Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
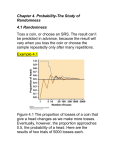
1 Random Experiments from Random Experiments 1.1 Bernoulli Trials The simplest type of random experiment is called a Bernoulli trial. A Bernoulli trial is a random experiment that has only two possible outcomes: success or failure. If you ‡ip a coin and want it to come up heads, this is a Bernoulli trial where heads is success, and tails is failure. If you roll two dice on a monopoly board, and you want it to come up doubles to get you out of jail, this is a Bernoulli trial Success is rolling doubles; everything else is a failure. If one of the dice gets hung up on the Chance Deck, that’s a "do-over." The only outcomes that count are success or failure: doubles or not. If you are playing Rock-Paper-Scissors, and want to win, then your rock will break your opponent’s scissors; your scissors will cut your opponent’s paper, and your paper will cover your opponent’s rock. All these are successes. But your opponent’s rock will break your scissors; their scissors will cut your paper, and their paper will cover your rock. All these are failures. The other possibilities are both rocks, both scissors or both paper; none of these count, they all lead to "do-overs." So under the familiar rules, Rock-Paper-Scissors is a Bernoulli trial. There is no way to predict the result of an individual instance of a Bernoulli trial before it occurs. (Unless of course, the Bernoulli trial is such that one outcome is actually not possible.) Assuming that both success and failure are possible, to be a random trial, the result of an individual try must be unpredictable. Here are some examples of Bernoulli trails, and the probability models that seems to re‡ect them best: 1.1.1 Fair Coin Toss: A fair coin is tossed, and one side is chosen as a success. The coin is tossed once: Success Failure 1 p 12 2 1.1.2 A Fair Die Toss A fair six sided die is tossed. Each face of the die has a number from 1 to 6. One of those numbers is declared a success. The die is rolled once: p 1.1.3 Success Failure 1 6 5 6 A Ball is Drawn From an Urn An urn is …lled with n balls, and exactly m of those balls are of a speci…c color. (For some reason it’s always an urn in advanced math courses. Otherwise it 1 might just be a box, or a deck of cards, or any other drawing-from-a-group-andlooking-for-one-type kind of experiment.) One ball is drawn, without looking, from the urn: Success Failure m 1 p m n n 1.1.4 Two fair dice are thrown Two fair six sided dice are thrown. Each face of the die has a number from 1 to 6. One can call an odd sum a success, but then the accepted probability model is Success Failure 1 p 12 2 Unless you are unsure of the fairness of the dice or the toss, it would do just as well to ‡ip a coin. One could call doubles a success, but then the accepted probability model is p Success Failure 1 6 5 6 Again unless you are unsure of the fairness of the dice or the toss, it would do just as well to roll one die. One could call doubles a failure and not doubles a success and obtain p Success Failure 5 6 1 6 But rolling one die would do just the same. One could declare one of the possible totals that come up a success. Here the probability model will depend on the number, but the various possibilities are k Success Failure 1 35 2 or 12 p 36 36 1 17 3 or 11 p 18 18 1 11 4 or 10 p 12 12 1 8 5 or 9 p 9 9 5 31 6 or 8 p 36 36 1 5 7 p 6 6 Now 7 is a popular sum to make a success, but mathematically one might just as well just roll one fair die. One could call a combination of totals a success. With the information above one can compute the correct probability of success. One popular pair to declare a success is f7; 11g: Then we have p Success Failure 2 9 7 9 2 1.1.5 The Generic Bernoulli Trial In this experiment we assume we have a Bernoulli trial with a known