Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
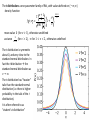
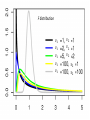
6 Sampling Distributions Statisticians use the word population to refer the total number of (potential) observations under consideration The population is just the set of all possible outcomes in our sample space (chapter 3) Therefore, a population may be finite (e.g. number of households in the US) or (effectively) infinite (e.g. number of stars in the universe) e.g. question: average number of TV sets per household in US population: number of TV sets in each household in US question: average number of TV sets per household in North America population: number of TV sets in each household in Canada, US and Mexico question: probability that a star has planets population: number of planets per star for all stars (past, present, future) in all galaxies in the universe In answering questions (e.g. what is the mean, what is the variance, what is the probability) for a given population, one seldom answers the questions using the entire population. In practice the questions are answered from a subset (a sample) of the population. it is important to choose the sample in a way that does not bias the answers This is the subject of an area of statistics referred to as experimental design. (how to design the sample such that you adequately reflect the entire population) e.g. in determining the probability of getting a pair in a poker hand, you would not sample only poker hands that contained two pairs. (technically this would be an attempt to determine the probability P(pair) for the entire population by approximating it by a conditional probability P(pair|two pair) e.g. To determine the average length of logs moving on a conveyor belt at constant speed, one might decide to measure only the logs that pass a certain point on the conveyor belt every 10 minutes. Upon reflection, you realize that longer logs have a greater probability of being at the measuring point at the selected times, thus the sample would give a biased average length measure that would be too large. e.g. to determine the expected lifetime of a tire, you only test it on smooth, paved roads? e.g. to determine fuel rating on cars, the EPA presumes that every car is driven 55 percent of the time in the city and 45 percent of the time on the highway!? One way to ensure unbiased sampling is to ensure your subset is a random sample Suppose our sample is to consist of n observations, 𝑥1 , 𝑥2 , … , 𝑥𝑛 . We have to select the first observation 𝑥1 , the second 𝑥2 , etc. We think of the procedure for picking 𝑥𝑘 as selecting a value for a random variable 𝑋𝑘 , that is, we think of picking values 𝑥1 , 𝑥2 , … , 𝑥𝑛 for our sample as the process of picking values for n random variables 𝑋1 , 𝑋2 , … , 𝑋𝑛 . Using this thinking, we can define a random sample as follows: finite population: A set of observations 𝑋1 , 𝑋2 , … , 𝑋𝑛 constitutes a random sample of size n from a finite population of size N, if values for the set are chosen so that each subset of n of the N elements of the population has the same probability of being selected. infinite population: A set of observations 𝑋1 , 𝑋2 , … , 𝑋𝑛 constitutes a random sample of size n from the infinite population described by distribution (discrete) or density (continuous) 𝑓(𝑥) if 1. each 𝑋𝑖 is a RV whose distribution/density is given by 𝑓(𝑥) 2. the n RVs are independent The phrase random sample is applied both to the RV’s 𝑋1 , 𝑋2 , … , 𝑋𝑛 and their values 𝑥1 , 𝑥2 , … , 𝑥𝑛 How to achieve a random sample? e.g. the population is finite (and relatively small) Label each element of the population 1, 2, …, N. Draw numbers sequentially, in groups of n, from a random digits table When the population size is large or infinite, this process can become practically impossible, and careful thought must be given to, at least approximate, random sampling design. e.g. areal sampling using a regular grid works if underlying population (e.g. chemical contaminant concentration) is relatively homogenous. Doesn’t work if underlying population