Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
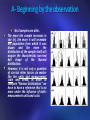
R ww & w. M rm So sol lut ut on ion s s.n et Ahmed Hassouna, MD Professor of cardiovascular surgery, Ain-Shams University, EGYPT. Diploma of medical statistics and clinical trial, Paris 6 university, Paris. 1A- Choose the best answer › The duration of CCU stay after acute MI: 48 + 12 hours. R ww & w. M rm So sol lut ut on ion s s.n et A) What is the “expected” probability for a patient to stay for <24 hours? › 1) about 2.5 % › 2) about 5% › 3) about 95% › B) What is the “expected” probability for a patient to stay for more than 72 hours? › 1) same as the probability to stay for less than 24 hours. › 2) triple the probability to stay for less than 24 hours. › 3) We cannot tell › C) What is the probability for a patient to stay for less than 24 hours and for more than 72 hours? › 1) about 2.5 % › 2) about 5% › 3) about 95% 2A- Choose the WRONG answer R ww & w. M rm So sol lut ut on ion s s.n et A randomized controlled unilateral study was conducted to compare the analgesic effect of drug (X) to placebo. The analgesic gave significantly longer duration of pain relief (12 + 2 hours), compared to placebo (2 + 1 hours) ; P = 0.05 (Student’s test, one-tail). 1) A unilateral study means that the researchers were only concerned to show the superiority of the analgesic over placebo, but not the reverse. 2) A one-tail statistics implies that a smaller difference between compared analgesic effects is needed to declare statistical significance, compared to a bilateral design. 3) The statistical significance of the difference achieved will not change if the design was bilateral. 3A- Choose the best answer › A) The primary risk of error: R ww & w. M rm So sol lut ut on ion s s.n et › 1) It is the risk “to conclude” upon a difference in the study that does not exist in the reality. › 2) It is the risk “not to conclude” upon a difference in the study despite that this difference does exist in the reality. › 3) Both definitions are wrong › B) The secondary risk of error: › 1) It is the risk “to conclude” upon a difference in the study that does not really exist. › 2) It is the risk “not to conclude” upon a difference in the study despite that this difference does exist in the reality. › 3) Bothe definitions are wrong › C) The power of the study: › 1) It is the ability of the study to accurately conclude upon a statistically significant difference. › 2) It is the ability of the study “not to miss” a statistically significant difference. 3) Both definitions are wrong 4A- Choose the best answer R ww & w. M rm So sol lut ut on ion s s.n et A randomized controlled unilateral study was conducted to compare the analgesic effect of drug (X) to placebo. The analgesic gave significantly longer duration of pain relief (12 + 2 hours), compared to placebo (2 + 1 hours) ; P = 0.05 (onetail). This P value means that: 1) There is a 95% chance that this result is true 2) There is a 5% chance that this result is false. 3) The probability that this result is due to chance is once, every 20 times this study is repeated. 4) The probability that this longer duration of pain relief is “not a true difference in favor of the analgesic but rather a variation of that obtained with placebo” is once, every 20 times this study is repeated. 5A- Choose the best answer: R ww & w. M rm So sol lut ut on ion s s.n et Although the previous study was a RCT, the researchers wanted to compare 40 pre trial demographic variables among study groups. How many times do you expect that those pre trial variables would be significantly different between patients receiving analgesic and those receiving placebo? a) None, as comparability. randomization ensures perfect initial b) It can happen to have 1 significantly different variable by pure chance. c) It would be quite expected to have 2 significantly different variables. d) We cannot expect any given number. 6A- Choose the best answer: R ww & w. M rm So sol lut ut on ion s s.n et Another group of researchers has repeated the same study and found a statistically more significant difference in favor of analgesic; P value < 0.001. In view of the smaller P value, and provided that both studies were appropriately designed, conducted and analyzed, choose the BEST answer: a) The results of the second study have to be more considered than the first for being “truer”. b) The results of the second study have to be more considered than the first for being more accurate. c) The results of the second study have to be more considered than the first for being more credible. d) Both studies have to have an equal consideration, for being both statistically significant R ww & w. M rm So sol lut ut on ion s s.n et The relative Z values (scores) R ww & w. M rm So sol lut ut on ion s s.n et One of the empirically verified truths about life: it is a finding and not an invention. It is a name given to a characteristic distribution which followed by the majority of biological variables and, not a quality of such distribution. Birth weight classes (gm.) (a) Centers (b) Range* 2100 2300 2500 2700 2900 3100 3300 3500 3700 3900 4100 4300 4500 2000-2200 2200-2400 2400-2600 2600-2800 2800-3000 3000-3200 3200-3400 3400-3600 3600-3800 3800-4000 4000-4200 4200-4400 4400-4600 Total Birth weight frequency Absolute Relative (%) (number) 2 2.1 4 4.2 6 6.3 4 4.2 10 10.5 18 18.9 21 22.1 17 17.9 5 5.3 4 4.2 3 3.2 0 0 1 1.1 95 100 Total weight (gm.) 4200 9200 15000 10800 29000 55800 69300 59500 18500 15600 12300 0 4500 303700 R ww & w. M rm So sol lut ut on ion s s.n et 1 SD 2 SD m 3 SD Birth weight classes (gm.) (a) Centers (b) Range* 2000-2200 2200-2400 2400-2600 2600-2800 2800-3000 