Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
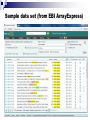
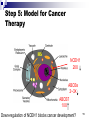
BioQUEST / SCALE-IT Module From Omics Data to Knowledge Case 1: Microarrays Namyong Lee Matthew Macauley Sumona Mondal Fusheng Tang Minnesota State University, Mankato Clemson University Clarkson University University of Arkansas, Little Rock Goals Provide a guideline for teachers in different disciplines to explore different -omics data. The instructor will guide the students through a tutorial of the experimental process, including: data retrieval, statistical design and analysis, biological analysis, and model validation. Module Outline 1. 2. 3. 4. 5. 6. Introduce Microarray and RNAseq technology. Locate available public expression data Formulate questions from the dataset. Design computational and statistical experiments. Interpret biological significance of identified genes. (UniProt, IntAct, and Reactome will be used.) Validate the biological model (using ATLAS). Step 1: Introduce gene expression and microarray and RNAseq technology. What is gene expression? How is gene expression measured? Introduce microarrays and RNAseq. Compare and contrast these two. Step 2: Locate available public expression data ArrayExpress is a database of gene expression and other microarray data at the European Bioinformatics Institute (EBI) www.ebi.ac.uk/arrayexpress/ Sample data set (from EBI ArrayExpress) 5 Obtaining data; an example • Go to ArrayExpress and search “colon cancer.” • Select Accession E-GEOD-42368, titled “p53dependent regulation of gene expression following DNA damage” for Homo sapiens. • Download the processed data as a zip file. • Create a spreadsheet (e.g., Excel) and copy over the data into it, one column per sample. • Each column should have an ILMN_ID number, and then for each sample, an expression level and p-value. • Organize the data by increasing p-values. • Use david.abcc.ncifcrf.gov/ to locate gene names from ILMN_IDs. Preprocessing Why Preprocessing?: The data may have nonbiological variation in the standardized data. Thresholding Scaling (log transformation) Standardize Normalization (Quantile Normalization) Reducing the data set (by pairwise t-test) 7 Step 3: Formulate questions about the data Were there genes whose expression profiles were correlated with colon cancer? If so, how can we accurately determine which of the samples are cancerous based entirely on gene expression profiles? Can any subtypes be identified by cluster analysis across samples ? 8 Step 4: Computational and statistical experiments with R & Bioconductor Class Prediction: Develop a multi-gene predictor of class label for a sample using its gene expression profile. (pairwise t-test) Class Discovery: Use a various clustering algorithms to discover clusters among samples and genes. (K-means, hclust, PAM,…) 9 Hierarchical Clustering Results Over expressed in normal tissues Over expressed in cancer tissues 10 Gene 187 (Hsa.9972) Step 5: Model for Cancer Therapy NCEH1 20X ABCBs 2~3X ABCB7 10X Down-regulation of NCEH1 blocks cancer development? 11 Step 6: Validation of Model Search PubMed for NCEH1 and cancer http://www.ncbi.nlm.nih.gov/pubmed/17052608 12 Thank you! 13