies o Observational studies simply obtain data without manipulating or controlling the situation being studied. An example of an observational study is recording the number of drivers who come to a complete stop at a stop sign from a concealed location. Another example is a survey of a group, such as likely voters. Observational studies cannot establish or reject cause-and-effect relationships. They are used instead to understand the state of a population, like the driving habits at a specific stop sign o Experimental studies manipulate the independent variables. Such studies are used to establish or reject cause-and-effect relationships. For instance a double blind study to test the effectiveness of a pharmaceutical drug would be an example of an experimental study. Examples: Identify the study type and conclusion that can be drawn from the study. a) From a survey of college students, the plot of GPA versus hours spent studying per week is made and strong positive linear correlation is shown. b) Students were randomly assigned to sections of a math course. Half the sections included a once a week recitation session and half did not. The mean course percentage was significantly greater for those students in the recitation sections than the other sections. Answers: a) Since the investigation involved a simple survey, the study was observational. The conclusion that can be drawn is that hours spent studying and GPA are correlated. No conclusion about causation can be made, because the study was not an experimental study. b) This is an experimental study, since the independent variable of recitation session was manipulated. It can be concluded that the recitation sessions increased course percentage since that data was obtained from an experimental study and recitation sessions was the manipulated independent variable. Math & Physics Tutoring Center – Saginaw Valley State University MTTC Professional Readiness Review Statistics and Probability p. 3 Measures of center are numerical values that represent the location of the middle portion of the distribution. The common measures of center are… o Mean: Also known as the average. It is calculated by adding all the values and dividing the sum by the number of values. An example of mean is an average exam score. o Median: The middle value. Found by arranging all the values in order from smallest to largest, and then crossing off pairs of values at the extremes until only the one or two middle values remain. If only one value remains, the median is the middle value. If two values remain, the median is the average of these two middle values. A good example is median family income. Fifty percent of values are greater than the median and 50% are less. o Mode: The most frequent value in the distribution or the peak value. A distribution has no mode if no values are repeated. A distribution can have multiple modes if multiple values are repeated the same number of most frequent times. Distributions with multiple modes have multiple peaks. o Weighted Average: An average where some values count more than others. Each value has a weight associated with it. The product of the weights and values are summed and divided by the sum of the weights. A good example of a weighted average is grade point average. The values are the grade points per credit hour. The weights are the credit hours. o Relationship between measures of center: If the distribution is symmetric, the mean, median, and mode will have the same value. If the distribution is skewed the mean will be moved towards the direction of skew, but the median will remain near the peak, since very large or small values affect the mean but have little impact on the median. This is why median income values are reported, so the income of the ultra-rich, like Bill Gates, doesn’t distort the measure of center towards high income. Examples: A) Find the mean, median, and mode of the following set of values: 4, 6, 6, 7, 9, 12. Answer: 4 + 6 + 6 + 7 + 9 + 12 ̅̅̅ Mean = = 7. ̅33 6 Median: 4, 6, 6, 7, 9, 12 medain = 6+7 2 = 6.5 Mode = 6 (Because 6 is the most frequent occurring value) B) For the distribution of household income in the U.S., which is a better measure of center, mean or median? Answer: Median household income is a better measure of the center of the distribution than mean family income. This is because the household income distribution is skewed to the right by the ultra-rich, which will significantly impact the mean, but have little impact on the median. Math & Physics Tutoring Center – Saginaw Valley State University MTTC Professional Readiness Review Statistics and Probability p. 4 C) The weighted average (or GPA) on a four-point scale is computed by: GPA = 𝑐𝑟𝑒𝑑𝑖𝑡𝑠1 ∙𝑔𝑟𝑎𝑑𝑒1 +𝑐𝑟𝑒𝑑𝑖𝑡𝑠2 ∙𝑔𝑟𝑎𝑑𝑒2 +𝑐𝑟𝑒𝑑𝑖𝑡𝑠3 ∙𝑔𝑟𝑎𝑑𝑒3 +... 