3000-3200 3200-3400 3400-3600 3600-3800 3800-4000 4000-4200 4200-4400 4400-4600 Total Total weight (gm.) 4200 9200 15000 10800 29000 55800 69300 59500 18500 15600 12300 0 4500 303700 R ww & w. M rm So sol lut ut on ion s s.n et 2100 2300 2500 2700 2900 3100 3300 3500 3700 3900 4100 4300 4500 Birth weight frequency Absolute Relative (%) (number) 2 2.1 4 4.2 6 6.3 4 4.2 10 10.5 18 18.9 21 22.1 17 17.9 5 5.3 4 4.2 3 3.2 0 0 1 1.1 95 100 (66 births; 69.5%) (92 births; 96.8%) The mean birth weight m = 3200 gm. and the SD = 450 gm. Let us check for the Normality of the distribution: 2/3 of birth weights are included in the interval: m + 1SD: 2750-3650 gm. 95% of birth weights are included in the interval: m + 2SD: 2300-4100 gm. Nearly all birth weights are comprised within a distance of + 3 SD from the mean A- Beginning by the observation R ww & w. M rm So sol lut ut on ion s s.n et No 2 samples are alike. The more the sample increases in size (n), the more it will resemble the population from which it was drawn and the more the distribution of the sample itself will acquire the characteristic inverted bell shape of the Normal distribution. However, it is not only a question of size but other factors do matter like the units and measurement scale and hence, in order to compare “Normal distributions” we have to have a reference that is no more under the influence of both: measurement units and scale. B- Reaching a suggestion R ww & w. M rm So sol lut ut on ion s s.n et Statisticians have suggested a “Standard Normal distribution” with a mean of 0 and a SD of 1; which means that the SD becomes the unit of measurement: moving 1 unit on this scale (from “0” to “1”) will also mean that we went 1 SD further away from the mean and so on. Those units have to have a name and were called Z units (scores, values). Statisticians have then calculated the probabilities for observations to lay at all possible Z units and put it in the Z table. The rough (size, unit and scaledependent) estimation of probabilities that differ from one Normal distribution to another, were now replaced by exact (standard) figures. As example, “exactly” 68.26%, 95% and 99% of observations were found to lay WITHIN A DISTANCE of 1, 1.96 and 2.6 SD from either sides of the mean. -1.96 SD 47.5% 2.5% +1.96 SD 47.5% 2.5% The probability for a value to lie AT (OR FURTHER AWAY) from +1.96 SD is obtained by simple deduction: 100 – 95% = 5%; 2.5% on each side. C- Ending with the application: Standardizing values (the wire technique) R ww & w. M rm So sol lut ut on ion s s.n et Any “OBSERVED” Normal distribution is “EXPECTED” to follow the Standard Normal distribution and the more it deviates from those expectations, the more it will be considered as being “different” and the question that we are here to answer is about the “extent” and consequently the “statistical significance” of such a difference or deviation. <2300 gm. >4100 gm. >2300-4100< In fact, the “unknown” probabilities of our observed (x) values can now be “calculated” when 47.5% 47.5% the latter are transformed into standardized Z values; with already known tabulated probabilities: 2.5% 2.5% Z = (x-m)/SD Returning to our example: what is the “expected” probability of having a child whose birth weight is as large as > 41000 gm.? We begin by standardizing the child’s weight: How to consult the Z table? Z = (4100-3200) / 450 = +1.96 The probability of having a child whose Then we check the table for the probability of having a Z score of +1.96; which is simply equal to birth weight lay in the interval formed the probability of having such a low birth weight by the mean + 1.96 SD = 3200 + 450 = child of 2300 gm. or less. >2300 and 4100< is 95%. The (Z) table gives the probability for a value to be smaller than Z; in the interval between 0 and Z. 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3.0 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.0000 0.0398 0.0793 0.1179 0.1554 0.1915 0.2257 0.2580 0.2881 0.3159 0.3413 0.3643 0.3849 0.4032 0.4192 0.4332 0.4452 0.4554 0.4641 0.4713 0.4772 0.4821 0.4861 0.4893 0.4918 0.4938 0.4953 0.4965 0.4974 0.4981 0.4987 0.0040 0.0438 0.0832 0.1217 0.1591 0.1950 0.2291 0.2611 0.2910 0.3186 0.3438 0.3665 0.3869 0.4049 0.4207 0.4345 0.4463 0.4564 0.4649 0.4719 0.4778 0.4826 0.4864 0.4896 0.4920 0.4940 0.4955 0.4966 0.4975 0.4982 0.4987 0.0080 0.0478 0.0871 0.1255 0.1628 0.1985 0.2324 0.2642 0.2939 0.3212 0.3461 0.3686 0.3888 0.4066 0.4222 0.4357 0.4474 0.4573 0.4656 0.4726 0.4783 0.4830 0.4868 0.4898 0.4922 0.4941 0.4956 0.4967 0.4976 0.4982 0.4987 0.0120 0.0517 0.0910 0.1293 0.1664 0.2019 0.2357 0.2673 0.2967 0.3238 0.3485 0.3708 0.3907 0.4082 0.4236 0.4370 0.4484 0.4582 0.4664 0.4732 0.4788 0.4834 0.4871 0.4901 0.4925 0.4943 0.4957 0.4968 0.4977 0.4983 0.4988 0.0160 0.0557 0.0948 0.1331 0.1700 0.2054 0.2389 0.2704 0.2995 0.3264 0.3508 0.3729 0.3925 0.4099 0.4251 0.4382 0.4495 0.4591 0.4671 0.4738 0.4793 0.4838 0.4875 0.4904 0.4927 0.4945 0.4959 0.4969 0.4977 0.4984 0.4988 0.0199 0.0596 0.0987 0.1368 0.1736 0.2088 0.2422 0.2734 0.3023 0.3289 0.3531 0.3749 0.3944 0.4115 0.4265 0.4394 0.4505 0.4599 0.4678 0.4744 0.4798 0.4842 0.4878 0.4906 0.4929 0.4946 0.4960 0.4970 0.4978 0.4984 0.4989 0.0239 0.0636 0.1026 0.1406 0.1772 0.2123 0.2454 0.2764 0.3051 0.3315 0.3554 0.3770 0.3962 0.4131 0.4279 0.4406 0.4515 0.4608 0.4686 0.4750 0.4803 0.4846 0.4881 0.4909 0.4931 0.4948 0.4961 0.4971 0.4979 0.4985 0.4989 0.0279 0.0675 0.1064 0.1443 0.1808 0.2157 0.2486 0.2794 0.3078 0.3340 0.3577 0.3790 0.3980 0.4147 0.4292 0.4418 0.4525 0.4616 0.4693 0.4756 0.4808 0.4850 0.4884 0.4911 0.4932 0.4949 0.4962 0.4972 0.4979 0.4985 0.4989 0.0319 0.0714 0.1103 0.1480 0.1844 0.2190 0.2517 0.2823 0.3106 0.3365 