Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
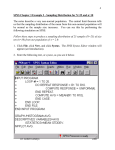
Robin Beaumont [email protected] Options for demonstrating sampling variability and sampling distributions in teaching statistics Tuesday, 11 October 2011 Contents Sampling in SPSS and R ................................................................................................................................................. 2 1 Using SPSS............................................................................................................................................................. 2 1.1 Using SPSS syntax ......................................................................................................................................... 2 1.1.1 One sample ........................................................................................................................................... 2 1.1.2 Multiple samples all the same size and from same distribution. ......................................................... 3 1.1.3 Samples of different sizes ..................................................................................................................... 4 1.1.4 Sampling distributions .......................................................................................................................... 6 2 Online Apps........................................................................................................................................................... 7 3 The standard error of the Mean ........................................................................................................................... 7 3.1.1 4 Effect of sample size upon SEM - formula appreciation....................................................................... 7 Using SPSS script ................................................................................................................................................... 8 4.1.1 Alternative script - Distribution.sbs ...................................................................................................... 9 5 In R ......................................................................................................................................................................10 6 Online presentations and other tools................................................................................................................11 Sampling in SPSS and R The aim of this handout is to describe the various options available for teaching the concept of sampling variability along with some student material. The process usually involves creating samples and then comparing them with both the parent population and amongst themselves (SEM demonstration). I have offered four ways of doing this below; Using SPSS (two methods) online apps and R. 1 Using SPSS 1.1 Using SPSS syntax The traditional way of investigating random samples in SPSS is to use the SPSS syntax window: 1.1.1 One sample Simple example to create a single sample with 1000 cases from a Normal distribution with mean = 100 ; SD=15: SPSS syntax *example of creating a random sample * Create 10,000 cases for sample NEW FILE. INPUT PROGRAM. LOOP #1 = 1 TO 10000. COMPUTE X = RV.NORMAL(100,15). END CASE. END LOOP. END FILE. END INPUT PROGRAM. EXECUTE. And to get a boxplot: Next exercise is to produce several samples. Use Analyze the get the results 1.1.2 Multiple samples all the same size and from same distribution. Variables called V20 to V30, all the same size. I have assumed that you have run the above syntax first if not you need to use the syntax below right: If have run above script If have not run above script NUMERIC V20 to V30. vector v = V20 to V30. * loop for sample size NEW FILE. INPUT PROGRAM. NUMERIC V20 to V30. vector v = V20 to V30. * loop for sample size LOOP #case = 1 TO 100. *loop for each sample LOOP #case = 1 TO 100. *loop for each sample LOOP LOOP #i= 1 TO 11. #i= 1 TO 11. *now we have to specify both column(sample) and row (sample number) *now we have to specify both column(sample) and row (sample number) COMPUTE v(#i) = RV.NORMAL(100,15). END LOOP. COMPUTE v(#i) = RV.NORMAL(100,15). END LOOP. END CASE. END LOOP. END FILE. END INPUT PROGRAM. END LOOP. EXECUTE. EXECUTE. Typical output: V20 V21 V22 V23 V24 V25 V26 V27 V28 V29 V30 N 100 100 100 100 100 100 100 100 100 100 100 Descriptive Statistics Mean Std. Deviation 101.5421 14.20531 101.0039 15.53362 99.1124 14.14247 97.6240 14.07071 99.9382 14.43248 100.1818 13.80487 100.4502 15.45697 101.6055 15.04477 100.8888 14.05551 101.6523 14.24829 99.9043 14.19884 1.1.3 Samples of different sizes Two main ways to do this, you can create all the samples in a single variable and add a Grouping variable or alternatively create several variables with different sample sizes in each. For various reason the former strategy is best however just for interest I have included below the latter option of putting the various samples of different sizes in separate variables: NEW FILE. INPUT PROGRAM. LOOP #count = 1 TO 500. DO IF (#count <31). COMPUTE samp30 = RV.NORMAL(100,15). END IF. DO IF (#count <51). COMPUTE samp50 = RV.NORMAL(100,15). END IF. DO IF ( #count <101). COMPUTE samp100 = RV.NORMAL(100,15). END IF. COMPUTE samp500 = RV.NORMAL(100,15). END CASE. END LOOP. END FILE. END INPUT PROGRAM. EXECUTE. This approach (i.e. separate variable each sample) causes problems when analysing the data as SPSS