Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
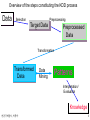
연관 규칙 탐사와 그 응용 성신여자대학교 전산학과 박 종수 [email protected] 연관규칙탐사, 박종수 1 차례 Data Mining in the KDD Process Association Rule의 정의 Mining Association Rules in Transaction Databases Algorithm Apriori & DHP Generalized Association Rules Cyclic Association Rules and Negative Associations. Interestingness Measurement Sequential Patterns and Path Traversal Patterns 연구 방향 및 참고 Homepages 연관규칙탐사, 박종수 2 Overview of the steps constituting the KDD process Data Selection Preprocessing Target Data Preprocessed Data Transformation Transformed Data Data Mining Patterns Interpretation/ Evaluation Knowledge 연관규칙탐사, 박종수 3 Types of Data-Mining Problems Prediction – – – Classification Regression Time Series Knowledge Discovery – – – – – – – 연관규칙탐사, 박종수 Deviation Detection Database Segmentation Clustering Association Rules Summarization Visualization Text mining 4 Association Rule Ex: the statement that 90% of transactions that purchase bread and butter also purchase milk. [Bread], [Butter] [Milk] (12.5%, 90%) antecedent consequent 90% : confidence factor of the rule (not 100%) 12.5%: support for the rule, the fraction of transactions in database Find all rules that have “Diet Coke” as consequent. Find all rules that have “bagels” in the antecedent. Find the “best” k rules that have “bagels” in the consequent. 연관규칙탐사, 박종수 5 연관규칙의 정의 I : a set of literals called items. T: a set of items such that T I, transaction. An association rule is an implication of the form X Y, where X I, Y I and X Y = ø. X Y [support, confidence] # of transacti ons containing all the items in X Y support total # of transacti ons in the database # of transacti ons that contain both X and Y confidence # of transacti ons contaning X 연관규칙탐사, 박종수 6 Transaction Databases에서 연관 규칙 탐사 Applications: pattern association, market analysis, etc Given data of transactions each transaction has a list of items purchased Find all association rules: the presence of one set of items implies the presence of another set of items. - e.g., people who purchased hammers also purchased nails. Measurement of rule strength Confidence: X & Y Z has 90% confidence if 90% of customers who bought X and Y also bought Z. Support: useful rules(for business decision) should have some minimum transaction support. 연관규칙탐사, 박종수 7 Two Steps for Association Rules Determining “large itemsets” Find all combinations of items that have transaction support above minimum support Researches have been focussed on this phase. Generating rules for each large itemset L do for each subset c of L do if (support(L) / support(L - c) minimum confidence) then output the rule (L - c) c, with confidence = support(L)/support(L - c) and support = support(L); 연관규칙탐사, 박종수 8 Focus on data structures to speed up scanning the database Hash tree, Trie, Hash table, etc. minimum support Candidate Itemsets Large Itemsets Scan Database How to generate candidate itemsets Apriori method: join step + prune step minimum confidence Association Rules 연관규칙탐사, 박종수 9 C1 Database D TID 100 200 300 400 Items ACD BCE ABCE BE Itemset {A} {B} {C} {D} {E} Scan D L1 Sup. 2 3 3 1 3 Itemset {A} {B} {C} {E} Sup. 2 3 3 3 minimum support = 2 C2 Itemset {A B} {A C} {A E} {B C} {B E} {C E} C3 Itemset {B C E} 연관규칙탐사, 박종수 C2 Scan D Scan D Itemset {A B} {A C} {A E} {B C} {B E} {C E} L2 Sup. 1 2 1 2 3 2 C3 Itemset {B C E} Itemset {A C} {B