0.3599 0.3810 0.3997 0.4162 0.4306 0.4429 0.4535 0.4625 0.4699 0.4761 0.4812 0.4854 0.4887 0.4913 0.4934 0.4951 0.4963 0.4973 0.4980 0.4986 0.4990 0.0359 0.0753 0.1141 0.1517 0.1879 0.2224 0.2549 0.2852 0.3133 0.3389 0.3621 0.3830 0.4015 0.4177 0.4319 0.4441 0.4545 0.4633 0.4706 0.4767 0.4817 0.4857 0.4890 0.4916 0.4936 0.4952 0.4964 0.4974 0.4981 0.4986 0.4990 R ww & w. M rm So sol lut ut on ion s s.n et Z value The Z scores are directly proportional of observed deviation R ww & w. M rm So sol lut ut on ion s s.n et The larger (or smaller) is a value as compared to the mean, the more distinct is its position on the standard scale: i.e. the larger is the Z value Z= (x-m)/SD = (3650-3200) /450 = 1, = (4100-3200) /450 = 1.96, Put it another way, the larger is the Z value (+/-), the less is its chance to belong to this particular distribution. Q1: What is the probability of having a child who is as heavy as 5 kg? Z = (5000-3200) /450 = 4 Q2: If this probability is minimal, (not even listed) what can you suggest? May be this child does not belong to the same population from which we have drawn our sample? Is his mother diabetic?; i.e. we can now suggest a qualitative decision based on such an extreme deviation. 3650gm. 4100 gm. 3200 gm. 5000gm. The duration of CCU stay after acute MI: 48 + 12 hours. R ww & w. M rm So sol lut ut on ion s s.n et The “expected” probability for a patient to stay for <24 hours, for more than 72 hours or for both less than 24 hours and more than 72 hours? Z = (24-48)/ 12 = (72-48)12 = 2. Depending on the question posed: A) The probability of having either a larger (+) or smaller (-) Z value of 2 is calculated by adding 50% to the probability given by the table (47.5%) and subtracting the whole from 1 = 1- (47.5% + 50%) = 2.5% . B) The probability of having both larger and smaller Z values (i.e. staying for >72 hours and staying for <24 hours) is calculated by multiplying the probability given in the table by 2 and subtracting the whole from 1= 1-(47.5%x2) = 5%. 24 48 36 72 60 2.2.5% 47.5% 50% 1B- Choose the best answer › The duration of CCU stay after acute MI: 48 + 12 hours. A) What is the “expected” probability for a patient to stay for <24 hours? 1) about 2.5 % › 2) about 5% › 3) about 95% › Z = (x-m)/SD= (24-48)/12 = -2; probability = 1-(47.5+50)= nearly 2.5% › B) What is the “expected” probability for a patient to stay for more than 72 hours? › 1) same as the probability to stay for less than 24 hours. › 2) triple the probability to stay for less than 24 hours. › 3) We cannot tell › Z = (x-m)/SD= (72-48)/12 = +2; probability = 1-(47.5+50)= nearly 2.5% › C) What is the probability for a patient to stay for less than 24 hours and for more than 72 hours? › 1) about 2.5 % › 2) about 5% › 3) about 95% › Summing both previous probabilities = 1- (47.5x2) = 5% R ww & w. M rm So sol lut ut on ion s s.n et › The Normal law: conditions of application R ww & w. M rm So sol lut ut on ion s s.n et The Normal law is followed by the majority of biological variables and Normality can be easily checked out by various methods, starting from simple graphs to special tests. As a general rule, quantitative variables are expected to follow the Normal law whenever the number of values per group >30. For a binominal (p,q) qualitative variable with (N) total number of values (N), Normality can be assumed whenever Np, Nq >5. The presence of Normality allows the application of many statistical tests for the analysis of data. These are called “parametric tests” for necessitating fulfillment of some parameters before being used, including Normality. Non-parametric (distribution-free) tests are equally effective for data analysis and hence, one should not distort data to achieve Normality. R ww & w. M rm So sol lut ut on ion s s.n et The null hypothesis The statistical problem R ww & w. M rm So sol lut ut on ion s s.n et A sample must be representative of the aimed population. One of the criticisms of RCT is that they are too ordered to be a good reflection of the disordered reality. Even if the requirements of representativeness are “thought to be” fulfilled by randomization, a question will always remain: how much likely does our sample really represent the aimed population? As example, when a comparative study shows that treatment A is 80% effective in comparison to treatment B which is only 50% effective; a legitimate question would be if the observed difference is really due to effect treatment and not because patients who received treatment A were for example “less ill” than those receiving treatment B? In other words, were both groups of patients comparable from the start by being selected from “the same” or from “different populations” with different degrees of illness? Postulating the Null hypothesis R ww & w. M rm So sol lut ut on ion s s.n et In order to answer this question, statisticians have postulated a theoretical hypothesis to start with: The null hypothesis We start any study by the null hypothesis postulating that there is no difference between the compared treatments. Then we conduct our study and analyze the results; which can either retain or disprove this “theory” by showing that treatments are truly different. At this point, we can reject the null hypothesis and accept the alternative hypothesis that there is a true difference between treatments; which has just been proved : The alternative hypothesis Both hypotheses: the first suggested to begin with and the second that may be proved by the end of the study are the 2 faces of one coin and hence, cannot co-exist. When to reject the null hypothesis? R ww & w. M rm So sol lut ut on ion s s.n et Returning to our example of the 95 newly born babies, and under the null hypothesis, all children have comparable weights and the recorded differences are just variations of comparable weights belonging to the “same population” Differences are expressed in Z scores and the higher is the Z score, the less probable it can be consider as being just a variation of this particular distribution. The probability of having such an extreme variation of a 5 Kg-child (=Z=4) is minimal and hence, can raise questions about the null hypothesis: being member of the same population. In general, if the observed difference is sufficiently large and hence, less probable to be considered as part of the variation, we can consider rejecting the null hypothesis, accepting the alternative hypothesis and concluding upon the existence of a true difference. 