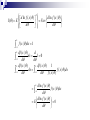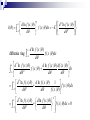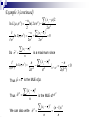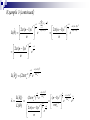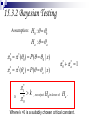Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Chapter 15:
Likelihood, Bayesian, and
Decision Theory
AMS 572
Group Members
Yen-hsiu Chen, Valencia Joseph, Lola Ojo,
Andrea Roberson, Dave Roelfs,
Saskya Sauer, Olivia Shy, Ping Tung
Introduction
"To call in the statistician after the experiment is done may be no more than
asking him to perform a post-mortem examination: he may be able to say what
the experiment died of."
- R.A. Fisher
Maximum Likelihood, Bayesian, and Decision Theory
are applied and have proven its selves useful and
necessary in sciences, such as physics, as well as research
in general.
They provide a practical way to begin and carry out an
analysis or experiment.
15.1
Maximum
Likelihood Estimation
15.1.1 Likelihood Function
Objective : Estimating the unknown parameters
θof a population distribution based on a random
sample χ1,…,χn from that distribution
Previous chapters : Intuitive Estimates
=> Sample Means for Population Mean
To improve estimation, R. A. Fisher (1890~1962)
proposed MLE in 1912~1922.
Ronald Aylmer Fisher (1890~1962)
The greatest of Darwin's
successors
Known for :
Notable Prizes :
Source: http://www-history.mcs.standrews.ac.uk/history/PictDisplay/Fisher.html
1912 : Maximum likelihood
1922 : F-test
1925 : Analysis of variance
(Statistical Method for
Research Workers )
Royal Medal (1938)
Copley Medal (1955)
Joint p.d.f. vs. Likelihood Function
Identical quantities
Different interpretation
Joint p.d.f. of X1 ,…, Xn :
A function of χ1,…,χn for given θ
Probability interpretation
n
f x1,..., xn f x1 f x 2 ... f xn f xi
i 1
Likelihood Function of θ :
A function of θfor given χ1,…,χn
No probability interpretation
n
L x1,..., xn f x1,..., xn f x1 ... f xn f xi
i 1
Example : Normal Distribution
Suppose χ1,…,χn is a random sample from
a normal distribution with p.d.f.:
2
(
x
)
1
f ( x | , 2 )
exp{
}
2
2
2
parameter ( , ), Likelihood Function:
2
n
L( , 2 )
i 1
( xi ) 2
1
[
exp{
}]
2
2
2
1
1
n
(
) exp{ 2
2
2
n
i 1
( xi ) 2 }
15.1.2 Calculation of
Maximum Likelihood Estimators (MLE)
MLE of an unknown parameter θ:
The value
function
x1,..., xn which maximizes the likelihood
Example of MLE: L
x1,..., xn
2 independent Bernoulli trials with success probability θ
θis known : 1/4 and 1/3
=>parameter space Θ= {1/4, 1/3}
Using Binomial distribution, the probabilities of observing
χ= 0, 1, 2 successes can be calculated
Example of MLE
Probability of ObservingχSuccesses
χ
the # of
successes
0
1
2
1/4
9/16
6/16
1/16
1/3
4/ 9
4/ 9
1/9
Parameter
space Θ
• When χ=0, the MLE of : 1/ 4
• When χ=1 or 2, the MLE of : 1/ 3
• The MLE is chosen to maximize L x
for observed χ
15.1.3 Properties of MLE’s
Objective
optimality properties in large sample
Fisher information (continuous case)
2
2
d ln f ( x | )
d ln f ( x | )
I ( )
f
(
x
|
)
dx
E
d
d
Alternatives of Fisher information
2
d ln f ( x | )
d ln f ( x | )
I ( ) E
Var
d
d
d 2 ln f ( x | )
d ln f ( x | )
I ( )
f ( x | )dx E
2
d
d
(1)
2
(2)
d ln f ( x | ) 2
d ln f ( x | )
I ( ) E
Var
d
d
f ( x | )dx 1
df ( x | )
d
dx
1 0
d
d
df ( x | )
df ( x | )
1
dx
d
d f ( x | ) f ( x | )dx
d ln f ( x | )
f ( x | )dx
d
d ln f ( x | )
E
0
d
d 2 ln f ( x | )
d ln f ( x | )
I ( )
f ( x | )dx E
2
d
d
2
d ln f ( x | )
f ( x | )dx
d
2
d ln f ( x | )
d ln f ( x | ) df ( x | )
f (x | )
dx
d 2
d
d
diffrentia ting
d 2 ln f ( x | ) d ln f ( x | )
1
f ( x | )dx
2
d
d
f (x | )
2
2
d ln f ( x | )
d ln f ( x | )
f ( x | )dx 0
2
d
d
MLE (Continued)
Define the Fisher information for an i.i.d. sample
X 1 , X 2, , X n i.i.d. sample from p.d.f f ( x | )
d 2 ln f ( X 1 , X 2 , , X n | )
I n ( ) E
2
d
d2
E 2 ln f ( X 1 | ) ln f ( X 2 | )
d
ln f ( X n | )
d 2 ln f ( X 1 | )
d 2 ln f ( X 2 | )
E
E
2
2
d
d
I ( ) I ( ) I ( ) nI ( )
d 2 ln f ( X n | )
E
2
d
MLE (Continued)
• Generalization of the Fisher information for
k-dimensional vector parameter
p.d.f. of an r.v. X is f ( x | ), where (1 , 2 ,
, k )
information matrix of , I ( ), is given by
ln f ( x | ) ln f ( x | )
I ij ( ) E
i
j
2
ln f ( x | )
E
i j
MLE (Continued)
• Cramér-Rao Lower Bound
A random sample X1, X2, …, Xn from p.d.f f(x|θ).