𝑡𝑜𝑡𝑎𝑙 𝑐𝑟𝑒𝑑𝑖𝑡𝑠 Find the GPA for someone who got an A in a 3 credits class, a B in a 2 credit class, and a C in a 4 credit class. Answer: GPA = 3(4)+2(3)+4(2) 3+2+4 = 26 9 ≈ 2.89 Measures of Variation are numerical values that measure the spread of a distribution. Note that distributions can have identical measures of center and still have radically different measures of variation. A measure of center without a measure of variation gives an inadequate description of the distribution. Common measures of variation are… o Percentiles and Quartiles: A percentile is the value which has that percentage of the distribution less than it. For example the 90th percentile in height for women is the height which 90% of women are shorter than and 10% of woman are taller than. The 1st, 2nd and 3rd quartiles are the 25th, 50th, and 75th percentiles respectively, so quartiles are just special percentiles. The 50th percentile is also the median. o Range: The difference between the maximum and minimum values. o Interquartile Range: The difference between the 75th and 25th percentiles. o Variance: The average square of the distance from the mean. For a population the equation for variance (𝜎 2 ) the sum of the squares of the differences from the mean divided by sample size. For a sample variance (𝑠) the denominator is the one less than the sample size. o Standard deviation is simply the square root of the variance. ∑(𝑥𝑖 −𝜇)2 𝜎=√ 𝑁 , for a population standard deviation. ∑(𝑥𝑖 −𝑥̅ )2 𝑠=√ 𝑛−1 , for a sample standard deviation. where or 𝑥̅ is the mean and N or n is the size of the population or sample. Example: Find the 25th, 50th, and 75th percentiles, range, interquartile range, variance, and standard deviation of the following set of values: 4, 6, 6, 7, 9, 12. Assume the data set is from a sample. Answer: 50th percentile = 6.5 (the median, see previous example) 25th percentile (median of the lower 50%): 4, 6, 6 25th percentile = 6 th 75 percentile (median of upper 50%) : 7, 9, 12 75th percentile = 9 Range: maximum – minimum = 12 – 4 = 8 Interquartile Range = 75th percentile – 25th percentile = 9 - 6 = 3 Sample Variance: Remember from the earlier example 𝑥̅ = 7.33 𝑠2 = ∑(𝑥𝑖 −𝑥̅ )2 𝑛−1 = (4−7.33)2 +(6−7.33)2 +(6−7.33)2 +(7−7.33)2 +(9−7.33)2 +(12−7,.33)2 6−1 Math & Physics Tutoring Center – Saginaw Valley State University = 7.87 MTTC Professional Readiness Review Statistics and Probability p. 5 Sample Standard Deviation: 𝑠 = √7.87 = 2.81 In the graph of a probability distribution, the x-axis of the graph represents the observed or measured value. The height represent the frequency or likelihood of that value occurring o Area between two x values represents the probability of obtaining a result between them. o A Normal Distribution is a symmetrical, bell-shaped probability distribution. Normal distributions with greater means will be centered farther to the right. Distributions with greater standard deviations will be broader and shorter. The probability of being within 1 standard deviation from the mean is approximately 68%. In others words, 68% of the observations would be expected to be within 1 standard deviation. The probability of being within 2 standard deviations from the mean is approximately 95%. In others words, 95% of the observations would be expected to be within 2 standard deviations. The probability of being within 3 standard deviations from the mean is approximately 99.7%. In others words, 99.7% of the observations would be expected to be within 2 standard deviations. Generally observations beyond two standard deviations are considered to be unusual since there is a small probability they occur by just random chance. o The z-score is the number of standard deviations the observation is from the mean. The farther the z-score is from zero the more unlikely the observation occurred by just random chance. The closer the z-score is to zero the more likely the observation can be explained by random chance. The equation for z-score is 𝑧= 𝑥−𝜇 where 𝑥 is the observed or measured value, 𝜇 is the population mean, and is the population standard deviation Examples: A) What is the probability of a measured value being within a z-score of -2 and 2? Answer: Since a z-score of 2 is equivalent to two standard deviations and 95% of the data lies within two standard deviations, the probability of an observation being within a z-score of -2 and 2 is approximately 95%. B) Distribution A has a mean of 20 and standard deviation of 10. Distribution B has a mean of 30 and standard deviation of 5. Which distribution has its center farther to the right? Which is tall and narrower? Which is shorter and wider? Answer: The distribution with the largest mean will have its center located farther to the right. So the center of distribution B is farther to the right, since it has a larger mean. Distributions with smaller standard deviations are narrower and taller. Those with larger standard deviations are wider and shorter. So distribution A, because it has a larger standard deviation is wider and shorter than distribution B, and distribution B is narrower and taller. Math & Physics Tutoring Center – Saginaw Valley State University MTTC Professional Readiness Review Statistics and Probability p. 6 C) For a distribution with a mean of 15 and standard deviation of 5, what is the z-score of an observation with a value of 7? Also would this observation be considered unusual based on random chance? Answer: 𝑧 = 𝑥−𝜇 𝑠 = 7−15 5 = −1.6 This observation would not be considered unusual, because it is within 2 standard deviations of the mean. Graphical representations of data are used to enhance visualization of both correlations in bivariate data and the distribution of uni-variant data. Often the first step in statistical analysis is to tabulate and graph the data to visually look for relationships within the data. Much can be initially gleaned by examining the data visually in tabular or graphical form. o Bar charts are used when one variable is