3650gm. 4100 gm. 5000gm. 3200 gm. 15% 2.5% <0.0001 When to maintain the null hypothesis? R ww & w. M rm So sol lut ut on ion s s.n et On the other hand, if the difference is (small), we will continue to maintain our theoretical null hypothesis. However, in such a case, we cannot conclude that the observed difference does not exist because the null hypothesis itself is only a hypothetical suggestion. In fact, the aim of the study was to find sufficient evidence supporting the alternative hypothesis. In absence of sufficient evidence, we will maintain the theoretical null hypothesis that was neither rejected nor proved, but has only been maintained for further studies. The usual closing remark, and not a conclusion, is that we could not put into evidence the targeted difference and further studies may be needed to reevaluate the evidence to support this difference (i.e. to support the alternative hypothesis). Under the null hypothesis (Large difference) (Small difference) Reject null hypothesis & accept alternative hypothesis Maintain the null hypothesis Conclude to a difference. X We have to define a critical limit for rejection R ww & w. M rm So sol lut ut on ion s s.n et We can reject the null hypothesis when the analysis shows a “sufficiently large difference that has a SMALL PROBABILITY of being just “a variation” of the same population. Consequently, it can be considered as being a “true difference”; which is coming from a different population. A literal description that merits a numerical expression. Most of the researchers have agreed that the null hypothesis can be rejected whenever the probability of being a variation is as small as 5%. This probability is called primary risk of error?! It means that although we know that there is a small 5% probability that this difference is just an extreme variation of the population, yet we declared it as being coming from a different population. In other words, our conclusion carries a small risk of being wrong and that this difference is still a variation of the first population, even if it is an extreme one. R ww & w. M rm So sol lut ut on ion s s.n et Primary risk of error (α) >2300 <4100 We maintain the null hypothesis The majority of birth weights (95%) are expected to be between 23004100 gm. and, by deduction, only 5% of babies are expected to lie outside this range. The probability of having a baby weighting >4100 gm. (or <2300 gm.) is as small as 5% and hence, this baby can be considered as being born from another population e.g. from a diabetic mother This conclusion still carries the small 5 % risk of being wrong ; i.e. that the weight of this baby is just an extreme variation of non-diabetic mothers. This small, but still present, risk of being wrong (risk of rejecting the null hypothesis where as the null hypothesis is true) is the primary risk of error. Distribution of the primary risk of error: the unilateral versus the bilateral design R ww & w. M rm So sol lut ut on ion s s.n et A) Whenever we are comparing a treatment to placebo, our only concern is to prove that treatment is better than placebo & never the reverse. Null hypothesis (H0): no difference + Placebo is better Alternative hypothesis (H1): treatment is better than placebo. The primary risk of error of the study (5%) is involved in a single conclusion: treatment is better than placebo, while this is untrue. B) On the other hand, a bilateral design involves testing the superiority of either treatments: A or B. H0: no difference between treatments A and B. H1: involves 2 situations 1) treatment A is better than treatment B 2) treatment B is better than treatment A In order to keep a primary risk of error of 5% for the whole study, (α) which is the risk to conclude upon a difference that does not exist; is equally split between the 2 possibilities: treatment A is better, while this is untrue (2.5%) and treatment B is better than treatment A , while this is untrue(2.5%). An example (even if it is not the perfect one!) R ww & w. M rm So sol lut ut on ion s s.n et The null hypothesis is rejected whenever the difference (d) is large enough that the probability of being a normal variation is as small as 5%. Returning to the 95 new born babies and suppose that we want know if a newly coming baby does belong to a diabetic mother and hence, we are only interested to prove that he is significantly larger than the rest of the group. This is a unilateral design, H0= no difference in weights + baby weight is significantly smaller. H1 = the baby is significantly larger than the others and, the whole of “α” is dedicated to this single and only investigated possibility. On the other hand, and if the design was bilateral, we would be interested to know if the weight of the baby is significantly different (whether larger or smaller) from the others; this is the alternative hypothesis and “α” is no more dedicated to 1 possibility but it is equally split (50:50) between