Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Wireless security wikipedia , lookup
Distributed firewall wikipedia , lookup
Server Message Block wikipedia , lookup
Cracking of wireless networks wikipedia , lookup
Dynamic Host Configuration Protocol wikipedia , lookup
Zero-configuration networking wikipedia , lookup
Cross-site scripting wikipedia , lookup
Remote Desktop Services wikipedia , lookup
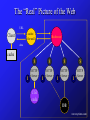
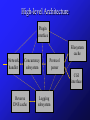
HTTP for DB Dummies Steve Gribble [email protected] The Web • HTTP 1.0 model (slowly fading out, replaced by HTTP 1.1): GET /document.html Client cache TCP Server The Web Client cache Server Basics of HTTP Structure of a Request <METHOD> <URL> <HTTPVERSION>\r\n <HEADERNAME>: <HEADERVAL>\r\n <HEADERNAME>: <HEADERVAL>\r\n … \r\n <DATA, IF POST> GET /test/index.html?foo=bar+baz&name=steve HTTP/1.0\r\n Connection: Keep-Alive\r\n User-Agent: Mozilla/4.07 [en] (X11; I; Linux 2.0.36 i686)\r\n Host: ninja.cs.berkeley.edu:5556\r\n Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/png, */*\r\n Accept-Encoding: gzip\r\n Accept-Language: en\r\n Accept-Charset: iso-8859-1,*,utf-8\r\n \r\n Structure of a Response <HTTPVERSION> <STATUS CODE> <MSG>\r\n <HEADERNAME>: <HEADERVAL>\r\n <HEADERNAME>: <HEADERVAL>\r\n … \r\n <DATA, IF NECESSARY> HTTP/1.0 200 OK Server: Netscape-Enterprise/2.01 Date: Thu, 04 Feb 1999 00:28:19 GMT Accept-ranges: bytes Last-modified: Wed, 01 Jul 1998 17:07:38 GMT Content-length: 1848 Content-type: text/html TCP level analysis HTTP 1.0 FTP ( >=2nd file) Interesting TCP gotchas • Mandatory roundtrips – – – – TCP three-way handshake get request, data return new connections for each inlined image (parallelize) lots of extra syn or syn/ack packets • Slow-start penalties – can show only affects fast networks, not modems • Lots of TCP connections to server – spatial/processing overhead in server (TCP stack) – many protocol control block (PCB) TIME_WAIT entries – unfairness because of loss of congestion control info Fix? • Persistent HTTP – in HTTP/1.0, add “Connection: Keep-Alive\r\n” header – in HTTP/1.1, P-HTTP built in • Does it help? – mostly for server-side reasons, not network efficiency – allows pipelining of multiple requests on one connection • Does it hurt? – how does a client know when document is returned? – when does the connection get dropped? • idle timeouts on server side • client drops connections • server needs to reclaim resources HTTP/1.0 Client Methods • GET – fetch and return a document – URL can be overloaded to submit form data • GET /foo/bar.html?x=bar&bam=baz • POST – submit a form, and receive response • HEAD – like GET, but only return HTTP headers and not the data itself. Useful for caching • PUT, DELETE, LINK, UNLINK – not really used - big security issues if not careful HTTP/1.0 Status Codes • Family of codes, with 5 “types” – 1xx: informational – 2xx: successful, e.g. 200 OK – 3xx: redirection (gotcha: redirection loops?) • 301 Moved Permanently • 304 Not Modified – 4xx: Client Error • • • • 400 Bad Request 401 Unauthorized 403 Forbidden 404 Not Found – 5xx: Server Error • 501 Not Implemented • 503 Service Unavailable HTTP/1.0 Headers (case insensitive?) • Allow - returned by server – Allow: GET, HEAD – never used in practice - clients know what they can do • Authorization - sent by client – – – – Authorization: <credentials> “Basic Auth” is commonly used <credentials> = Base64( username:password ) ok if inside an SSL connection (encrypted) • Content-Encoding - sent by either – Content-Encoding: x-gzip – selects an encoding for the transport, not the content – sadly, no common support for encodings (Windows) HTTP/1.0 Headers continued • Content-Length - sent by either – Content-Length: 56 – how much payload is being sent? – necessary for persistent HTTP, or for POSTs • Content-Type - sent by server – Content-Type: text/html – what MIME type the payload is – nasty one: multipart/mixed • Date – Date: Tue, 15 Nov 1994 08:12:31 GMT – 3 accepted date formats (RFC 822, RFC 850, asctime()) HTTP/1.0 headers, continued • Expires - sent by server – Expires: Thu, 01 Dec 1994 16:00:00 GMT – primitive caching expiration date – cannot force clients to update view, only on refresh • From - sent by client – From: [email protected] – not really used • If-Modified-Since - sent by client – If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT – server returns data if modified, else “304 Not Modified” HTTP/1.0 headers, con’t • Last-Modified - returned by server – Last-Modified: Sat, 29 Oct 1994 19:43:31 GMT – semantically imprecise - file modification? Record timestamp? Date in case file dynamically generated? – used with If-Modified-Since and HEAD method • Location - returned by server – Location: