Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
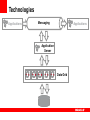
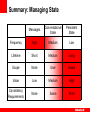
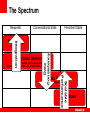
<Insert Picture Here> Orchestrating Messaging, Data Grid and Database Jon Purdy Oracle Corporation Notes • Companies and Products • Oracle acquired Tangosol back in June • Coherence is a Data Grid solution • Questions are encouraged Agenda • Technology Stack Overview • Introduction to Data Grid technology • Application State • Types of State • Challenges • Putting it together • How state is managed by application tiers • How to integrate application tiers • How Data Grids can “fill in the gaps” Technology Stack Overview There are many tools for building scalable, reliable systems Messaging Application Servers Data Grids Databases What types of state do these manage? When should each one be used? Technologies • Messaging • Integration between systems (queues) • Distributing relevant data (topics) • Application Servers • Request processing • Conversational state • Data Grids • Scalability and performance • Conversational state and/or limited persistent state • Databases • Persistent state • Reliable, shared conversational state (if needed) Technologies Applications Messaging Applications Application Server Data Grid Data Grids: What are they? • Special-purpose data management solution • Live, transactional data at in-memory speed • “First class” programmatic access • Built from the ground-up for in-memory efficiency • Avoids CPU overhead of disk management • Usually a native “object” view of data • Less flexible than a “true” database • Query optimization is an “unsolvable” problem • Three decades of RDBMS evolution offsets that • Less focus on long-term storage Data Grids • Extend the coherency protocol to client applications • Take advantage of the native “object” view of data • Keep important data local for efficiency • OR/M can sometimes be slower than the actual query • Implementations • Oracle Coherence • GemStone GemFire • IBM ObjectGrid A Brief History Relational DBMS • Relational DBMS • Relational structure allows any view of data • Minimizes impact of data schema mistakes • Databases for The People • With 4GL tools, led to the Client-Server revolution • And even power users: Microsoft Excel and Access • The critical ingredient: Query Optimizer • DBMS assumes responsibility for optimizing data access Relational DBMS • But… • Static optimization (RBO) is not 100% reliable • Dynamic optimization (CBO) is not 100% reliable • Mistakes magnified with scale and load • Scalability and availability problems Object DBMS • Brief appearance in late 80’s / early 90’s • Some impressive performance feats • Extremely efficient for intended access patterns • Data schema coupled to business logic • Difficult to evolve data schema • Market segment as a whole has died • A few stragglers left The best of all worlds • Take the efficiency of an Object DBMS … • In-memory data coupled to application access patterns • Consistent access patterns at runtime • … Add scale-out as a primary objective … • … And leverage the RDBMS • Existing storage resources and skills • Loosely coupled data schemas How does it work? Partitioned Cache Partitioned Cache Partitioned Cache Near Cache Types of State Characteristics Types of State • Messages • Request/Response • Source: user, message queue or another application tier • “Show inventory list” (display web page in browser) • Just a message from one system to another • Conversational State • Stateful Applications • Spans multiple requests (a “conversation”) • “Add item to shopping cart” (update HTTP session) • Internal state • Persistent State • Typically stored in a database • “Place order” (persist order to database) • Externally visible Connecting the dots… • Applications process requests, taking into account the context of those requests, to manage persistent data • Therefore, effective applications must ensure that: • • • • Requests are properly processed Proper context is maintained Persisted data is correct All of this is done in a timely manner Characteristics: Messages • Short-lived • Interactive apps: milliseconds to a few seconds • Integration: similar, unless one of the systems is down • Immutable and single-writer pattern • By definition, each request submitted by a single system • Almost no way to corrupt state, and easy to avoid losing state • “Stateless” applications are very easy to scale • Simple request-response processing • Requests are often retry-able (idempotent) Characteristics: Conversational State • Longer-lived • A few seconds to several minutes • Mutable, but by a single user • Not quite single-writer • Simultaneous requests from a user • Multiple portlets in a portal application • Multiple clicks at the same time • Load-balancing issues: failover/failback/rebalancing • Often recoverable • Worst case, by restarting the session Characteristics: Persistent State • Long-lived • Rarely less than a few days; often many decades • Often have regulatory requirements for several years • Mutable and globally shared • Possible interaction and contention from all users • Concurrency and data consistency are hard to combine • The entire application shares one persistent state Summary: Managing