the 2 possibilities; each being “α/2”. The null hypothesis is that the baby weight is comparable to the rest of the group. R ww & w. M rm So sol lut ut on ion s s.n et The null hypothesis will be rejected whenever the calculated Z score enters the critical area of our primary risk of error. In a unilateral study, we are only concerned if the difference is in favor of 1 treatment and hence, the whole 5% of “α “ is on 1 side or one tail of the curve. In a bilateral design, the risk of error is equally split into 2 smaller risks of 2.5% each. In consequence, the limit of the larger (5%) critical area of rejection of the unilateral study is nearer to the mean than any of the 2 smaller (2.5%) areas of the bilateral design. In consequence, a smaller Z score (difference) is needed to enter the critical area of rejecting the null hypothesis and declaring statistical significance in a unilateral study; compared to a bilateral design. R ww & w. M rm So sol lut ut on ion s s.n et In a unilateral design: the null hypothesis will be rejected whenever the calculated Z score enters the critical area of α 3950gm. 5% 3200 2.5% 3200 2.5% 1.65 In a unilateral study, we are only concerned if the child is significantly larger than the rest of the group and hence, the whole 5% of “α “ is on 1 side (one tail) of the curve. The child weight would be considered as being significantly larger if its corresponding Z score reaches the “limit of α”. Consulting the Z table, the Z value of point “α=5%“ = 1.65 and by deduction (Z = x- m/SD; x = Z x SD + m = 1.65x450 + 3200 = 3950); a child weighting only 3950 gm. would be considered as being significantly larger than the rest of the population; with a primary risk of error of 5%. In a unilateral design, the critical limit to reject the null hypothesis is Z > 1.65 R ww & w. M rm So sol lut ut on ion s s.n et In a bilateral design: the null hypothesis will be rejected whenever the calculated Z score enters the critical area of α/2 3950 4100 3950 3200 5% 2.5% 3200 2.5% In a Bilateral study, we are equally concerned if the child is significantly larger or smaller than the rest of the group and hence, the 5% of “α “ will be equally split between both tails of the curve (50:50). In comparison, a child weight would be considered as being significantly larger if its corresponding Z score reaches the “limit of α/2”; which by default has to be further away from the mean compared to whole α in a unilateral design In consequence, a larger Z (difference) is needed to touch a now more distal critical limit. The Z table, shows a larger Z (1.96) for the smaller α/2, of course. In consequence, a child has to be as large as 4100 gm. to be declared as being significantly different from the population, compared to only 3950 gm., in the case if the design was unilateral. In a bilateral design, the critical limit to reject the null hypothesis is a Z > 1.96 2B- Choose the WRONG answer R ww & w. M rm So sol lut ut on ion s s.n et A randomized controlled unilateral study was conducted to compare the analgesic effect of drug (X) to placebo. The analgesic gave significantly longer duration of pain relief (12 + 2 hours), compared to placebo (2 + 1 hours) ; P = 0.05 (Student’s test, one-tail). 1) A unilateral study means that the researchers were only concerned to show the superiority of the analgesic over placebo, but not the reverse. 2) A one-tail statistics implies that a smaller difference between compared analgesic effects is needed to declare statistical significance, compared to a bilateral design. 3) The statistical significance of the difference achieved will not change if the design was bilateral. Testing hypothesis: the comparison of 2 means R ww & w. M rm So sol lut ut on ion s s.n et A standard feeding additive (A) is known to increase the weight of low birth weight babies by a mean value of 170g and a SD of 65g. A new feeding additive (B) is given to a sample of 32 low birth weight babies and the mean weight gain observed was 203g and a SD of 67.4 g. The question now is if additive (B) has provided significantly more weight gain to those babies, compared to the standard additive (A) ? The null hypothesis Ho: The mean weight gain obtained by the new additive (B) is just a normal variation of the weight gain obtained by additive (A). The alternative hypothesis H1: the difference between the mean weight gain obtained by (A) and that obtained by (B) are sufficiently is sufficiently large to reject the null hypothesis, at the primary risk of error of 5%. R ww & w. M rm So sol lut ut on ion s s.n et Testing hypothesis: the equation Maintain H0 2.87 Sample mean (203 gm.) The secondary risk of error (β) R ww & w. M rm So sol lut ut on ion s s.n et Suppose that we repeat the study and we obtained the same weight gain difference but with only 5 newborns. With such a small sample. we have to expect a larger SEM and hence, a smaller z value. z value = (203-170) / (65/√5) = 1.645 Being below the critical value of even a unilateral design, this second researcher will be obliged to retain the null hypothesis, despite the fact that a “true difference” was shown by the first researcher. This example demonstrates the secondary risk of error: the risk of not concluding upon a difference in the study despite that such a difference exists (or can exist) in the reality. The secondary risk of error (risk of secondary species or (β) or type II error) is usually behind the so called “negative trials”. Most importantly, and unlike the first researcher, our second researcher "cannot conclude“ and his usual statement will be: “we could not put into evidence a significant difference between A and B; that is probably due to the lack of power” . 