http://www.cs.ubc.ca – used in case of 3xx redirections • Pragma - sent by client or server – Pragma: no-cache – extensibility mechanism. No-cache is the only popularly used pragma, AFAIK HTTP/1.0 headers, con’t • Referer - sent by client – Referer: http://www.xxx-smut.com – specifies address from which request was generated – all sorts of privacy issues - must be careful with this • Server - returned by server – Server: Netscape-Enterprise/2.01 – identifies server software. why? (measurement…) • User-Agent - sent by client – – – – User-Agent: Mozilla/4.07 [en] (X11; I; Linux 2.0.36 i686) identifies client software why? Optimize layout, send based on capability of client. Hint: just pretend to be Netscape. MSIE does.. HTTP/1.0 Server headers • WWW-Authenticate - sent by server – WWW-Authenticate: <challenge> – tells client to resend request with Authorization: header • Incrementally added hacks: – – – – – Accept: image/gif, image/jpeg, text/*, */* Accept-Encoding: gzip Accept-Language: en Retry-After: (date) or (seconds) [Set-]Cookie: Part_Number="Rocket_Launcher_0001"; Version="1"; Path="/acme" – Title: (title) HTTP/1.1 Additions • Lots of problems associated with HTTP/1.0 – the network problems we talked about before – very poor cache consistency models – difficulty implementing multi-homed servers • want 1 IP address with multiple DNS names - how? – hard to precalculate content-lengths – connection dropped = lost data • no chunking • HTTP/1.1 is bloated spec to fix these problems – introduces many complexities – no longer an easy protocol to implement HTTP/1.1 - a Taste of the New • Host: www.ninja.com – clients MUST send this - fixes multi-homed problem – already in most 1.0 and 1.1 clients • Range: bytes=300-304,601-993 – useful broken connection recovery (like FTP recovery) • Age: <seconds, date> – expiration from caches • Etag: fa898a3e3 – unique tag to identify document (strong or weak forms) • Cache-control: <command> – marking documents as private (don’t keep in caches) • “chunked” transfer encoding – segmenting of documents - don’t have to calculate entire document length. Useful for dynamic query responses.. Architectural Complexities Caches Client TCP Server Original web: cache • Problem: no locality – non-local access pattern (trans-atlantic access) – servers serving the same bytes millions of times to localized communities of users Solution: Cache Hierarchy Client cache Cache Server Cache Cache • NLANR cache hierarchy most widely developed – informally uses Squid cache – root servers squirt out 30GB per day – anybody can join... Gotchas • Staleness – HTTP/1.1 cache consistency mechanisms mostly solve • Security – what happens if I infiltrate a cache? – servers/clients don’t even know this is happening – e.g.: AOL used to have a very stale cache, but has since moved to Inktomi • Ad clickthrough counts – how does Yahoo know how many times you accessed their pages, or more importantly, their ads? CGI-BIN gateways URL URL Client httpd data data cache CGI code File System • CGI = “Common Gateway Interface” – interface that allows independent authors to develop code that interacts with web servers – dynamic content generation, especially from scripts – CGI programs execute in separate process, typically CGI-BIN to DB gateways URL URL Client httpd ODBC / JDBC / etc. data data cache CGI code File System DB • JDBC/ODBC gateways – single-node DB, often running on remote host – long, blocking operations, usually – nasty transactional issues - how does client know that action succeeded or failed? • Datek/E*Trade troubles cgi-bin security • Lots of gotchas with CGI-BIN programs – buffer overflows (maximum length checks?) – shell metacharacter expansion • what happens if you put `cat /etc/passwd` in a form field? – sending mail, reading files – redirection - allows bypassing IP address-based security Multiple server support • We’ve seen how single IP address can server multiple web sites with “Host:” HTTP/1.1 field – what about having multiple physical hosts serving a single web site? – useful for scalability reasons Server Server Client TCP Server Server cache www.hotbot.com Solutions • DNS round-robin – assign multiple IP addresses to single domain name – client selects amongst them in order – shortcomings: • exposes individual nodes to clients • can’t take into account machine capabilities (multiprocessors) and currently experienced load • Front-end redirection – single front-end node serves HTTP redirect to selected backend node – introduces extra round-trip, FE is single point of failure More solutions • IP-level multiplexing through smart router – munge IP packets and send them to selected host – Cisco, SUN, etc. make hardware to do this • Cisco LocalDirector – tricky state management issues, failure