C} {B E} {C E} Sup. 2 2 3 2 L3 Sup. 2 Itemset {B C E} Sup. 2 10 Algorithms for Mining Association Rules AIS(Agrawal et al., ACM SIGMOD, May ‘93) SETM(Swami et al., IBM Tech. Rep., Oct ‘93) Apriori(Agrawal et al., VLDB, Sept ‘94) OCD(Mannila et al., AAAI workshop on KDD, July, ‘94) DHP(Park et al., ACM SIGMOD, May ‘95) PARTITION(Savasere et al., VLDB, Sept ‘95) Mining Generalized Association Rules(Srikant et al., VLDB, Sept ‘95) Sampling Approach(Toivonen, VLDB, Sept ‘96) DIC(dynamic itemset counting, Brin et al., ACM SIGMOD, May ‘97) Cyclic Association Rules(zden et al., IEEE ICDE, Feb ‘98) Negative Associations(Savasere et al., IEEE ICDE, Feb ‘98) 연관규칙탐사, 박종수 11 Algorithm Apriori Lk: Set of Large k-itemsets Ck:Set of Candidate k-itemsets Step; C1 L1 C2 L2, ..., Ck Lk Input File: Transaction File, Output: Large itemsets L1 = {large 1-itemset} for ( k=2; Lk-1 Ø; k++) do begin Ck= apriori-gen(Lk-1); forall transactions t D do begin Ct = subset(Ck, t); forall candidates c Ct do c.count++; end Lk= {c Ck| c.count minsup} end Answer = Uk Lk; 연관규칙탐사, 박종수 12 Apriori-gen(Lk-1) Join step insert into Ck select p.item1, p.item2, ..., p.itemk-1, q.itemk-1 from Lk-1 p, Lk-1 q where p.item1= q.item1, ..., p.itemk-2= q.itemk-2, p.itemk-1< q.itemk-1 Prune step forall itemsets c Ck do forall (k-1)-subsets s of c do if ( s Lk-1 ) then delete c from Ck; 연관규칙탐사, 박종수 13 Ex: Generation of Candidate Itemsets 예: L3로부터 C4 를 생성하는 과정. Join step L3 = {{1, 2 ,3}, {1, 2, 4}, {1, 3, 4}, {1, 3, 5}, {2, 3, 4}}일때, 후보 4-항목집합 = { {1 2 3 4}, {1 3 4 5}} Prune step: - {1, 2, 3, 4} 의 3-subset = {{1,2,3}, {1,2,4}, {1,3,4}, {2,3,4}} - {1, 3, 4, 5} 의 3-subset = {{1,3,4}, {1,3,5}, {1,4,5}, {3,4,5}} 각 {1,4,5},{3,4,5} L3이므로 {1, 3, 4, 5} 는 pruning!! C4 = {{1, 2, 3, 4}} 연관규칙탐사, 박종수 14 Data Structure for Ck 각 레벨의 후보집합에 대해 Hash Tree 형성. 예: C2 = {{A,B},{A,C},{A,T} {B,C}, {B,D},{C,D}}의 Hash Tree C2 Level 1 Level 2 A B B C C C D C,D 중간노드 A,B 연관규칙탐사, 박종수 A,T A,C B,C B,D 잎노드 15 Hash Table H 2 와 후보 2-항목집합 C 2 를 생성하는 예 (DHP) 연관규칙탐사, 박종수 16 Counting support in a hash tree TID Items 100 200 300 400 ACD BCE AB CE BE {A C} {B C} {B E} {C E} {A C} {B C} {B E} {C E} {B E} Discard Keep {B C E} Keep {B C E} Discard D3 = { <200, B C E>, <300, B C E> } C2 count {A C} 2 {B C} 2 {B E} 3 {C E} 2 s=2 L2 {A C} {B C} {B E} {C E} L2와 D3의 예 (DHP) 연관규칙탐사, 박종수 17 Generalized Association Rules Finding associations between items at any level of the taxonomy. Rules: People who buy clothes tend to buy shoes. ( ) People who buy outerwear tend to buy shoes. ( o ) People who buy jacket tend to buy shoes. ( ) Clothes Outerwear Jackets 연관규칙탐사, 박종수 Footwear Shirts Shoes Hiking Boots Ski Pants 18 Problem Statement I = { i1, i2, …, im}: set of literals, D: set of transactions, T: a set of taxonomy, DAG(Directed Acyclic Graph) 일때, X Y [confidence, support], where X I, Y I, XY = , and no item in Y is an ancestor of any item in X. (X, Y: any level of taxonomy T ) Step 1. Find all sets of items whose support is greater than minimum support. 2. Generate association rules, whose confidence is greater than minimum confidence. 3. Prune all uninteresting rules from this set with respect to the Rinteresting. 연관규칙탐사, 박종수 19 Interestingness of Generalized Rules Using new interest measure, R-interesting: Prune out 40% to 60% of the rules as “redundant “ rules. Example: * 가정: Taxonomy: Skim milk is-a Milk, Milk Cereal ( 8% support, 70% confidence), Skim milk의 판매량 = milk판매량의 1/4 일 때, * Skim milk Cereal 에 대해, Expectation: 2% support, 70% confidence Actual support & confidence: 약 2% support, 70% confidence ==> redundant & uninteresting!! 