3B- Choose the best answer › A) The primary risk of error: R ww & w. M rm So sol lut ut on ion s s.n et › 1) It is the risk “to conclude” upon a difference in the study that does not exist in the reality. › 2) It is the risk “not to conclude” upon a difference in the study despite that this difference does exist in the reality. › 3) Both definitions are wrong › B) The secondary risk of error: › 1) It is the risk “to conclude” upon a difference in the study that does not really exist. › 2) It is the risk “not to conclude” upon a difference in the study despite that this difference does exist in the reality. › 3) Bothe definitions are wrong › C) The power of the study: › 1) It is the ability of the study to accurately conclude upon a statistically significant difference. › 2) It is the ability of the study “not to miss” a statistically significant difference. 3) Both definitions are wrong R ww & w. M rm So sol lut ut on ion s s.n et Statistical significance & degree of significance P value R ww & w. M rm So sol lut ut on ion s s.n et First, and before conducting any research, we have to designate the acceptable limit of (α), which is usually 5%. This is the limit that if reached, we can consider that the tested treatment is not just a variation of the classic one but a truly superior treatment. Concordantly, in the example of food additives, a new additive will be considered superior when the associated weight gain > 193 gm. Secondly, the researcher conducts his study and analyze his results using the appropriate statistical test now to calculate this probability for the new additive to be just a variation of the classic additive; this calculated probability is the P value. If the P value is at least equal or smaller than the designated (α), we can reject the null hypothesis and accept the alternative hypothesis. On the other hand, if this calculated probability is larger than (α), we maintain the null hypothesis and the test results are termed as being statistically insignificant. α 2.87 P Relation between α and P R ww & w. M rm So sol lut ut on ion s s.n et In other words, we have 2 probabilities: one that we pre design before the experiment and another one that we calculate (using the appropriate statistical test) at the end of the experiment. The pre designed probability indicates the limit for rejecting the null hypothesis that we fix before the experiment. The calculated probability indicates the position of our results in relation to this limit, after the experiment. The null hypothesis will only be rejected If the calculated probability is at least equal or smaller than the pre designed limit; otherwise, it will be maintained. The pre designed probability is called the primary risk of error or (α) and the calculated probability is the well-known P value. What is the P value ? R ww & w. M rm So sol lut ut on ion s s.n et Unlike a common belief, the P value is not the probability for the null hypothesis to be untrue because the P value is calculated on the assumption that the null hypothesis is true. It cannot, therefore, be a direct measure of the probability that the null hypothesis is false. A proper definition of P is the probability of obtaining the observed or more extreme results, under the null hypothesis (i.e. while the null hypothesis is still true). The value of P is an index of the reliability of our results. In terms of percentage, the smaller is the P value, the higher it is in terms of significance; i.e. the more we can believe that the observed relation between variables in the sample is a reliable indicator of the relation between the respective variables in the population. Comments on the P value R ww & w. M rm So sol lut ut on ion s s.n et Another common error is to understand that a P value of 0.04 means that our risk of error will be 4%, each time we repeat the experiment. A P value of 0.04 means that if we will repeat this study 100 times, in 4 times of which we can still have a result that is at least equal (or larger) than the one we had; always under the null hypothesis. In other words, the result in those 4 times will not be due to a true difference in compared treatments, groups, etc… but are to be considered as extreme variations under a still valid null hypothesis. Every time a test is executed, there is a 5% (1/20) probability that our results are just “a fluke” and hence, repeated measurement of P value on the same data is a common source of bias for inflating P. In order to maintain a to “constant” P value of 5%, the resulting P* can be multiplied by the number of comparisons made (c). P = P*x c Statistical significance R ww & w. M rm So sol lut ut on ion s s.n et The P value of 0.05 is customarily treated as a “border-line acceptable” error level and the usual statement is that: A P value < 0.05 is considered as being statistically significant. This statement signifies that the authors have chosen a primary risk of error (α) of 5% and hence, they will declare statistical significance whenever their calculated P value will reach this “critical’” level. Results that are significant from the P = 0.01 to the P =0.001 levels are often called “highly” significant however, this classification represents nothing else but arbitrary conventions. R ww & w. M rm So sol lut ut on ion s s.n et Degree of significance Another question: our study yielded 0.1% significance, not just the desired 5%; so what does this 0.1% mean ? The answer: our result is statistically significant because we have already reached the predesigned 5% limit of “α”. The 0.1% is the degree of significance; which means that “the probability of our conclusion upon a difference in the study that does not exist in the reality” is only 0.1% or