Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Mid. Term Exam. –Data Warehouse & Data Mining 2004
1. Let X = {(1,2,3), (1,2,4), (1,3,5), (2,3,4), (2,3,5), (2,4,5), (3,4,5)}. (a) if X is the set
of frequent itemsets (L3), write down the candidate itemsets of length 4 (C4) after
pruning. (b) if X is the set of candidate itemsets, hash-bucket size of a leaf = 2,
the branch size of a node = 3 and hash function = item_id % 3, show the hash-tree
in Apriori. (c) Indicate the candidates to be checked while counting the supports for
a transaction = (1, 3, 4, 6) (d) Place X in a LexTree [2%, 4%, 5%, 4%]
2. Given a transaction database as follows. (a) Compute confidence of rule (C)
(A,B,E) (b) compute support of (A,C) (B,E) [2%, 3%]
A B C D E
1
2
3
4
5
6
7
8
9
10
3. The database in a query system has 80 items. An expert confirms that 48 items
belong to “Good” class. Assume that we submit a query to find items having class
“Good”. The query system gives us 60 items, 32 items are really “Good” class
among the 60 items. (a) Compute recall (b) compute precision? [3%, 2%]
4. Give two examples of concept hierarchy. [5%]
5. We have a video rental database. Each record in the database has three attributes:
Date, Customer_name, Videos. For example, On Nov. 19, “Tom” rent “ID4” and
“Gone with the wind”. Using this database and show (a) a typical database query
(b) a data mining query [2%, 3%]
6. Explain the MAIN difference(s) between classification and clustering. [5%]
7. Compare classification by decision tree technique and by neural network
1 of 2
Mid. Term Exam. –Data Warehouse & Data Mining 2004
technique. [5%]
8. Compute correlation coefficient for X = <1, 4, 6, 15, 17> and Y = <-5, 8, -7, 2,
19>. [5%]
9. Given a data set below, where “play” is the class attribute. (a) What’s the
information of the data set? (b) What’s the entropy of attribute outlook? (c) While
creating a corresponding decision tree based on ID3, how do you choose the
attribute to be used in the root node? (d) Based on CART, what’s the splitting
point of Temperature? (if Cool < Mild < Hot) (e) Given a decision tree below, use
this data set as test samples and compute the error rate of the tree. [2%, 3%, 2%,
4%, 4%]
Outlook Temperature Humidity Wind Play?
Sunny
Hot
High Weak No
Sunny
Hot
High Strong Yes
Overcast
Hot
High Weak Yes
Rain
Mild
High Weak Yes
Rain
Cool
Normal Weak Yes
Rain
Cool
Normal Strong No
Overcast
Cool
Normal Strong Yes
Sunny
Mild
High Weak No
Rain
Mild
Normal Weak Yes
Sunny
Cool
Normal Weak Yes
Decision Tree for PlayTennis
Outlook
Sunny
Humidity
High
No
Overcast
Rain
Yes
Normal
Wind
Strong
Yes
No
Weak
Yes
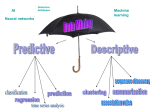
10. Describe the following terms. (a) Data Mining (b) KDD (c) OLAP (d) Predictive
Data Mining (e) Descriptive Data Mining (f) Outlier (g) Overfitting [5% each]
2 of 2








![CS 634 DATA MINING QUESTION 1 [Time Series Data Mining] (A](http://s1.studyres.com/store/data/002423347_1-e72e0e06e7b13ca523d023405f882809-150x150.png)