considers the smaller samples to have missing values! Therefore the better solution is to use a grouping variable that is an identifier indicating the sample each observation(case) belongs to. The next SPSS syntax script duplicates the above but just creates two variables (one called GROUP the other VALUE) here: new file. input program. loop #i=1 to 30. compute group=1. compute value=rv.Normal(100,15). end case. end loop. loop #i=1 to 50. compute group=2. compute value=rv.Normal(100,15). end case. end loop. loop #i=1 to 100. compute group=3. compute value=rv.Normal(100,15). end case. end loop. loop #i=1 to 500. compute group=4. compute value=rv.Normal(100,15). end case. end loop. end file. end input program. execute . The code opposite is not the most elegant you could use one loop with a number of 'DO IF' statements: new file. input program. loop #i=1 to 500. DO IF (#i<31). compute group=1. compute value=rv.Normal(100,15). end case. END IF. DO IF (#i<51). compute group=2. compute value=rv.Normal(100,15). end case. END IF. DO IF (#i<101). compute group=3. compute value=rv.Normal(100,15). end case. END IF. compute group=4. compute value=rv.Normal(100,15). end case. end loop. end file. end input program. SORT CASES by group(a). execute . Both the above SPSS syntax files do the same thing that is produce four samples of different size from a normal distribution with mean 100 SD=15. Obviously you could easily change the parameters of the distribution or even change the actual distribution, Two alternatives are: the uniform: rv.Uniform(lower, upper) or exponential: rv.exp(mean) Using the Explore command in SPSS shows the SD for each group and also a box plot. Carrying out the above tasks it is then possible to complete the following table. Sample size Minimum value mean Maximum value Standard deviation 30 50 100 500 Theoretical population value The above exercise will demonstrate; Standard deviation varies little over sample size - there must be a sample adjustment factor in it! Mean also varies little (repeated sampling for smaller samples produces wider variation - next exercise) from the population mean of 100 The above exercise can then be repeated changing the sample size to 3, 10, 20, 30 new file. input program. loop #i=1 to 3. compute group=1. compute value=rv.Normal(100,15). end case. end loop. loop #i=1 to 10. compute group=2. compute value=rv.Normal(100,15). end case. end loop. loop #i=1 to 20. compute group=3. compute value=rv.Normal(100,15). end case. end loop. loop #i=1 to 30. compute group=4. compute value=rv.Normal(100,15). end case. end loop. end file. end input program. execute . Given these are random samples each person will obtain a different result however what they should notice is that the means(medians in above boxplot) vary less as the sample size gets larger. You could ask them to repeatedly create multiple random samples of varying size then plot the means (technically what we would produce is a sampling distribution of the mean) but at this stage it is probably better to revert to online simulations (see below). 1.1.4 Sampling distributions Student typical explaination: So far we have looked at the characteristics of one or more samples from a population but what about the characteristics across samples! Why, you may well ask, would we bother with such additional complexity but just consider this: I have a valuable substance (Guinness) and only want to take as small sample as possible to find an accurate mean value of substance X. So how can we calculate what would be a small enough sample to produce a accurate mean value? To answer this question obviously we need to assess the variation of means across samples of a specific size. While we have done this for a small number of samples we will now consider many samples to produce a distribution. 2 Online Apps Go to http://onlinestatbook.com/stat_sim/sampling_dist/index.html Using the app at this website we can ask for repeated samples of different sizes and then plot their means. I have done it for 10,000 samples of size 5 and also size 25 - Students should notice how much more spread out the means are for the smaller samples. . Student explanation: 3 The standard error of the Mean The Standard Error of the Mean provides a measure of the standard deviation of sample means. In other words it is just another standard deviation but now we are at the between sample level rather than within sample level. Because we are working at a different level the name has changed for the same idea concerning spread. From the above exercise, we have both the population data along with information about a set of samples from it. Interestingly all we need to calculate the SEM is information from a single sample. We will now compare the observed answer (for the samples in the above screen shot = 2.23 for samples of size 5) with a specific formula. This formula is known as the SEM (Standard Error of the Mean). 𝜎2 𝜎𝑥̅ = √ 𝑛 = 𝜎 √𝑛 = 𝑠𝑡𝑎𝑛𝑑𝑎𝑟𝑑 𝑑𝑒𝑣𝑖𝑎𝑡𝑖𝑜𝑛 𝑜𝑓 𝑠𝑎𝑚𝑝𝑙𝑒 𝑠𝑞𝑢𝑎𝑟𝑒 𝑟𝑜𝑜𝑡 𝑜𝑓 𝑛𝑢𝑚𝑏𝑒𝑟 𝑖𝑛 𝑠𝑎𝑚𝑝𝑙𝑒 = 5/√5 = 2.236 and for the sample size of 25 SEM = 5/√25 = 1 We can see from the above formula that the Standard Error of the Mean is equal to the standard deviation divided by the square root of the sample size. We have samples of size 5 and 25 so we can calculate the SEM from each one. You will notice that the observed SD of the sample means is identical to that using the formula this is truly amazing We can predict the distribution of means of random samples without carrying out the sampling just using the SEM formula. 