semantics • “Smart Clients” – Netscape “Proxy Autoconfig” (PAC) mechanism • only useful if connecting via proxy • Javascript selects from amongst proxies – No HTTP protocol support for smart client access to web servers The “Real” Picture of the Web URL cache / firewall Client Redirector data cache I $ $ $ $ HTTP Server HTTP Server HTTP Server HTTP Server I I I CGI code DB www.nytimes.com Web Characteristics UCB HIP trace • Web traffic circa 1997 is primarily: – GIF data • 27% of bytes transferred, 51% of files transferred • average size 4.1 KB – JPEG data • 31% of bytes transferred, 16% of files transferred • average size: 12.8 KB – HTML data • 18% of bytes transferred, 22% of files transferred • average size: 5.6 KB • File sizes, server latency, access patterns – all heavy-tailed: most small, but some very large – self-similarity everywhere - lots and lots of bursts Server-Side Architecture Goals of server • High capacity web servers must do the following: – rapidly update corpus of content served – be efficient • latency: serve content as quickly as possible • throughput: parallel requests from large numbers of clients – be extensible • data-types • cgi-bin programs • server plug-ins – not crash – remain secure High-level Architecture Plugin Interface Filesystem cache Network handler Concurrency subsystem Protocol parser CGI interface Reverse DNS cache Logging subsystem Concurrency • How many simultaneously open connections must a server handle? – 1,000,000 hits per day • 12 hits per second average • upwards of 50 hits per second peak (bursts, diurnal cycle) – latency: • • • • 10 milliseconds (out of memory) ==> 1 connection 50 milliseconds (off of disk) ==> 3 connections 200 milliseconds (CGI + disk) ==> 10 connections 5 seconds (CGI to DB gateway) ==> 250 connections • Depending on expected usage, need very different concurrency models Strategies • Single process, single thread, serialized – simplest implementation, worst performance – perfectly fine for low traffic sites • Multiple processes, single serialized thread / process – Apache web server model – expensive (context switching, process state, …) • Multithreaded [and multiprocess] – complex synchronization primitives needed – thread creation/destruction vs. thread pool management • Event driven, asynchronous I/O – eliminates context switch overhead, better memory mgmt – very complex and delicate program flow Disk I/O • File system overhead – file system buffer management not optimal – don’t need many of the file system facilities • modifying files, moving files, locking files, seeks… • Alternatives: – directly interact with disk • very fast, very complex – in-memory caching on top of file system • works well given high locality of server access • be careful to not suffer from double-buffering • Interaction: thread subsystem and disk – balanced system - enough threads to saturate disk I/O Network I/O • Typical server behaviour rough on network stack – multiple outstanding connections – very rapid TCP creation and teardown – often, very slow last-hop network segment • Redundant operations performed – checksum calculations, byte swapping, … • Inefficiencies at packet level – header, body, FIN usually three separate round-trips • Poor network stack implementations – TIME_WAIT and IDLE PCB entries on single linked list – Nagle’s algorithm invoked when it shouldn’t be Inline scripting • Technology: server-side includes (SSIs) – script embedded inside content, interpreted before sent back to client – dynamically computed content inside templates • authorization (cert lookup or authentication) • DB lookup (inventory lists, product prices, …) • Challenges – similar to CGI: • security • efficiency (latency and throughput) Cheetah (Exokernel) • Direct access to hardware primitives – disk, network - eliminate costly OS generalizations – scatter/gather IO primitives – allow for common disk/network buffers (eliminate copy) • Compiler-assisted ILP – eliminate redundancies, staging inefficiencies • HTTP-specialized network stack and file system – precomputed HTTP headers, minimal copies – minimize network packets (e.g.piggyback FINs with data) – precomputed TCP/IP checksums Some Parting Thoughts Other things to keep in mind • There are non-humans on the web – spiders, crawlers, worms, etc, may behave badly • infinite FTP directory traps, request bursts, ... • Netscape, MSIE, and Apache set defacto standards – their semantics may subtly differ from standards – error-tolerance of popular clients/servers means that everybody must achieve same levels of tolerance • otherwise, you appear to be broken to users • e.g.: Netscape not parsing comments properly • SSL/X.509 – transport-level security: fixes up basic auth problems – eliminates caching or proxy mechanisms