Let ˆ be any estimator of θ with E (ˆ) B( ), where B(θ) is the
bias of ˆ. If B(θ) is differentiable in θ and if certain regularity
conditions holds, then
2
1
B
(
)
Var (ˆ)
nI ( )
(Cramér-Rao inequality)
The ratio of the lower bound to the variance of any estimator of θ
is called the efficiency of the estimator.
An estimator has efficiency = 1 is called the efficient estimator.
15.1.4 Large Sample Inference Based
on the MLE’s
Large sample inference on unknown parameter θ
Var(ˆ)
estimate
1
nI ( )
n d 2 ln f ( X | )
1
i
I (ˆ)
d 2
n i 1
ˆ
100(1-α)% CI for θ
ˆ z
1
2
nI (ˆ)
ˆ z
1
2
nI (ˆ)
15.1.4 Delta Method for Approximating the
Variance of an Estimator
Delta method
estimate a nonlinear function h(θ)
suppose that E(ˆ) and Var(ˆ) is a known function of θ.
expand h(ˆ) around using first-order taylor series
h(ˆ) h( ) (ˆ )h( )
using
E (ˆ )
0, Var h(ˆ) h( )2Var (ˆ)
15.2
Likelihood Ratio Tests
15.2 Likelihood Ratio Tests
The last section presented an inference for pointwise
estimation based on likelihood theory. In this section, we
present a corresponding inference for testing hypotheses.
Let f (x; ) be a probability density function where is a real
valued parameter taking values in an interval that could be
the whole real line. We call the parameter space. An
alternative hypothesis H1will restrict the parameter to some
subset 1 of the parameter space . The null hypothesis H 0 is
then the complement of with respect to .
•
Consider the two-sided hypothesis
H 0 : 0 versus H1 : ,0 where 0 is a specified value.
We will test H 0 versus H on the basis of the random sample
1
X 1 , X 2 ,...., X n from f ( x; ) . If the nulln hypothesis holds, we
would expect the likelihood L( ) f ( xi ; ) to be
i 1
relatively large, when evaluated at the prevailing value 0 .
L( 0 )
Consider the ratio of two likelihood functions, namely
L(ˆ)
Note that 1 , but if H 0 is true should be close to 1;
while H 1 if is true, should be smaller. For a specified
significance level , we have the decision rule, reject H 0
in favor of H 1 if c , where c is such that P [ c]
0
This test is called the likelihood ratio test.
Example 1
Let X 1 , X 2 ,...., X n be a random sample of size n from a normal
distribution with known variance. Obtain the likelihood ratio for
testing H 0 : 0 versus H1 : 0.
L / X 1 ,....., X n i 1
n
1
2
2
( xi ) 2
e
2
2
n
2 2
(2 ) e
n
( xi ) 2
i 1
2 2
( xi )2
n
2
ln L( )
ln( 2 )
2
2 2
( xi )
ln L( )
0.
2
2
1
ln L( ) 2
2
< 0 . Thus
So
̂ x
̂ x
is a maximum since
is the MLE of
.