categorical. o Scatterplots are more useful when both variables are quantitative. o Histograms are often used to examine the distribution of data. o Pie charts are helpful to examine the distribution of categorical data. Examples: What type of graph would be most useful for each data set? a) The relationship between gas mileage and car weight b) temperature trends during the year c) distribution of eye color in the US population d) hours spent studying as a function of day of the week e) family income distribution in the US. Answers: a) Since both gas mileage and car weight are quantitative a scatterplot would be a good choice. Any correlation between mpg and weight would likely be visible in the scatterplot. b) A line graph or time chart would be a good representation of temperature versus time data and help identify yearly trends. c) Since eye color is categorical data, a pie chart would show the distribution of the population. A bar chart would also be suitable. d) Likewise since days of the week are categorical, either a bar chart or pie chart would work well. e) Since income is quantitative, a histogram with a suitable class width to create about 10-20 bars would be a good choice to represent the distribution of family income in the US. Bivariate Data is data that involves two variables. Examples of such data are height versus age, income versus education level, life expectancy versus income, GPA versus hours spend studying per week. o Scatter Plots on an x-y coordinate system are often used to represent and help analyze bivariate data. Such plots help visually observe the presence or absence correlation between the two variables plotted on the x- and y-axes. If the trend rises moving left to right, the slope is positive. If it declines moving from left to right, the slope is negative. o Pearson’s Correlation Coefficient tells how strongly two variables are associated. Bivariate data with a correlation coefficient of 1 is perfectly correlated in an upward trend, meaning all points lie on the same line with a positive slope. Likewise a correlation coefficient of -1 is a perfectly correlated downward trend. A correlation Math & Physics Tutoring Center – Saginaw Valley State University MTTC Professional Readiness Review Statistics and Probability p. 7 coefficient of 0 has no association between the variables. When the correlation coefficient is 0 the points on the x-y plot are typically scattered, although they could all lie on a horizontal straight line. Data with correlations coefficients between -1 and 1 have points scattered around a trend line. The the larger the correlational coefficient (in absolute value) the more tightly the points are grouped around the trend line. Examples are shown below (source: http://ordination.okstate.edu/STAT o o Correlation is not the same as causation! Correlation only means there is a mathematical trend between the two variables. Correlation does not mean a change in one variable causes a response in the other variable. For example, a correlation between ice cream sales at a beach and the number of lifeguard rescues does not mean that ice cream causes people to swim more dangerously. It just means the two variables follow the same trend. A more likely explanation is that the two variables are correlated because on days that there are more sales of ice cream more people are at the beach and the number of rescues tends to increase because there are more people at the beach. So ice cream sales and rescues are correlated simply because both are related to the number of people at the beach. The important point is that correlation does not imply causation! Observational studies do not establish causation. Experimental studies where the independent variables are manipulated in a controlled matter are necessary to make inferences about causation. Linear regression mathematically finds the best fit line for data that has a statistically significant correlation. Such lines can be used to predict the expected value of the second variable from the value of the first variable given the trend exists. Remember that such predictions do not imply causation, for the two variables may be linked to another variable. Example: Pizza prices and the Consumer Price Index have a correlation coefficient of 0.85. Describe the meaning of the correlation, appearance of the plot of the two variables on an x-y graph, and the causation between the variables. Math & Physics Tutoring Center – Saginaw Valley State University MTTC Professional Readiness Review Statistics and Probability p. 8 Answer: A correlation coefficient of 0.85 is considered a strong correlation. Remember the strength of the correlation increases as the correlation coefficient approaches 1 or -1. The data on the x-y graph would be expected to be fairly tightly scattered around an upward trend line. The strong correlation does not imply causation. Correlations never establish causation. In this case the Consumer Price Index obviously doesn’t cause pizza prices to increase, since the CPI is only a mathematic index used to measure the economy, not a driving force and causation of change in the prices. Probability is the likelihood of an event occurring. It is simply the number of ways the desired event can occur divided by the number of all possible events. For example, the likelihood of obtaining a five on a single roll of a