Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
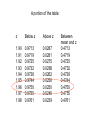
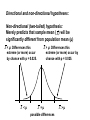
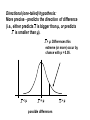
• From last lecture (Sampling Distribution): – The first important bit we need to know about sampling distribution is…? – What is the mean of the sampling distribution of means? – How do we calculate the standard deviation of the sampling distribution of means and what is it called? Hypothesis testing: The story so far... (a) The means of a sampling distribution are often normally distributed (even if the original population from which the samples came is not normal). This is true of N ≥ 30. (b) Any given sample mean ( X ) can be expressed in terms of how much it differs from the mean of the sampling distribution (i.e., as a z-score). Brain size in hares: sample means and population means population: mean = 500 g sample A: mean = 650g sample C: mean = 500g sample B: mean = 450g sample D: mean = 600g The Central Limit Theorem in action: Frequency with which each sample mean occurs: sample A mean sample F mean sample G mean sample B mean sample H mean sample C mean sample J mean sample D mean sample E mean sample K mean, etc..... the population mean, and the mean of the sample means (c) Any given sample mean can be expressed in terms of how much it differs from the population mean. Population mean A particular sample mean (d) "Deviation from the mean" is the same as "probability of occurrence": a sample mean which is very deviant from the population mean is unlikely to occur. A word about the use of the term “population” • The term does not necessarily refer to a set of individuals or items (e.g. cars). Rather, it refers to a state of individuals or items. • Example: After a major earthquake in a city (in which no one died) the actual set of individuals remains the same. But the anxiety level, for example, may change. The anxiety level of the individuals before and after the quake defines them as two populations. A concrete example: An American Sludge Oil Company has developed a new petrol additive that they claim will increase the mileage of cars • It is known that the current average of cars is 18 mi/gallon • A sample of 100 cars is taken and run on sludge fuel • The sample mileage is 19 mi/gallon • Is the Sludge company’s claim valid? • When the test is fair ONLY two sources contribute to the difference between the population and the sample: – The effect of the fuel additive – Random variability Our job is to decide which of these possibilities is it Hypothesis testing • Two types hypotheses: H0 and H1 • The NULL hypothesis (H0): The mean of the population from which the sample comes IS 18 mi/gallon. • The ALTERNATIVE hypothesis (H1): The mean of the population from which the sample comes IS SIGNIFICANTLY DIFFERENT FROM 18 mi/gallon. The question we want to ask is: How likely is it that the sample (N = 100) whose mean is 19 mi/gallon comes from a population whose mean and standard deviation are18 mi/gallon and 4 mi/gallon, respectively? Assume we know the following: • The population mean mileage of cars: k = 18 mi/gallon • The population standard deviation (σ) = 4 mi/gallon • The sample mean (X ) = 19 mi/gallon • Number of cars (N) = 100 The sampling distribution for N = 100 Frequency of sample means 17 µ = 18 19 4 X 0.4 N 100 We start by supposing the null hypothesis is true. Meaning that the sampling distribution from which our sample comes is one for which µ = 18 Then we ask what is the probability that our sample came from this distribution. If the probability is low, then we reject the null hypothesis in favor of the alternative hypothesis. Assume "innocent until proven guilty": we retain the null hypothesis unless there is enough evidence to allow us to reject it in favour of the alternative hypothesis. Large difference between sample mean and µ: reject H0, and assume H1 is true. If the difference is Small: have no reason to reject H0. How low does the probability have to be? • We usually select 0.05 as the cutoff. (Sometimes we also select 0.01). This is called the level of significance. • We look for X values that occur with a probability of 0.05 or less. Frequency of sample means 17 µ = 18 19 How low does the probability have to be? • We usually select 0.05 as the cutoff. (Sometimes we also select 0.01). This is called the level of significance. • We look for X values that occur with a probability of 0.05 or less. Frequency of sample means 17 µ = 18 19 How low does the probability have to be? • We usually select 0.05 as the cutoff. (Sometimes we also select 0.01). This is called the level of significance. • We look for X values that occur with a probability of 0.05 or less. Frequency of sample means 17 µ = 18 19 The shaded area corresponds to the 5% of the lowest and highest means (X ) in the sampling distribution Frequency of sample means 0.025 17 0.025 µ = 18 19 Next we find the critical values These are given as z-scores in the Table: Areas Under the Unit Normal Distribution Frequency of sample means upper critical value 1.96 lower critical value -1.96 0.025 17 0.025 µ = 18 19 A portion of the table: z Below z Above z 1.90 1.91 1.92 1.93 1.94 1.95 1.96 1.97 1.98 0.9713 0.9719 0.9725 0.9732 0.9738 0.9744 0.9750 0.9755 0.9761 0.0287 0.0281 0.0275 0.0268 0.0262 0.0256 0.0250 0.0245 0.0239 Between mean and z 0.4713 0.4719 0.4725 0.4732 0.4738 0.4744 0.4750 0.4755 0.4761 If z-observed ≥ than 1.96 then reject H0 Our z-score for the sludge company is: z observed X X X 19 18 1 2.50 4 0.4 N 100 So, we reject the Null hypothesis in favour of the alternative hypothesis How big must a difference be, before we reject H0? Two types errors can occur Type 1 error: reject H0 when it is true. (Also known as α, "alpha“ error). We think our experimental manipulation has had an effect, when in fact it has not. Type 2 error: retain H0 when it is false. (Also known as β, "beta“ error). We think our experimental manipulation has not had an effect, when in fact it has. Any observed difference between two sample means could in principle be either "real" or due to chance - we can never tell for certain. But Large differences between samples from the same population are unlikely to arise by chance. Small differences between samples are likely to have arisen by chance. Problem: reducing the chances of making a Type 1 error increases the chances of making a Type 2 error, and vice versa. Psychologists therefore compromise between the chances of making a Type 1 error, and the chances of making a Type 2 error: We set the probability of making a Type 1 error at 0.05. When we do an experiment, we accept a difference between two samples as "real", if a difference of that size would be likely to occur, by chance, 5% of the time, i.e. five times in every hundred experiments performed. Directional and non-directional hypotheses: Non-directional (two-tailed) hypothesis: Merely predicts that sample mean ( X ) will be significantly different from population mean (µ) X < µ: Differences this extreme (or more) occur by chance with p = 0.025. X > µ: Differences this extreme (or more) occur by chance with p = 0.025. X <µ X =µ possible differences X>µ Directional (one-tailed) hypothesis: More precise - predicts the direction of difference (i.e., either predicts X is bigger than µ, or predicts X is smaller than µ). X > µ: Differences this extreme (or more) occur by chance with p = 0.05. X <µ X =µ possible differences X>µ