Example 1 (continued)
L( 0 )
L( ˆ )
n
2 2
( 2 )
( xi 0 ) 2
2 2
e
n
2 2
(( 2 )
( xi x ) 2
2 2
e
( xi 0 )2( xi x )2
2 2
e
[( xi x )( x0 )]2( xi x )2
2 2
e
( xi x )2 2 ( xi x )( x 0 )( x 0 )2 ( xi x )2
2 2
e
( x 0 )2
2 2
e
e
n ( x 0 ) 2
2 2
e
z02
2
z0 2
thus
So
c
P z0 c**
.
is equivalent to
thus
**
c
z
/2
e
2
c , or
2
*
z c
0
Example 2
Let X 1 , X 2 ,...., X n be a random sample from a Poisson distribution
with mean >0.
a. Show that the likelihood ratio test of H 0 : 0
versus H 1 : 0is based upon the statistic Y xi .
Obtain the null distribution of Y.
L i 1
n
xi
xi !
e
xi
e n
x !
i
ln L( ) xi ln n ln xi !
ln L( )
So ˆ
x
(x ) n 0
i
is a maximum since
( xi )
2
1 ˆ n
ln
L
(
)
|
n
0
2
2
ˆ
2
ˆ
ˆ
thus ˆ is the mle of
Example 2 (continued)
The likelihood ratio test statistic is:
xi
0 e n 0
L( 0 )
L(ˆ)
=
n 0
=
xi
xi
x!
i
i
ˆ
ˆ
e n
xi !
x
e
= 0
ˆ
xi
ˆ
e n n 0
xi n 0
And it’s a function of Y =
,
xi .
Under
H0
X 1 , X 2 ,...., X n ~ Poisson ( 0 ) Y ~ Poisson (n 0 )
Example 2 (continued)
b.
For 0 = 2 and n = 5, find the significance level of the test that
rejects H 0 if y 4 or y 17 .
The null distribution of Y is Poisson(10).
PH (Y 4) PH (Y 17) PH (Y 4) 1 PH (Y 16)
0
0
.029 1 .973 .056
0
0
Composite Null Hypothesis
The likelihood ratio approach has to be modified slightly when the null
hypothesis is composite. When testing the null hypothesis H 0 : 0
concerning a normal mean when
2
is unknown, the parameter space
{( , 2 ) : ,0 2 } is a subset of
R2
The null hypothesis is composite and 0 {( , 2 ) : 0 ,0 2 }
Since the null hypothesis is composite, it isn’t certain which value of
the parameter(s) prevails even under H 0. So we take the maximum of the
likelihood over 0
The generalized likelihood ratio test statistic is defined as
max 0 L( 0 )
max
L(ˆ)
0
Example 3
Let X 1 , X 2 ,...., X n be a random sample of size n from a normal
distribution with unknown mean and variance. Obtain the likelihood
ratio test statistic for testing H 0 : 0 versus H :
( , 0 2 ) 0 { , 2 0 2}
In Example 1, we found the unrestricted mle:
1
0
̂ x
Now
L , / X 1 ,....., X n i 1
2
n
n
n
i 1
i 1
1
2,
2
e
( xi ) 2
2 2
= (2 )
2
n
2
n
( xi ) 2
i 1
e
2 2
Since ( xi x ) 2 ( xi ) 2 L( x , 2 ; x) L( , 2 ; x)
we only need to find the value of 2 maximizing L( x , ; x).
2
Example 3 (continued)
( xi )2
n
2
ln L( , )
ln( 2 )
2
2
2
2
2
n ( xi x )
ln L( x , )
0
2
2
4
2
2
2
So ̂ 2
2
( 2 )
2
(
x
x
)
i
is a maximum since
n
ln L( x , )
2
n
2
2
4
2
(
x
x
)
i
6
n
| 2 ˆ 2
0
4
2(ˆ )
Thus ̂ x is the MLE of .
Thus
̂ 2
2
(
x
x
)
i
n
We can also write ˆ
2
.