six-sided dice is 1/6. There is only one way for the dice to show a five. There are six possible events. So the probability is 1 divided by 6 or 1/6. o Without replacement are situations where items from the population are selected only once. Dealing cards from a deck are one example. Once a card is dealt to a person, the same card cannot be dealt to another person during the same round. In others words the cards are not replaced into the deck immediately after each one is dealt. In situations without replacements, the number of items available to choose from declines by one after each selection since one fewer of the items remain, and therefore the probability of selection of that item changes with each selection. o With replacement are situations where the probability of selecting any item remains the same, because after each selection all items are returned to the population prior to the next selection. An example of with replacement is sequential throwing a dice. On each throw all six possible outcome exist and have the same probability. o Sample space is a listing of all possible outcomes. For example if you flip two different coins simultaneously the sample spaces is simply the possible outcomes, which are heads-heads, heads-tail, and tails-tails. o Fundamental counting rule is used to calculate the number of possible outcomes. If the first event can occur m ways and the second can occur n ways, the two events together can occur 𝑚 ∙ 𝑛 ways Example: How many possible can a six character passwords are possible if characters can be repeated? Answer: There are 26 letters and ten digits (0 through 9) available for each of the six characters. So, there are 36 possibilities for each character. So there are 36 ∙ 36 ∙ 36 ∙ 36 ∙ 36 ∙ 36 = 366 = 2,176,782,336 possible passwords. Practice Problems: 1. What is the mean, median, and mode and standard deviation of a sample with values of 10, 11, 17, 13, 29, 10? Math & Physics Tutoring Center – Saginaw Valley State University MTTC Professional Readiness Review Statistics and Probability p. 9 2. Is 53 an usual or unusual value for a normal distribution with an mean of 60 and standard deviation of 4? a. Not unusual, because the z-score is less than -2. b. Not unusual, because the z-score is not less than -2. c. Unusual, because the z-score is less than -2. d. Unusual, because the z-score is not less than -2. 3. Is 31 an unusual or usual age for a normal distribution with and average population age of 21 and a standard deviation of 4.2? a. Not unusual, because the z-score is greater than 2. b. Not unusual, because the z-score is less than or equal to 2. c. Unusual, because the z-score is greater than 2. d. Unusual, because the z-score is less than or equal to 2. 4. If an observational study found that weight correlates with age with a correlation coefficient of 0.85 what can be conclude? a. Weight increases with age, and age causes weight gain. b. Weight decreases with age, and age cause weight loss. c. Weight and age are related, and weight tends to increase with age. d. Weight and age are related, and weight tends to decrease with age. e. There is no relationship between age and weight. 5. Which kind of graph could best be used to represent the distribution of ages of citizens of the United States? a. A x-y scatterplot b. A histogram c. Pie chart d. Bar chart 6. a. b. c. d. Which kind of graph could not be used to represent the trend in daily high temperature over time? A x-y scatterplot A histogram Pie chart A run chart 7. a. b. c. d. Which would be a parameter of a population? The mean score of a sample five students from all of those passing MATH 110. The mean of a poll for a presidential election. The standard deviation of the age of fifty SVSU students who are non-traditional. The standard deviation of the age of all current SVSU students. 8. Which is non-biased? Math & Physics Tutoring Center – Saginaw Valley State University MTTC Professional Readiness Review Statistics and Probability p. 10 a. b. c. d. e. A poll of your friend’s opinions on their favorite candy bar. A survey of opinions regarding Medicare of visitors to the AARP Internet site A survey that asks: “Should there be term limits to fix the do-nothing Congress?” A Gallop poll sampling voters views on the state of public education. The ratings of SVSU professors on RateMyProfessor.com 9. a. b. c. d. Which is an experimental study? A science project investigating how controlling the level of fertilizer affected plant growth. A comparison of the heights and weights of residents of the United States. An examination of personal income and eye color. The distribution of number of television sets per household in the United States. 10. How many possible license plate combinations can be made for plates with six characters (letters and numbers) if the characters cannot be repeated. a. 6! b. 36 ∙ 35 ∙ 34 ∙ 33 ∙ 32 ∙ 31 c. 66 d. 366 11. How many possible license plate combinations can be made for plates with six characters (letters and numbers) if the characters can be repeated. a. 6! b. 36 ∙ 35 ∙ 34 ∙ 33 ∙ 32 ∙ 31 c. 66 d. 366 Answers: See the solutions document for detailed calculations and explanations 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. Mean =15; median = 12; mode = 10; standard deviation = 7.35 B C C B C D D A B D Math & Physics Tutoring Center – Saginaw Valley State University