Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
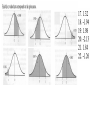
STT 5600 6.2 Normal Distribution (Background) 6.3 Areas Under the Normal Curve 6.4 Application of the Normal Distribution The normal distribution is the most commonly used distribution and is commonly known by the bell-shaped curve it generates. Many things closely follow a Normal Distribution: • heights of people • size of things produced by machines • errors in measurements • blood pressure • marks on a test According to the book: p.172 Before we even talk about integrating that hot mess let’s look at some more curves. Unlike Dr. King – I am not even going to offer to derive these – but you can look at p. 175 if you want to see it! But – clearly the area under the two curves between x1 and x2 is different. Why? Because the mean and standard deviation are different. What could we do to data to make the areas the same (consistent) for all sets of data? Hint: We can normalize data by taking every data point and subtracting the mean and dividing by the standard deviation. We call this now data point a z-score. Once data is converted to a z-value, we can use the table which lists the area under the curve with a mean of 0 and standard deviation of 1. TRANSLATION: no integration necessary! There are basically two different types of problems: 1. The problem asks for the probability or proportion of a distribution between two points or values. This is asking for the area under the curve. You will normalize the values by finding the respective zvalues and use the table to find the area under the curve. The following slides show the specifics of this process. 2. The other type gives you the probability or proportion (the area under the curve) and you will need to find the corresponding z-values. You may need to convert the z-values back to the data values by using the z-value formula and the population mean and standard deviation. There will be examples of this process as well. For these problems, assume a standard normal distribution: Find P(z<1.42) The "area under the curve" represents the shaded portion and it tells you to the "left" of 1.42, so everything to the left of 1.42 should be shaded. Given points – Find area Find P(z>-0.42) The -0.42 is a single value, therefore it is the z-score looked up in the table and represented by the vertical line. 1 - .3372 = .6628 Find the P(-1.75<x<2.05) Here there are two z-values, but each of those is a singular number and so they are represented by vertical lines on the graph. The "data" is the shaded portion of the graph and so the shaded portion is between z = -1.75 and z = 2.05 .9798 - .0401 = .9397 Given area – find values What z-score has 40% of the data greater than it. The key here is to figure out what the antecedent of "it" is. That is, what does "it" refer to? The zscore or the data? Try rewording the sentence and see which makes sense. - 40% of the data is greater than the z-score - 40% of the data is greater than the data However, you can't look the area to the right in the table, you have to look up the area to the left. The area to the left is found by subtracting the area to the right from 1. So 1 - 0.4000 = 0.6000 and that's what you should look up in the table. So, the z-score that has 40% of the data greater than it is z = 0.25. When you do that, the closest value to 0.6000 is 0.5987 and that occurs when z = 0.25. The next closest value is 0.6026, when z = 0.26, but you go with the closest value unless it is exactly half-way between the two values and then you go with the midpoint between the two z-scores. What z-score is higher than 75% of the data? Since 75% is more than 50%, I will shade all of the left side and 25% of the right side. Since the 75% = 0.7500 is the area to the left, you don't need to adjust it. When you look up 0.7500 in the table, the closest value to it is 0.7486 when z = 0.67. The next closest was 0.7517 when z = 0.68, but it was 0.0017 off and the 0.7486 is only 0.0014 off. So, the z-score higher than 75% of the data is z = 0.67. x = (6)(−0.13) + 40 = 39.22 , x = (7)(1.18) + 74 = 82.26. 1. Between z = 0 and z = -2.07 2. To the right of z = 0.23 3. To the left of z = -1.43 4. Between z = 0.79 and z = 1.28 5. Between z = -1.56 and z = -1.83 6. Between z = 2.47 and z = -1.03 7. To the left of z = 2.11 8. To the right of z = -0.18 9. To the right of z = 1.92 and to the left of z = -0.44