is the MLE of
2
(
x
x
)
i
n
2
(n 1) s 2
n
Example 3 (continued)
n
2
n
2 (n 1) s
ˆ
L( )
e
n
2
n
( xi x ) 2
i 1
2 ( n 1) s 2
n
2
n ( n 1) s 2
2 (n 1) s
2 ( n 1) s 2
e
n
2
n
2
2 (n 1) s 2n
e
n
2
n
2 2
( n 1) s 2
L(ˆ0 ) (2o ) e
2 o 2
n
2 2
( n 1) s 2
L( 0 )
(2o ) e
n
L(ˆ)
2
2 (n 1) s 2
n
2 o 2
e
n
2
n
2
(n 1) s
e
2
n o
2
( n 1) s 2
2 o
2
e
n
2
Example 3 (continued)
Rejection region:
so
n
2
c,
u
2
where u
u e k
define
such that PH 0 [ c]
n
2
h(u) u e
u
2
(n 1) s 2
o2
and
n
u
1
2
2
n
2
u
2
n
1
h (u ) u e u e
2
2
n
u
1
1 2 2
u e (n u ) u n, u 0
2
'
So
c
where
implies
u c1
or
u c2
PH0 (c1 n21 c2 ) 1
~ 2 (n 1)
15.3 : Bayesian Inference
Bayesian inference refers to a statistical
inference where new facts are presented
and used draw updated conclusions on a
prior belief. The term ‘Bayesian’ stems
from the well known Bayes Theorem
which was first derived by Reverend
Thomas Bayes.
Thomas Bayes (c. 1702 – April 17, 1761)
Source: www.wikipedia.com
Thomas Bayes (pictured above) was a Presbyterian minister and a
mathematician born in London who developed a special case of Bayes’
theorem which was published and studied after his death.
Bayes’ Theorem (review): f (A|B) = f (A ∩ B)
/f
(B) = f (B | A) f (A) / f(B) (15.1)
since, f (A ∩ B)= f (B ∩ A) = f (B | A) f (A)
Some Key Terms in Bayesian Inference…
…in plain English
•prior distribution – probability tendency of an uncertain quantity, θ,
that expresses previous knowledge of θ from, for example, a past
experience, with the absence of some proof
•posterior distribution – this distribution takes proof into account and
is then the conditional probability of θ. The posterior probability is
computed from the prior and the likelihood function using Bayes’
theorem.
•posterior mean – the mean of the posterior distribution
•posterior variance – the variance of the posterior distribution
•conjugate priors - a family of prior probability distributions in which
the key property is that the posterior probability distribution also
belongs to the family of the prior probability distribution
15.3.1 Bayesian Estimation
So far we’ve learned that the Bayesian approach treats θ as a random variable
and then data is used to update the prior distribution to obtain the posterior
distribution of θ. Now lets move on to how we can estimate parameters using
this approach.
(Using text notation)
Let θ be an unknown parameter based on a random sample, x1, x2, …, xn from
a distribution with pdf/pmf f (x | θ).
Let π (θ) be the prior distribution of θ.
Let π *(θ | x1, x2, …, xn) be the posterior distribution.
**Note that π *(θ | x1, x2, …, xn) is the condition distribution of θ given the
observed data, x1, x2, …, xn.
If we apply Bayes Theorem (Eq. 15.1), our posterior distribution becomes:
f (x1, x2, …, xn | θ) π(θ)
f (x1, x2, …, xn | θ)π(θ)
dθ
=
f (x1, x2, …, xn | θ) π(θ)
f *(θ | x1, x2, …, xn)
(15.2)
*Note that f *(θ | x1, x2, …, xn) is the marginal PDF of X1, X2, …,Xn
Bayesian Estimation (continued)
As seen in equation 15.2, the posterior distribution represents what is
known about θ after observing the data X = x1, x2, …, xn . From earlier
chapters, we know that the likelihood of a variable θ is f (X | θ) .
So, to get a better idea of the posterior distribution, we note that:
posterior distribution
i.e.
π *(θ | X)
likelihood x prior distribution
f (X | θ) x π (θ)
For a detailed practical example of deriving the posterior mean and
using Bayesian estimation, visit:
http://www.stat.berkeley.edu/users/rice/Stat135/Bayes.pdf
☺
Example 15.26
Let x be the number of successes from n i.i.d. Bernoulli trials with
unknown success probability p=θ. Show that the beta distribution is a
conjugate prior on θ.
★
★ f (x)
Goal
★
f (x | ) () f (x,)
f (x, )d
f (x | ) ( )d
f (x, )
( ) ( | x)
f (x)
*
f (x | ) ( )
f (x | ) ( )d
Example 15.26 (continued)
X has a binominal distribution of n and p= θ
f (x | ) ( ) (1 )
n
x
x
nx
x=1,2…,n
Prior distribution of θ is the beta distribution
(a b) a1
( )
(1 ) b1
(a)(b)
0≤ θ ≥1
(a b) a1
f (x, ) f (x | ) ( ) ( )
(1 ) nx b1
(a)(b)
n
x
f (x)
1
0
(a b) (a x)(n b x)
f (x, )d ( )
(a)(b)
(n a b)
n
x
Example 15.26 (continued)
f (x, )
( ) ( | x)
f (x)
(n a b)
x a1
nx b1
(1 )
(x a)(n x b)
*
It is a beta distribution with parameters (x+a) and (n-x+b)!!