is spatially concentrated. e.g. replicate sampling in “anomalous” areas 6.2 Sampling Distribution of the Mean For each sample 𝑥1 , 𝑥2 , … , 𝑥𝑛 of n observations, we can compute a mean 𝑥 . The mean value will vary with each of our samples. Thus we can think of the sample mean (mean value for each sample) as a random variable 𝑋 obeying some distribution function 𝑓(𝑥 ; 𝑛) The distribution 𝑓(𝑥 ; 𝑛) is referred to as the theoretical sampling distribution. We put aside for the moment the question of the form for 𝑓(𝑥 ; 𝑛) and note that, in chapter 5.10, we have already computed the mean and variance for 𝑓(𝑥 ; 𝑛) in the case of continuous RV’s. Theorem 6.1: If a random sample 𝑋1 , 𝑋2 , … , 𝑋𝑛 of size n is taken from a population having mean 𝜇 and variance 𝜎 2 , then 𝑋 is a RV whose distribution 𝑓(𝑥 ; 𝑛) has: infinite population finite population mean value E(𝑋) = 𝜇 and variance 𝑉𝑎𝑟 𝑋 = mean value E(𝑋) = 𝜇 and variance 𝑉𝑎𝑟 𝑋 = 𝑁−𝑛 𝜎2 𝑛 𝜎 2 𝑁−𝑛 ∙ 𝑛 𝑁−1 Note: The appearance of the term 𝑁−1 for the variance of 𝑋 in the finite population case is unexpected based upon the calculation in 5.10. The calculations in 5.10, when applied to a finite population, assume that 𝑛 ≪ 𝑁. This correction factor, called the finite population correction (fpc) factor is included to account for cases in which 𝑛 ≲ 𝑁. Note that the fpc factor =0 for 𝑛 = 𝑁. (i.e. 𝑉𝑎𝑟 𝑋 =0 when 𝑛 = 𝑁). This implies that, when one sample is taken using the entire population, 𝑋 exactly measures the population mean with no error (variance). e.g. For N = 1,000 and n = 10, the fpc is 990 𝑓𝑝𝑐 = = 0.991 999 Note that the results in Theorem 6.1 are independent of what 𝑓(𝑥 ; 𝑛) may actually be !!! Apply Chebyshev’s theorem to the RV 𝑋 𝑃 Let 𝜖 = 𝑘 𝜎 , 𝑛 i.e. k = 𝑛𝜖 , 𝜎 𝑋−𝜇 >𝑘 𝜎 1 < 2 . 𝑘 𝑛 giving 𝜎2 𝜎2 𝜖2 𝑃 𝑋−𝜇 >𝜖 < 2 = 𝑛𝜖 𝑛 Therefore, for any (arbitrarily small but) non-zero value for 𝜖, the probability that 𝑋 differs from 𝜇 can be made arbitrarily small by making n large enough. (We need 𝑛 ≫ 𝜎 2 𝜖 2 , which means n must get very large as 𝜖 gets small). This observation is known as the law of large numbers (if you make the sample size large enough, a single sample is sufficient to give a value for 𝑥 arbitrarily close to the population mean.) Theorem 6.2 Let 𝑋1 , 𝑋2 , … , 𝑋𝑛 be a random sample, each having the same mean value 𝜇 and variance 𝜎 2 . Then for any 𝜖 > 0 𝑃 𝑋 − 𝜇 > 𝜖 → 0 as 𝑛 → ∞ as the sample size gets large, the probability that the average from a single random sample differs from the true mean goes to zero. Again – this result on 𝑋 is independent of what 𝑓(𝑥 ; 𝑛) may actually be. e.g. In an experiment, event A occurs with probability p. Repeat the experiment n times and compute number of times A occurs in 𝑛 trials 𝑛 relative frequency of occurrence of A = Show that the relative frequency of A → 𝑝 as 𝑛 → ∞ Consider each trial as an independent RV, 𝑋1 , 𝑋2 , … , 𝑋𝑛 Each 𝑋𝑖 takes on two values, 𝑥𝑖 = 0,1 depending on whether A does not or does occur in experiment i. 𝑋𝑖 has mean value E 𝑋𝑖 = 0 ∙ 1 − 𝑝 + 1 ∙ 𝑝 = 𝑝 and variance 𝑉𝑎𝑟 𝑋𝑖 = 𝐸 𝑋𝑖2 − 𝐸 𝑋𝑖 2 = 02 ∙ 1 − 𝑝 + 12 ∙ 𝑝 − 𝑝2 = 𝑝(1 − 𝑝) Then 𝑋1 + 𝑋2 + ⋯ + 𝑋𝑛 records the number of times A occurs in n trials, and 𝑋1 + 𝑋2 + ⋯ + 𝑋𝑛 𝑋= 𝑛 is in fact the relative frequency of occurrence of A. From Theorem 6.2 we have 𝑝(1 − 𝑝) 𝜖 2 𝑃 𝑋−𝑝 >𝜖 < → 0 for any 𝑝 ∈ [0,1] as 𝑛 → ∞ 𝑛 𝑉𝑎𝑟(𝑋) ≡ 𝜎𝑋 = 𝜎 𝑛 is referred to at the standard error of the mean. To reduce the standard error by a factor of two, it is necessary to increase 𝑛 → 4𝑛. Thus (unfortunately) increasing sample size decreases the standard error at a relatively slow rate. (e.g. if n goes from 25 to 2,500 (a factor of 100), the standard error decreases only by 10.) While the results in Theorems 6.1 and 6.2 are independent of the form of the theoretical sampling distribution/density 𝑓(𝑥 ; 𝑛), the actual form for 𝑓(𝑥 ; 𝑛) depends on knowing the probability distribution which governs the population. In general it can be very difficult to compute the form of 𝑓(𝑥 ; 𝑛). Two results are known – both presented as theorems. Theorem 6.3 (central limit theorem) Let 𝑋 be the mean of a random sample of size n taken from a population having mean 𝜇 and variance 𝜎 2 . Then the associated RV, the standardized sample mean 𝑋−𝜇 𝑍≡ 𝜎 𝑛 is a RV whose distribution function approaches the standard normal distribution as 𝑛 → ∞ The central limit theorem says that, as 𝑛 → ∞, the theoretical sampling distribution 𝑓(𝑥 ; 𝑛) → a normal distribution (i.e. 