probability of success. The model is simply p 1.2 Success p Failure 1 p: Using Bernoulli Trials to Create Larger Experiments In almost every situation where we are looking at a random event as a Bernoulli trial, we are thinking of repeating the trial a large number of times. We want to create a larger experiment by repeating the trial a large number of times, and counting of the number of successes. We will start small and work out way up. Suppose we toss a fair die and consider a 1 to be a success. First we create an experiment where we toss a fair die twice, and set a sample space that keeps track of the outcome of every toss: fSS; SF; F S; F F g: Of course SS means two successes, SF means a success followed by a failure, F S is a failure and a success, and F F is two failures. Now we clearly want to assume that the tosses are independent. Thus the outcome of the …rst toss and the second toss are mathematically independent. We can compute the probabilities of these events by thinking of them as two separate independent events. We will denote the probability of the larger experiment by p2 . Thus p2 (SS) p2 (SF ) p2 (F S) p2 (F F ) 1 6 1 = p(S)p(F ) = 6 5 = p(F )p(S) = 6 5 = p(F )p(F ) = 6 = p(S)p(S) = 1 1 = 6 36 5 5 = 6 36 1 5 = 6 36 5 25 = 6 36 Of course, we want a probability model for the number of successes. Now the events we are interested in are 0 Success 1 Success 2 Success = fF F g = fSF; F Sg = fSSg We compute these, but include a row that shows where the probabilities came from # Success 0 1 2 p2 (#) 1 16 16 2 16 56 1 56 56 1 5 25 p2 (#) 36 18 36 3 Next we try an experiment based on three die tosses. The sample space that keeps track of the outcome of every toss is fSSS; SSF; SF S; SF F; F SS; F SF; F F S; F F F g: The outcomes of the …rst toss, the second toss, and the third toss are assumed to be mathematically independent. We can compute the probabilities of these events by thinking of them as three separate independent events. We will denote the probability of the larger experiment by p3 . Thus 1 6 1 p(S)p(S)p(F ) = 6 1 p(S)p(F )p(S) = 6 1 p(S)p(F )p(F ) = 6 5 p(F )p(S)p(S) = 6 5 p(F )p(S)p(F ) = 6 5 p(F )p(F )p(S) = 6 5 p(F )p(F )p(F ) = 6 p3 (SSS) = p(S)p(S)p(S) = p3 (SSF ) = p3 (SF S) = p3 (SF F ) = p3 (F SS) = p3 (F SF ) = p3 (F F S) = p3 (F F F ) = 1 6 1 6 5 6 5 6 1 6 1 6 5 6 5 6 1 1 = 6 216 5 5 = 6 216 1 5 = 6 216 5 25 = 6 216 1 5 = 6 216 5 25 = 6 216 1 25 = 6 216 5 125 = 6 216 The events we are interested in are 0 1 2 3 Success Success Success Success = = = = fF F F g fSF F; F SF; F F Sg fSSF; SF S; F SSg fSSSg We notice that the probabilities of the sample points that make up each one of these events are all the same: 1 6 0 5 6 3 p3 (F F F ) = p3 (SF F ) = p(F SF ) = p(F F S) = 1 6 p3 (SSF ) = p(SF S) = p(F SS) = 5 6 p3 (SSS) = 1 6 3 5 6 4 0 1 2 5 6 5 6 2 1 We have written these probabilities this odd way to illustrate the strong pattern they exhibit. The probability of any one of these sample points is just 16 to a power given by the number of S’s times 56 to a power given by the number of F ’s. Thus the probability model we are searching for is # Success p(#) p(#) 0 1 ( 16 )0 ( 56 )3 125 216 1 3 ( 16 )0 ( 65 )3 25 72 2 3 ( 16 )0 ( 56 )3 5 72 3 1 ( 61 )0 ( 56 )3 1 216 Of course, the two threes in this come from the fact that both fSF F; F SF; F F Sg and fSSF; SF S; F SSg have three entries. Next we try moving to an experiment based on four coin tosses. A few things come quickly, the sample space will be twice as big fSSSS; SSSF; SSF S; SSF F; SF SS; SF SF; SF F S; SF F F F SSS; F SSF; F SF S; F SF F; F F SS; F F SF; F F F S; F F F F g: The outcomes of the four tosses will be assumed to be mathematically independent. We can compute the probabilities of these events by counting the number of successes and failures. We will denote the probability of the larger experiment by p4 . By example 5 6 0 = 1 6 4 p4 (SSSS) 5 6 1 = 1 6 3 p4 (SSF S) 5 6 2 = 1 6 2 p4 (SF F S) 5 6 3 = 1 6 1 p4 (SF F F ) 5 6 4 = 1 6 0 p4 (F F F F ) The events we are interested in are 0 1 2 3 4 Success Success Success Success Success = = = = = fF F F F g fSF F F; F SF F; F F SF; F F F Sg fSSF F; SF SF; SF F S; F F SS; F SF S; F SSF g fSSSF; SSF S; SF SS; F SSSg fSSSSg Again the probabilities of the sample points that make up each one of these events are all the same. Thus the probability model we are searching for is # Success p4 (#) 0 1 ( 16 )0 ( 56 )4 1 4 ( 16 )1 ( 65 )3 5 2 6 ( 16 )2 ( 56 )2 3 4 ( 16 )3 ( 56 )1 4 1 ( 16 )4 ( 56 )0 If we try to move on to 5; 6 or even n repeated tosses, we can predict the form of the result we will get # Success pn (#) k = 0; 1; 2; 3 : : : n 1 k ( 56 )n k n Pk ( 6 ) where n Pk is a natural number that counts the number of di¤erent ways k S’s and (n k) F ’s can be lined up. Here are some charts that illustrate the probability models for various n. n=2 p=1/6 0.8 0.7 0.6 0.5 p 0.4 0.3 0.2 0.1 0 0 1 2 Successes n=3 p=1/6 0.7 0.6 0.5 p 0.4 0.3 0.2 0.1 0 0 1 2 3 Successes n=6 p=1/6 0.45 0.4 0.35 0.3 p 0.25 0.2 0.15 0.1 0.05 0 0 1 2 3 Successes 6 4 5 6 n=10 p=1/6 0.35 0.3 0.25 p 0.2 0.15 0.1 0.05 0 0 1 2 3 4 5 6 7 8 9 10 Successes n=20 p=1/6 0.25 0.2 p 0.15 0.1 0.05 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Successes Notice that as the number of trials gets larger, the probabilities of the larger number of success drops o¤ to almost nothing. If we take even more trials and draw those charts, we might as well leave those very unlikely cases o¤ the chart to make it result clearer. The n = 20 might be better presented as n=20 p=1/6 0.25 0.2 p 0.15 0.1 0.05 0 0 1 2 3 4 Successes For n = 30 7 5 6 7 8 n=30 p=1/6 0.25 0.2 0.15 0.1 0.05 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 After a while, the probabilities that there are too few success becomes very small,too small to keep on the chart. We simply leave them o¤. n=30 p=1/6 0.25 0.2 p 0.15 0.1 0.05 0 0 1 2 3 4 5 6 7 8 9 10 11 Successes Now all the scales in these charts are changing, but those changes do illustrate how regular these probability models become. It takes more than a couple of trials, but by the time we get to 20 trials, the probability is beginning to take on a fairly regular shape. The most remarkable thing about this emerging shape is that it appears in every other experiment based on the repetition of a Bernoulli trial. Suppose we ‡ip a fair coin instead of tossing a die. We will consider a heads to be a success. First we create an experiment where we ‡ip the coin twice, and set a sample space that keeps track of the outcome of every ‡ip: fSS; SF; F S; F F g: We assume that the outcome of the …rst toss and the second toss are mathematically independent. We can compute the probabilities of the larger experiment 8 and denote the result by p2 . Thus p2 (SS) p2 (SF ) p2 (F S) p2 (F F ) 1 2 1 = p(S)p(F ) = 2 1 = p(F )p(S) = 2 1 = p(F )p(F ) = 2 = p(S)p(S) = 1 1 = 2 4 1 1 = 2 4 1 1 = 2 4 1 1 = 2 4 Of course, we want a probability model for the number of successes. Now the events we are interested in are 0 Success 1 Success 2 Success = fF F g = fSF; F Sg = fSSg We compute these, but include a row that shows where the probabilities came from # Success 0 1 2 p2 (#) 1 12 12 2 12 12 1 12 12 1 1 1 p2 (#) 4 2 4 Next we try an experiment based on three coin ‡ips. The sample space that keeps track of the outcome of every ‡ips is fSSS; SSF; SF S; SF F; F SS; F SF; F F S; F F F g: The outcomes of the …rst toss, the second toss, and the third toss are assumed to be mathematically independent. We will denote the probability of the larger experiment by p3 . Thus 1 2 1 p(S)p(S)p(F ) = 2 1 p(S)p(F )p(S) = 2 1 p(S)p(F )p(F ) = 2 1 p(F )p(S)p(S) = 2 1 p(F )p(S)p(F ) = 2 1 p(F )p(F )p(S) = 2 1 p(F )p(F )p(F ) = 2 p3 (SSS) = p(S)p(S)p(S) = p3 (SSF ) = p3 (SF S) = p3 (SF F ) = p3 (F SS) = p3 (F SF ) = p3 (F F S) = p3 (F F F ) = 9 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 1 = 2 8 1 1 = 2 8 1 1 = 2 8 1 1 = 2 8 1 1 = 2 8 1 1 = 2 8 1 1 = 2 8 1 1 = 2 8 The events we are interested in are 0 1 2 3 Success Success Success Success = = = = fF F F g fSF F; F SF; F F Sg fSSF; SF S; F SSg fSSSg We notice that the probabilities of the sample points that make up each one of these events are all the same: 1 2 0 1 2 3 p3 (F F F ) = p3 (SF F ) = p(F SF ) = p(F F S) = 1 2 p3 (SSF ) = p(SF S) = p(F SS) = 1 2 p3 (SSS) = 1 2 3 1 2 1 2 1 2 1 2 2 1 0 We have written these probabilities this odd way to illustrate the resemblance to the dies toss example. The probability of any one of these sample points is just 12 to a power given by the number of S’s times 21 to a power given by the number of F ’s. Because the probability of success is the same as the probability of failure, the resulting product is always p3 (F F F ) = p3 (SF F ) = p(F SF ) = p(F F S) p3 (SSF ) = p(SF S) = p(F SS) = p3 (SSS) = 1 2 3 = 1 8 Thus the probability model we are searching for is # Success p(#) p(#) 0 1 ( 12 )0 ( 12 )3 1 8 1 3 ( 12 )0 ( 21 )3 3 8 2 3 ( 12 )0 ( 12 )3 3 8 3 1 ( 21 )0 ( 12 )3 1 8 Of course, the two threes in this come from the fact that both fSF F; F SF; F F Sg and fSSF; SF S; F SSg have three entries. By now some things are quite obvious. Whether we toss a die, ‡ip a coin, or do any Bernoulli trial, the sample space for n repeats will be the same. For n = 4; it will be fSSSS; SSSF; SSF S; SSF F; SF SS; SF SF; SF F S; SF F F F SSS; F SSF; F SF S; F SF F; F F SS; F F SF; F F F S; F F F F g: The outcomes of the four repeats of the trial will be assumed to be mathematically independent. We can compute the probabilities of these events by 10 counting the number of successes and failures. If the probability of success is p in one trial, then the probability of failure is (1 p). For a fair coin ‡ip, the are both 12 : In the case of 4 repeats, the events we are interested in are 0 1 2 3 4 Success Success Success Success Success = = = = = fF F F F g fSF F F; F SF F; F F SF; F F F Sg fSSF F; SF SF; SF F S; F F SS; F SF S; F SSF g fSSSF; SSF S; SF SS; F SSSg fSSSSg The probabilities of the sample points that make up each one of these events are all the same. and depend only on the number of success and failures. p4 (F F F F ) = p0 (1 p)4 p(SF F F ) = p(F SF F ) = p(F F SF ) = p(F F F S) = p1 (1 p)3 p(SSF F ) = p(SF SF ) = p(SF F S) = p(F F SS) = p(F SF S) = p(F SSF ) = p2 (1 p)2 p(SSSF ) = p(SSF S) = p(SF SS) = p(F SSS) = p3 (1 p)1 p(SSSS) = p4 (1 p)0 Thus the probability model of a fail coin toss, the probability model is # Success p4 (#) p4 (#) 0 1 ( 12 )0 ( 12 )4 1 16 1 4 ( 12 )1 ( 21 )3 1 4 2 6 ( 12 )2 ( 12 )2 3 8 3 4 ( 12 )3 ( 12 )1 1 4 4 1 ( 12 )4 ( 12 )0 1 16 If we move to n repeated tosses, we can predict the form of the result we will get # Success k = 0; 1; 2; 3 : : : n k pn (#) (1 p)n k n Pk (p) where n Pk is a natural number that counts the number of di¤erent ways k S’s and (n k) F ’s can be lined up. Of course, the p depends on the particular Bernoulli experiment we are using, but because the sample spaces depend only on lists of success or failure, the numbers n Pk are the same for any Bernoulli trial. Here are some charts that illustrate the probability models for various and the fair coin toss where p = 12 . 