Notes:
1. The parameters a and b of the prior distribution
may be interpreted as prior successes and prior
failures, with m=a+b being the total number of
prior observations.
After actually observing x successes and n-x
failures in n i.i.d Bernoulli trials, these parameters
are updated to a+x and b+n-x, respectively.
2. The prior and posterior means are, respectively,
a
m
and
a x
mn
15.3.2 Bayesian Testing
Assumption:
H 0 : 0
H a : a
*0 * (0 ) P( 0 | x)
(a ) P( a | x)
*
a
*
If
k
*
1
*
0
1
*
0
*
a
H0 in favor of Ha .
, we reject
Where k >0 is a suitably chosen critical constant.
Abraham Wald
(1902-1950)
was the founder of
Statistical decision theory.
His goal was to
provide a unified
theoretical framework
for diverse problems.
i.e. point estimation,
confidence interval
estimation and hypothesis testing.
Source: http://www-history.mcs.st-andrews.ac.uk/history/PictDisplay/Wald.html
Statistical Decision Problem
The goal: is to choose a decision d from a set of possible
decisions D, based on a sample outcome (data) x
Decision space is D
Sample space: the set of all sample outcomes denoted by x
Decision Rule: δ is a function δ(x) which assigns to every
sample outcome x є X, a decision d є D.
Continued…
Denote by X the R.V. corresponding to x and the probability
distribution of X by f (x|θ).
The above distribution depends on an unknown parameter θ
belonging to a parameter space Θ
Suppose one chooses a decision d when the true parameter is θ, a
loss of L (d, θ) is incurred also known as the loss function.
The decision rule is assessed by evaluating its expected loss called
the risk function:
R(δ, θ) = E[L(δ(X),θ)] = ∫xL(δ(X),θ) f (x|θ)dx.
Example
Calculate and compare the risk
functions for the squared error
loss of two estimators of success
probability p from n i.i.d.
Bernoulli trials. The first is the
usual sample proportion of
successes and the second is the
bayes estimator from Example
15.26:
ṗ1 = X/n
and
ṗ2 = a + X/ m + n
Von Neumann (1928): Minimax
Source:http://jeff560.tripod.com/
How Minimax Works
Focuses on risk avoidance
Can be applied to both zerosum and non-zero-sum games
Can be applied to multi-stage
games
Can be applied to multi-person
games
Classic Example: The Prisoner’s Dilemma
Each player evaluates
his/her alternatives,
attempting to minimize
his/her own risk
From a common sense
standpoint, a sub-optimal
equilibrium results
Prisoner B
Stays
Silent
Prisoner
A Stays
Silent
Prisoner
A
Betrays
Both serve
six months
Prisoner B
Betrays
Prisoner A
serves ten
years
Prisoner B
goes free
Prisoner A
goes free
Prisoner B
serves ten
years
Both serve
two years
Classic example: With Probabilities
When disregarding the
probabilities when playing
the game, (D,B) is the
equilibrium point under
minimax
With probabilities
(p=q=r=1/4), player one
will choose B. This is…
Two player game with simultaneous moves,
where the probabilities with which player two
acts are known to both players.
2
Action A
[P(A)=p]
Action B
[P(B)=q]
Action C
[P(C)=r]
Action D
[P(D)=1p=q=r]
Action A
-1
1
-2
4
Action B
-2
7
1
1
Action C
0
-1
0
3
Action D
1
0
2
3
1
…how Bayes works
View {(pi,qi,ri)} as θi
where i=1 in the
previous example
Letting i=[1,n] we get a
much better idea of what
Bayes meant by “states
of nature” and how
probabilities of each
state enter into one’s
strategy
Conclusion
We covered three theoretical approaches in our presentation
Likelihood
provides statistical justification for many of the methods used in
statistics
MLE - method used to make inferences about parameters of the
underlying probability distribution of a given data set
Bayesian and Decision Theory
paradigms used in statistics
Bayesian Theory
probabilities are associated with individual event or statements
rather than with sequences of events
Decision Theory
Describe and rationalize the process of decision making, that is,
making a choice of among several possible alternatives
Source: http://www.answers.com/maximum%20likelihood, http://www.answers.com/bayesian%20theory, http://www.answers.com/decision%20theory
The End
Any questions for the group?