less; which gives our conclusion a stronger credibility. No one should jump to the conclusion that his results are much more significant because his degree of significance was higher (smaller P value) than others. Those results should be considered as being “more credible” but never as being “truer”. In fact, degrees of significant should never be compared, whether in the same study or to other studies and doing so only means that we did not understand what does a P value mean. 4B- Choose the best answer R ww & w. M rm So sol lut ut on ion s s.n et A randomized controlled unilateral study was conducted to compare the analgesic effect of drug (X) to placebo. The analgesic gave significantly longer duration of pain relief (12 + 2 hours), compared to placebo (2 + 1 hours) ; P = 0.05 (onetail). This P value means that: 1) There is a 95% chance that this result is true 2) There is a 5% chance that this result is false. 3) The probability that this result is due to chance is once, every 20 times this study is repeated. 4) The probability that this longer duration of pain relief is “not a true difference in favor of the analgesic but rather a variation of that obtained with placebo” is once, every 20 times this study is repeated. 5B- Choose the best answer: R ww & w. M rm So sol lut ut on ion s s.n et Although the previous study was a RCT, the researchers wanted to compare 40 pre trial demographic variables among study groups. How many times do you expect that those pre trial variables would be significantly different between patients receiving analgesic and those receiving placebo? a) None, as comparability. randomization ensures perfect initial b) It can happen to have 1 significantly different variable by pure chance. c) It would be quite expected to have 2 significantly different variables. d) We cannot expect any given number. 6B- Choose the best answer: R ww & w. M rm So sol lut ut on ion s s.n et Another group of researchers has repeated the same study and found a statistically more significant difference in favor of analgesic; P value < 0.001. In view of the smaller P value, and provided that both studies were appropriately designed, conducted and analyzed, choose the BEST answer: a) The results of the second study have to be more considered than the first for being “truer”. b) The results of the second study have to be more considered than the first for being more accurate. c) The results of the second study have to be more considered than the first for being more credible. d) Both studies have to have an equal consideration, for being both statistically significant. Guess the best test to compare: › Age groups: › 2) ANOVA R ww & w. M rm So sol lut ut on ion s s.n et › 1) Student’s test. Comparison of 2 anti thrombolytic drugs A and B. › Durations of hospital stay: › 1) Unpaired Student’s test. › 2) Non-parametric Mann & Whitney › Sex distribution: › 1) Chi-Square test › 2) Fisher’s exact test. › Success rates: › 1) Chi-Square test › 2) Unpaired Student’s test. variable Group A N= 20 Group B N=20 Age (years) 50 + 5 55 + 7 Female sex 3 1 Success rate 10 5 Hospital stay d. 2 + 0.5 3.1 + 4 N= number of patients. Values are presented as numbers or mean + SD R ww & w. M rm So sol lut ut on ion s s.n et Ahmed Hassouna, MD Professor of cardiovascular surgery, Ain-Shams University, EGYPT. Diploma of medical statistics and clinical trial, Paris 6 university, Paris. Guess the best test to compare: › Age groups: › 2) ANOVA R ww & w. M rm So sol lut ut on ion s s.n et › 1) Student’s test. Comparison of 2 anti thrombolytic drugs A and B. › Durations of hospital stay: › 1) Unpaired Student’s test. › 2) Non-parametric Mann & Whitney › Sex distribution: › 1) Chi-Square test › 2) Fisher’s exact test. › Success rates: › 1) Chi-Square test › 2) Unpaired Student’s test. variable Group A N= 20 Group B N=20 Age (years) 50 + 5 55 + 7 Female sex 3 1 Success rate 10 5 Hospital stay d. 2 + 0.5 3.1 + 4 N= number of patients. Values are presented as numbers or mean + SD R ww & w. M rm So sol lut ut on ion s s.n et Bivariate analysis studies the relation between 2 variables while assuming that other factors (other associated variables) would remain stationary and hence, their possible role is neither considered nor evaluated. As an example, using bivariate analysis to compare the effects of 2 antihypertensive drugs has to assume that other factors playing a possible role in hypertension (e.g. weight gain, age, sex, salt intake, etc..) are stationary or equally distributed between the studied groups and hence, their effect could be neglected from the analysis without compromising the result of the comparison. R ww & w. M rm So sol lut ut on ion s s.n et Table 3.1: Binary outcome in 2 independent groups Nurses Doctors Total Hypertensive 20 30 40 30 60 Normotensive 80 70 60 70 140 Total 100 100 200 R ww & w. M rm So sol lut ut on ion s s.n et There is a statistically significant association between profession and being hypertensive; doctors are more likely to be hypertensive, compared to nurses; P<0.01 R ww & w. M rm So sol lut ut on ion s s.n et R ww & w. M rm So sol lut ut on ion s s.n et The Student-Fisher’s observations A random “t variable” has more chance of being further away from the mean than a “Normal” variable Unlike the Z score, the t-value is dependent upon the size of the studied sample; i.e. df = N -2 R ww & w. M rm So sol lut ut on ion s s.n et 5% t = mA-mB/√ (S2/nA + S2/nb). By default, is Student’s test unilateral or bilateral? R ww & w. M rm So sol lut ut on ion s s.n et Conditions of application: 1) Normal distribution of variable (test or graph) and, 2) “equality” of variances of the 2 compared groups . The test is robust however, a