11 n=2 p=1/2 0.6 0.5 0.4 p 0.3 0.2 0.1 0 0 1 2 Successes n=3 p=1/2 0.4 0.35 0.3 0.25 p 0.2 0.15 0.1 0.05 0 0 1 2 3 Successes n=6 p=1/2 0.35 0.3 0.25 p 0.2 0.15 0.1 0.05 0 0 1 2 3 4 5 6 Successes n=10 p=1/2 0.3 0.25 0.2 p 0.15 0.1 0.05 0 0 1 2 3 4 5 Successes 12 6 7 8 9 10 n=20 p=1/2 0.2 0.18 0.16 0.14 0.12 p 0.1 0.08 0.06 0.04 0.02 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Successes Again as the number of repeats gets larger, the probabilities of the extremes get so small, it pays to leave them o¤ the chart. n=30 p=1/2 0.16 0.14 0.12 0.1 p 0.08 0.06 0.04 0.02 0 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Successes n=50 p=1/2 0.12 0.1 0.08 p 0.06 0.04 0.02 0 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 Successes Now all the scales in these charts are changing and they are di¤erent than the corresponding charts for the die toss. Still the growing similarities in these charts is striking. As the number of repeats of the Bernoulli Trial grows, the more the basic shape of the probabilities in the models look alike. In the die example, it took a couple of trials to get started, but by the time we get to 20 trials, the shape has begun to emerge. In the case of the coin ‡ip, the shape starts appearing quite early. In general, the closer the probability of success in the Bernoulli Trial is to 12 , the faster the shape begins to appear. The further away it is from 12 , the longer it take, but no matter how small, once the 13 number of repeats gets large enough, this shape will emerge in the chart of the probabilities. 1.3 Binomial Coe¢ cients The …nal remaining mystery are the numbers n Pk : Now, computing one of these numbers requires us to count the number of "words" you can make using only the letters S and F . In particular, n Pk give the number of n letter words that have exactly k of the letter S and (n k) of the letter F: Starting with n = 1; the sample space has only two one letter words fS; F g One of these has one S and the other has zero S’s. That means 1 P0 =1 1 P1 =1 For n = 2 there are four words in the sample space fSS; SF; F S; F F g Grouping them by the number of S’s gives ffSSg; fSF; F Sg; fF F gg So 2 P0 =1 2 P1 =2 2 P2 =1 For n = 3 there are four words in the sample space fSSS; SSF; SF S; SF F; F SS; F SF; F F S; F F F g Grouping them by the number of S’s gives ffSSSg; fSSF; SF S; F SSg; fF F S; F SF; SF F g; fF F F gg So 3 P0 =1 3 P1 =3 3 P2 =3 3 P3 =1 For For n = 4; it will be ffSSSSg; fSSSF; SSF S; SF SS; F SSSg; fSSF F; SF SF; SF F S; F F SS; F SF S; F SSF g fF SSS; F SF F; F F SF; F F F Sg; fF F F F gg: And that leads to 4 P0 =1 4 P1 =4 4 P2 =6 14 4 P3 =4 4 P4 = 1: This is all leading to one of the most famous arrays of numbers in mathematics, Pascal’s Triangle. This triangle looks like 1 P1 2 P1 3 P1 4 P1 5 P1 6 P1 2 P1 3 P1 4 P1 5 P1 1 P1 2 P1 3 P1 4 P1 5 P1 6 P1 6 P1 3 P1 4 P1 4 P1 5 P1 6 P1 5 P1 5 P1 6 P1 6 P1 6 P1 Each row stands for a number of trials n; the location in the row gives the number of S’s we are allowed starting with 0. When we …ll in the actual counts, an amazing pattern emerges 1 1 1 2 1 1 1 1 3 4 6 5 6 1 3 10 15 1 4 10 20 1 5 15 1 6 1 Every other row starts and ends with a 1. The …rst row gets its two 1’s, but we leave enough space below and between them to write their sum. That sum is exactly the number that belongs in the second row. From then on, all the interior numbers in each row can be computes by adding the two numbers in the previous row closest to them. In row 5, we see a 5 followed by a 10, in the space below and between them in row 6, we …nd their sum 15. This is the third number from the left in row six, thus n = 6; and (remembering to start counting the numbers in the row at zero) k = 2 6 P2 = 15: This pattern can be extended as long as you like. The numbers that appear are called The Binomial Coe¢ cients: There is an alternate notation, and even a formula for these numbers: n Pk = n k = n! k!(n k)! where (n n! = n (n 1) (n 2) 3 2 1 k! = k (k 1) (k 2) 3 2 1 k)! = (n k) (n k 1) (n k 2) 3 2 1. These number come up so often in mathematics that most scienti…c calculators have them built in. There may be a button or a command, but if a calculator does anything more than simple arithmetic, it usually also calculates the binomial coe¢ cients somehow. Prepared by: Daniel Madden and Alyssa Keri: May 2009 15