연관규칙탐사, 박종수 20 Cyclic Association Rules Beer and chips are sold together primarily between 6PM and 9PM. Association rules could also display regular hourly, daily, weekly, etc., variation that has the appearance of cycles. An association rule X Y holds in time unit ti, – – – if the support of X Y in D[i] exceeds MinSup and the confidence of X Y in D[i] exceeds MinConf. It has a cycle c = (l, o), a length l and an offset o. “coffee doughnuts” has a cycle (24, 7), – if the unit of time is an hour and “coffee doughnuts” holds during the interval 7AM-8AM everyday (I.e., every 24 hours). 연관규칙탐사, 박종수 21 Negative Association Rules A rule : “60% of the customers who buy potato chips do not buy bottled water.” Negative rule: X Y such that – – (a) support(X) and support(Y) are greater than minimum support MinSup; and (b) the rule interest measure is greater than MinRI. The interest measure RI of a negative association rule, X Y, RI – E[support ( X Y )] support ( X Y ) support ( X ) E[support(X)] is the expected support of an itemset X. 연관규칙탐사, 박종수 22 Incremental Updating, Parallel and Distributed Algorithms 데이타베이스 연관규칙 탐사를 위한 점진적 평가기법. (김의경등, 한국정보과학회 ‘95 가을 학술 발표 논문지) Fast updating algorithms, FUP (Cheung et al., IEEE ICDE, ‘96). PDM (Park et al., ACM CIKM, ‘95): Partitioned derivation and incremental updating. Use a hashing technique(DHP-like) to identify candidate k-itemsets from the local databases. Count Distribution (Agrawal & Shafer, IEEE TKDE, Vol 8, No 6, ‘96): An extension of the Apriori algorithm. May require a lot of messages in count exchange. FDM(Cheung et al., IEEE TKDE, Vol 8, No 6, ‘96). Observation:If an itemset X is globally large, there exists a partition Di such that X and all its subsets are locally large at Di. Candidate set are those which are also local candidates in some component database, plus some message passing optimizations. 연관규칙탐사, 박종수 23 When is Market Basket Analysis useful? The following three rules are examples of real rules generated from real data: – On Thursdays, grocery store consumers often purchase diapers and beer together. Useful – Customers who purchases maintenance agreements are very likely to purchase large appliances. Trivial – rule: high quality, actionable information. rule When a new hardware store opens, one of the most commonly sold items is toilet rings. Inexplicable 연관규칙탐사, 박종수 rule 24 Interestingness Measurement for Association Rules (I) Two popular measurements: support and confidence Use taxonomy information for pruning redundant rules The longer (itemset), the fewer (support). A rule is “redundant” if its support and confidence are close to their expected values based on an ancestor of the rule. Example: ”milk cereal” vs. “skim milk cereal”. More effective than that based on statistical significance. Interestingness of Patterns If a pattern contradicts the set of hard beliefs of the user, then this pattern is always interesting to the user. The more a pattern “affects” the belief system, the more interesting it is. 