minimum of 20 patients in each group, seems to be an appropriate sample size. R ww & w. M rm So sol lut ut on ion s s.n et Variability is not one block: a person is being overweight not just because he is quite tall, but also for many other factors that include: daily caloric intake, physical activity, health condition, etc… As evident from its name, the role of ANOVA is to analyze variability by partitioning it into its different sources or components (e.g. height, daily caloric intake, physical activity, etc...) The part of variability that is under investigation (e.g. due to height) is then related to the remaining part of variability due to the other components (physical activity, health condition, etc…) as a ratio; known as “F” ratio. The former part of variability is known as the part explained by height or “effect variance”; for being due to the effect of height. The remaining part of variability is known as the “residual variance” for being still unexplained. H0= effect variance/residual variance = F=1; the more “effect variance” significantly explains variability, the more F is larger then 1. The statistical significance of calculated “F” is checked out in the appropriate Fisher’s table at the corresponding df, as usual. Example: One-Way ANOVA Duration of sleeping hours in 2 independent groups of patents A and B. R ww & w. M rm So sol lut ut on ion s s.n et • Although the mean sleeping hours are quite different (2, 6), yet the variability within each group is equal (2, 2); e.g. SS in group A = (1-2) 2+(3-2) 2+(22) 2=2 and the total within-groups variability = 2+2=4. • Considering both groups as one sample, with a mean of 4, the total variability of both groups is quite large =28. • Subtracting the within-group from the total variability gives the in-between group variability =4-28 = 24. The large amount of variation inbetween groups, in comparison to the small withingroups variance (residual variance) is due to the large difference between means; i.e. reflecting the effect of hypnotics. Hypnotic A Hypnotic B Patient 1 2 6 Patient 2 3 7 Patient 3 1 5 Mean 2 6 (SS) within each group 2 2 (SS) within groups 4 Overall mean 4 Total SS 28 One-way ANOVA table: as presented by SPSS SS df Variance =SS/df F 24 P value R ww & w. M rm So sol lut ut on ion s s.n et Source of variability 1- Between groups (Effect) 24 1 24 2- Within groups (residual) 4 4 1 3- Total 28 5 0.008 o As shown, most of the variability in sleeping hours is explained by the effect of hypnotics (SS=24) and only a small partition remained unexplained; i.e. residual variance (SS=4). o The introduction of more sources of variability in the model (e.g. number of working hours) can explain more partitions; the significance of each is tested through calculating the corresponding F ratio. This is the way by which one-Way ANOVA is turned into multiple ANOVA or MANOVA. R ww & w. M rm So sol lut ut on ion s s.n et R ww & w. M rm So sol lut ut on ion s s.n et Both correlation and regression express the relation between 2 quantitative variables: A) Correlation measures their association, without pointing to any causeeffect relationship. The simple correlation coefficient of Pearson “r” measures the strength of this association and hence, it varies between -1 to +1. The higher is “r”, the more significant is this “association”. In case of small sample size. In case of small sample size, Spearman’s correlation of ranks is the non-parametric equivalent. B) On the other hand, regression measures the effect of 1 (or more) independent variables on a 1 (or more) outcome variables. ANOVA is used to analyze the variation of outcome variable into partitions made by “the effect” of independent variables by an F ratio (or a series of F ratios) that relates the effect of independent variance to the residual variance, as just shown. 90 R ww & w. M rm So sol lut ut on ion s s.n et kg 100 Po 80 The null hypothesis 70 60 150 160 170 180 190 cm r = Po/√Var Po R ww & w. M rm So sol lut ut on ion s s.n et + R ww & w. M rm So sol lut ut on ion s s.n et R= coefficient of simple correlation “r” = standardized coefficient Beta. As you notice, the test did not calculate any statistical significance of “r”. 2) Unstandardized coefficient beta is the regression coefficient (P0) that represents the independent contribution of (each) independent variable in the prediction of outcome variable. To which the test has calculated a SEM and statistical significance, of course. 3) R square = the squared value of “r” = coefficient of determination = the proportion of outcome variance that is explained by the regression model and is usually presented as a proportion. The adjusted R square tends to correct R by putting some sort of penalty on each variable introduced in the model which normally increases R square. R ww & w. M rm So sol lut ut on ion s s.n et R ww & w. M rm So sol lut ut on ion s s.n et ANOVA is a more powerful test than the test of Student R ww & w. M rm So sol lut ut on ion s s.n et Guess the best test to compare: › Age groups: › 2) ANOVA R ww & w. M rm So sol lut ut on ion s s.n et › 1) Student’s test. Comparison of 2 anti thrombolytic drugs A and B. › Durations of hospital stay: › 1) Unpaired Student’s test. › 2) Non-parametric Mann & Whitney › Sex distribution: › 1) Chi-Square test › 2) Fisher’s exact test. › Success rates: › 1) Chi-Square test › 2) Student’s test. variable Group A N= 20 Group B N=20 Age (years) 54 + 2 54 + 2.5 Female sex 3 1 Success rate 10 5 Hospital stay d. 2.5 + 0.5 7 + 2.5 N= number of patients. Values are presented as numbers or mean + SD R ww & w. M rm So sol lut ut on ion s s.n et R ww & w. M rm So sol lut ut on ion s s.n et R ww & w. M rm So sol lut ut on ion s s.n et