3.1.1 Effect of sample size upon SEM - formula appreciation We know that the formulae for the standard error of the mean (SEM) is: 𝜎2 𝜎 𝑠𝑡𝑎𝑛𝑑𝑎𝑟𝑑 𝑑𝑒𝑣𝑖𝑎𝑡𝑖𝑜𝑛 𝑜𝑓 𝑠𝑎𝑚𝑝𝑙𝑒 𝜎𝑥̅ = √ = = 𝑛 𝑠𝑞𝑢𝑎𝑟𝑒 𝑟𝑜𝑜𝑡 𝑜𝑓 𝑛𝑢𝑚𝑏𝑒𝑟 𝑖𝑛 𝑠𝑎𝑚𝑝𝑙𝑒 √𝑛 Lets consider what happens to the SEM as the sample size changes. From the above equation the top value (numerator) will remain constant, but the bottom value (denominator) will increase. What happens in this instance, which is a property of all fractions, is that the total value decreases, therefore as sample size increases the variability of the sample means decreases. You can think of it in terms of accuracy, the larger the random sample the more accurate the SEM, a statistician would say that this indicated that it was a consistent estimator As N increases -> SEM decreases To learn more about SPSS syntax see the excellent tutorial including datasets and videos at: http://www.ats.ucla.edu/stat/spss/seminars/spss_syntax/default.htm 4 Using SPSS script SPSS scripts allow users to create additional dialog boxes and several people have produced scripts which provide dialog boxes for creating random samples. This is probably an easier alternative to learning SPSS syntax. http://www.spsstools.net/SampleScripts.htm provides three possible scripts Right mouse click on the "Generate Random variables EN SBS" link select the "Save Link as" option to save the script file to your local drive change the default extension from txt to sbs. Back in SPSS: This allows you to create multiple samples of a specific size. You can also run the script several times to create many samples by un-checking the "Replace the working data file" option. 4.1.1 Alternative script - Distribution.sbs You will then be presented with: Type in the sample size you want: Step 1 - click next to allow you to select: Step 2 - the distribution, I selected Normal Step 3 - - you can change the mean, SD. Once you have created one sample you can create up to 20 different ones each time clicking next To finish click the Finish button! Typical results using the menu option explore: Case Processing Summary group value dimension1 1.00 2.00 3.00 4.00 N 30 20 15 10 Valid Percent 100.0% 100.0% 100.0% 100.0% N 0 0 0 0 Cases Missing Percent .0% .0% .0% .0% N 30 20 15 10 Total Percent 100.0% 100.0% 100.0% 100.0% 5 In R R is not for the lazy! but it is amazingly versatile. This section is for completeness. # this is a comment #create a plot x axis=0 to 62 y axis=50 to 150 # Give the axes labels plot(c(0,62), c(50,150), type="n",xlab="Sample size", ylab="mean") #sample size 3 to 30 in steps of 2 (=df) for (df in seq(3,61,2)) { # number of samples (=60) at each size for (i in 1:60) { # create random samples from a normal distribution of size df # and store in the vector (column) x x<- rnorm(df,mean =100, sd=15) points(df,mean(x)) } # end for each group of samples } # end for each sample size You can see an animated version of the above at: http://animation.yihui.name/prob:law_of_large_numbers this site has a large number of animations all written in r code using the free R animation package. To the casual visitor all the R code is hidden away they just seeing the beautiful animations. With more R knowledge one can create more complex examples, the following is taken from Maindonald & Braun 3rd ed. 2010 p. 89. This produces 10,000 simulations of different samples of different sizes from a skewed distribution. The code below can be used as the basic for a large number of similar exercises. ############################### from Miandolald & Braun p.89-90 ######## CUP 2010 ## uses the lattice library library(lattice) ############## # function to generate n sample values sampvals <- function(n) exp(rnorm(n, mean = 0.5, sd = 0.3)) ## Means across rows of a dimension nsamp x sampsize matrix of ## sample values gives nsamp means of samples of size sampsize. samplingDist <- function(sampsize = 3, nsamp = 1000, FUN = mean) apply(matrix(sampvals(sampsize * nsamp), ncol = sampsize), 1, FUN) size <- c(3, 10, 30) ## Simulate means of samples of 3, 9 and 30; place in dataframe df <- data.frame(y3 = samplingDist(sampsize=size[1]), y9 = samplingDist(sampsize=size[2]), y30 =samplingDist(sampsize=size[3])) ############### ## use the strip.custom to customise the strip labelling doStrip <- strip.custom(strip.names = TRUE, factor.levels= as.expression(size), var.name= " sample size", sep = expression(" = ")) ## Then include the argument 'strip=doStrip' in the call to densityplot ############### ## Simulate source population (sampsize = 1) y <- samplingDist(sampsize = 1) densityplot(~y3+y9+y30, data=df, outer=TRUE, layout= c(3,1), plot.points = FALSE, panel = function(x, ...) { panel.densityplot(x,..., col = "black") panel.densityplot(y, col = "gray40", lty=2, ...) }, strip=doStrip) 6 Online presentations and other tools The new Zealand census at school Website http://www.censusatschool.org.nz/resources/statistical-investigation/ contains a section on informal inference, called "The eyes have it" http://www.censusatschool.org.nz/2009/informal-inference/ which contains animated gifs that people can use in their representations and also an excellent presentation concerning sampling variability and how this can informally relate to hypothesis testing see: http://www.stat.auckland.ac.nz/~wild/09.USCOTSTalk.html http://www.censusatschool.org.nz/2009/informal-inference/Maxine.Combined.Use.html End of document