연관규칙탐사, 박종수 25 Interestingness Measurement (II) Improvement (Interest ) P(conditio n and result) P(conditio n) P(result) – How much better a rule is at predicting the result than just assuming the result in the first place. – Co-occurrence than implication. Symmetric. – Conviction P(conditio n) P(result) P(conditio n and result) – How far ”condition and result” deviates from independence 연관규칙탐사, 박종수 26 Range of measurement Improvement – – Improvement = 1: condition과 result의 item이 completely independent! Improvement < 1: worse rule! Improvement > 1: better rule! Conviction – – – Conviction = 1: condition과 result의 item이 completely unrelated. Conviction > 1: better rule!! Conviction = : completely related rule 연관규칙탐사, 박종수 27 Sequential Patterns Examples of such a pattern: – Customers typically rent “Star Wars”, then “Empire Strikes Back”, and then “Return of the jedi”. – Note that these rentals need not to be consecutive. – 수강신청: 관광과 여가(1학기) 수도권과 주택문제(2학기) 증권시장(3학기) – 주가 변동 패턴: 삼성전자 주가 상승 LG전자 주가 상승 보해양조 주가 상승 – 구매패턴: 양복 와이셔츠 검정색 구두 ? – 의료진단에서 질병 발생 순서 패턴 – 환자 치료에서 진료 및 투약 패턴 연관규칙탐사, 박종수 28 Mining Sequential Patterns An itemset is a non-empty set of items. A sequence is an ordered list of itemsets. Customer Id 1 2 3 4 5 Customer Sequence <(30) (90)> <(10 20) (30) (40 60 70)> <(30 50 70)> <(30) (40 70) (90)> <(90)> Sequential Patterns with support > 25% <(30) (90)> <(30) (40 70)> 연관규칙탐사, 박종수 29 The Algorithm for Sequential Patterns by Agrawal and Srikant, 1995 ICDE Sort Phase – Litemset Phase – A customer sequence is represented by a list of sets of litemsets Sequence Phase ( Apriori 알고리즘의 응용) – litemset = an itemset with minimum support Transformation Phase – major key: customer-id, minor key: transaction-time Candidate sequences ==> Large sequences Maximal Phase – 연관규칙탐사, 박종수 a sequence s is maximal if s is not contained in any other sequence 30 Mining Path Traversal Patterns Understanding user access patterns in a distributed information providing environment such as WWW, Hitel, etc. – help improving the system design – lead to better marketing decisions Capturing user access patterns – mining path traversal patterns – capturing user traveling behavior – improving the quality of such services 연관규칙탐사, 박종수 31 Traversal patterns 1 2 A 12 B 13 6 3 C O 15 14 5 E 11 7 U V 4 D 8 G 10 9 H Maximal forward references {ABCD, ABEGH, ABEGW, AOU, AOV} W 1. Find large reference sequences. 2. Find maximal reference sequences. 연관규칙탐사, 박종수 32 연구 방향 연관 규칙 탐사 – Sampling approach, parallel method, distributed algorithm등의 연구 – Candidate itemsets을 효율적으로 관리하고 scanning에 효과적인 자료구조 연구 – 규칙의 흥미도 또는 중요도 측정 – 연관 규칙의 응용으로 구체적인 적용 방법. Other patterns – pattern의 정의와 적용에 관한 문제 연구 – Similarity search – WWW에서 path traversal patterns등의 연구 연관규칙탐사, 박종수 33 Some Data Mining Systems and Homepages • Quest (IBM Almaden: Agrawal, et al.): – large DB-oriented association, classification, sequential patterns, similar sequences, etc. – “http://www.almaden.ibm.com/cs/quest/” • DBMiner: (SFC: Han, et al.): – Interactive, multi-level characterization, classification, association & prediction. – “http://db.cs.sfu.ca/DBMiner/” • KDD (GTE: Piatetsky-Shapiro, et al.): – multi-strategy, strong rules, statistical approaches, etc. – KD Mine: “http://info.gte.com/~kdd/index.html” • Other Homepages for Data Mining – – – – – Rakesh Agrawal: “http://www.almaden.ibm.com/cs/people/ragrawal/” Usama Fayyad: “http://www.research.microsoft.com/~fayyad/” Heikki Mannila: “http://www.cs.Helsinki.Fl/~mannila/” Jiawei Han: “http://fas.sfu.ca/cs/people/Faculty/Han/” Data Mining and Knowledge Discovery Journal: “http://www.research.microsoft.com/research/datamine/”의 Editorial Board 연관규칙탐사, 박종수 34