State Messages Conversational State Persistent State Frequency High Medium Low Lifetime Short Medium Long Scope None User Global Value Low Medium High Consistency Requirements None Some Strict Types of State Challenges Challenges • Messages • Most considerations relate to interactions between systems • These interactions are effectively distributed transactions • It is critical to manage these “transactions” both reliably and efficiently Challenges • Conversational state • Most applications can tolerate modest corruption (or loss) of conversational state (or do anyway) • Those that can’t assume this will generally place this state in a reliable data store, or avoid conversational state altogether • While technology solutions exist, scaling stateful applications remains a challenge Challenges • Persistent state • As the “System of Record”, persistent state is the most valuable asset • Databases are the default option for properly managing persistent state • However, scaling and performance concerns often move data management out of the database, increasing the difficulty of managing it correctly Impact of lost/corrupted data • Messages • User gets a failed request • User resubmits request (click again) • Impact limited in scope (one user) and time (one request) • Conversational State • • • • User’s session is corrupted or missing If detected by the system, user may need to log in again and start over If not detected, the user will usually (but not always) notice Impact limited in scope (one user) and time (one session) • Persistent State • • • • Persistent State is the primary objective! For the user: Payment received but order not shipped For everyone: Inventory levels are incorrect Impact is global for all users and for all time! Critical Areas of Concern Messages Performance Scalability Availability Consistency Scalability Availability Consistency Scalability Availability Consistency Conversational State Performance Persistent State Performance Messaging Compare, Contrast, Integrate Messaging • Topics • One-to-many: subscribers sign up to topics of interest • All subscribers receive messages as they occur • Emphasis on fast delivery to many subscribers (performance, scalability) • Queues • Used primarily for communication between two systems • Physical decoupling of sender and receiver • Emphasis on reliable message delivery (durability) • Implementations • TIBCO Rendezvous, IBM MQSeries Messages • Requests typically flow through multiple systems • Message Queue → App Server → Database • Browser → Web Server → App Server → Database • Ensure that each request is processed • … even if a participating service fails • Failure of either client or server can result in “dropped” or “duplicated” requests • Most common requirement is “once and only once” but other variants may be acceptable (“at most once”, “at least once”) Traditional Message Processing • Integrating multiple systems may require distributed transactions (XA) • Distributed transactions • • • • • • Simple to integrate: minimal effect on application architecture E.g. enlist both the database and the queue Slow (“disk forces”) Tendency to cause lock contention (two-phase locking) Not 100% reliable (“heuristic failures”) Not widely supported (lack of support, compatibility issues) Idempotency • Concept • If the client knows the server can handle duplicate requests … • Then the client can err on the side of re-sending “in doubt” requests • A partial failure results in a complete retry • No need to use XA to coordinate client and server • Impact • May have a noticeable impact on application architecture • Fast • Very reliable Message Processing with XA • • • • • • • • JMS begin TX DB begin TX Read message Write to database Prepare JMS Prepare DB Commit JMS Commit DB • If the prepare phase fails in either JMS or DB, the DB transaction is rolled back, and the JMS message is left in the queue • If the commit phase fails, that is a heuristic failure; the state of the transaction is “unknown” Idempotent Message Processing with Local Transactions • • • • • • JMS begin TX DB begin TX Read message Write to DB (Idempotent) Commit DB Commit JMS • If commit to DB fails, the entire operation is aborted; the message is still in the queue • If commit to JMS fails, the JMS de-queue is rolled back (but the DB commit isn’t) • The next time the message is processed, the write to the DB will occur, but the operation won’t have undesired side effects Data Grid and Messaging • Data Grids can be used as a messaging fabric • But introduces global visibility of a new infrastructure piece • Established players have more mature solutions • And operations team know these products • Messaging usually used within the Data Grid • Not between disparate applications • One exception • Data Grids can use write-behind queueing to avoid the need for a dedicated message broker • Queue the messages in memory, not on disk • Slight reduction in durability but reduces operating costs Application Server Compare, Contrast, Integrate Application Servers • Application “containers” • Provide a framework for managing requests and (usually) conversational state • May manage lifecycle of application deployment packages • Also service directories (JNDI / Jini lookup services) • Implementations • • • • JavaEE: WebLogic, WebSphere, JBoss, Oracle AS, etc. Compute Grid: Platform Symphony, DataSynapse GridServer Jini: Blitz, GigaSpaces Spring • Requests • Route incoming requests (e.g. from TCP socket) to application components • Conversational State • JavaEE: HTTP sessions (conversation between user and web server) • Jini: JavaSpaces (conversation between multiple processes) Conversational State Topologies • In-memory (no replication) • Fastest, most scalable option • Server failure results in data loss • Single-server visibility (dependent on sticky load balancer) • In-memory (replication) • Fast, scalable (implementations vary) • Widely available, sufficient for most use cases • Most implementations are not fully coherent under load or failure • Database persistence • Higher complexity and lower performance • Achieves data consistency, commonly available • Scales with database server (for better or worse) Conversational State • Unreliable conversational state • No in-memory replication (data loss) • Incoherent in-memory replication (data corruption) • Tools • Idempotent processing • Reliable data store • Concept • Use application and data store to verify correctness on commit • Verify order placement on web page • Use optimistic concurrency on database to check values • Use idempotent processing to retry request chain • Buyer corrects shopping cart and resumes checkout process • Or for closed-loop systems, recover missing conversational state by replaying requests or re-loading from database (selectively persisted for performance) Database Compare, Contrast, Integrate Database • The only real solution for persistence? • Permanent “System of Record” • Guaranteed data consistency • Operations • • • • Perhaps the most widely deployed technology In-house operations teams already know how to use Strongest query technology (robust cost-based optimizers) Plenty of support: 3rd party tool vendors, consultants, documentation, discussion forums, etc. Database • Usually the easiest and most reliable solution for managing persistent state • But supply … • Absolute requirement for data consistency • Consistency requirements make scaling difficult (but possible) • … may not meet demand • Front tiers are inexpensive and easy to scale • Scaling on the front causes massive load on the back • Offloading can help with managing persistent data • Eventually faces diminishing returns from overhead and complexity Offloading via Caching • Keep a local partial data set for faster access • Beneficial for read-heavy applications • Gained popularity by mitigating the EJB BMP N+1 problem • Limited gains for transactions and queries • Relatively transparent to application architecture • Weak requirements for data consistency • With optimistic concurrency, data consistency is delegated to SoR • For presentation layer, dirty reads are often acceptable Offloading Analytics • Run queries against a copy of the System of Record • System of Reference • Data consistency is important • Depends on usage • Generally operating against a point-in-time snapshot • Data resilience is a Quality of Service consideration • Recoverable from the System of Record • Failure will affect availability but not results Offloading Events • Changes to the System of Record may need to trigger additional processing • Challenges • Ensuring all changes of any relevant state are handled in a timely manner • Absolute data consistency required for change events and the context of those events (ordering, subscribers, etc) • Hard to do all of these • Absolute data consistency • “Fan-out” of events from transactions • Timely delivery of events Offloading Transactions • The System of Record must manage all transactions related to its “owned” data • But a given piece of data may have different owners over even short periods of time • Important to identify which system owns each piece of data • Usually achieved by “owning” part of the permanent store • Data consistency required Data Grids can help • Conversational state • Combine the data consistency of a database with the performance of local in-memory data • Persistent state • Running queries in the data grid can remove the query load on a database • Committing transactions in-memory then persisting in batches can reduce the transaction load of a database • Abstraction of data sources Data Source Integration Read Through Data Source Integration Write Through Data Source Integration Write Behind Data Grid: Data Source Integration • Data Integration occurs in the Data Service • Integration uses the domain model • The data is both live and shared • Events provide bi-directional flow • Applications can respond to events Data Service Clients Summary of Data Grid Integration Points • Messaging • Data Grid can be used for internal application messaging • Application Server • Scale data availability reliably along with processing power • Database • Offload transactions and analytics to Data Grid for higher throughput The Spectrum Requests Conversational State Persistent State Integration Messaging Application Servers Data Consistency Topics, Queues Requests: JavaEE, Jini, Compute Grid Conversational: HTTP Sessions, Stateful EJBs, JavaSpaces Scalable Performance Data Grids Data Grid, In-Memory Database Database Thank You!