𝑋 is normally distributed) with mean 𝜇 and variance 𝜎 2 𝑛 The distribution 𝑓(𝑥 ; 𝑛) of 𝑋 for samples of size n for a population with exponential distribution The distribution 𝑓(𝑥 ; 𝑛) of 𝑋 for samples of size n for population with uniform distribution In practice, the distribution for 𝑋 is well approximated by a normal distribution for n as small as 25 to 30. Practical use of the central limit theorem: You have a population whose mean 𝜇 and standard deviation 𝜎 you assume that you know (but whose density function 𝑓(𝑥) you do not know). You sample the population with a sample of size n. From the sample you compute a mean value 𝑥 . If the sample size is sufficiently large the central limit theorem will tell you the probability of getting the value 𝑥 given your assumptions on the values of 𝜇 and 𝜎. To test your assumption, compute the standardized sample mean z using the measured 𝑥 and assumed values 𝜇 and 𝜎. The central limit theorem states that the probability of getting the value 𝑥 is the same as the probability of getting the z-score z in a standard normal distribution. Theorem (Normal populations) Let 𝑋 be the mean of a random sample of size n taken from a population that is normally distributed having mean 𝜇 and variance 𝜎 2 . Then the standardized sample mean 𝑋−𝜇 𝑍≡ 𝜎 𝑛 has the standard normal distribution function regardless of the size of n. (i.e. 𝑓(𝑥 ; 𝑛) for 𝑋 is normal density with mean 𝜇 and variance 𝜎 2 /𝑛). Practical use of this theorem: You have a population whose distribution is (assumed to be) normal and whose mean 𝜇 and standard deviation 𝜎 you assume that you know. You sample the population with a sample of size n. From the sample you compute a mean value 𝑥 . This theorem will tell you the probability of getting the value 𝑥 given your assumptions on normality and the values of 𝜇 and 𝜎. To test your assumptions, compute the standardized sample mean z using the measured 𝑥 and assumed values 𝜇 and 𝜎. This theorem states that the probability of getting the value 𝑥 is the same as the probability of getting the z-score z in a standard normal distribution. e.g. 1-gallon paint cans (the population) from a particular manufacturer cover, on average 513.3 sq. ft, with a standard deviation of 31.5 sq. ft. What is the probability that the mean area covered by a sample of 40 1-gallon cans will lie within 510.0 to 520.0 sq. ft. Find the standardized sample means for the two limits of the range: 510.0 − 513.3 520.0 − 513.3 𝑧1 = = −0.66, 𝑧2 = = 1.34 31.5 40 31.5 40 Assuming the central limit theorem, we have from Table 3 𝑃 510.0 < 𝑋 < 520.0 = 𝑃 −0.66 < 𝑍 < 1.34 = 𝐹 1.34 − 𝐹 −0.66 = 0.9099 − 0.2546 = 0.6553 6.3 The Sampling Distribution of the Mean when 𝝈 is unknown (usual case) In 6.2 we discussed aspects of the distribution of the sample mean 𝑋 (it has a distribution with mean 𝜇,variance 𝜎 2 𝑛 (for continuous RVs), and the related RV 𝑋−𝜇 𝑍≡ 𝜎 𝑛 the standardized sample mean approaches the standard normal distribution as 𝑛 → ∞). In practice 𝜎 is not known and we have to deal with the values 𝑥−𝜇 𝑡≡ 𝑠 𝑛 where s is the sample standard deviation 𝑠 = 𝑠 2 , and 𝑠 2 is the sample variance 𝑛 2 𝑖=1 𝑥𝑖 − 𝑥 2 𝑠 = 𝑛−1 Similar to 𝑋, we define the random variable 𝑆 2 called the sample variance 𝑛 2 𝑖=1 𝑋𝑖 − 𝑋 2 𝑆 = 𝑛−1 2 which has values 𝑠 . In this section and the next, we are interested in the behavior of t and 𝑆 2 thought of as random variables. Little is known about the behavior of the distribution for t when n is small unless we are sampling from a population governed by the normal distribution (a “normal population”) Theorem 6.4 If 𝑋 is the sample mean for a random sample of size n taken from a normal population having mean 𝜇, then 𝑋−𝜇 𝑡≡ 𝑆 𝑛 is a random variable having the t distribution with parameter 𝑣 = 𝑛 − 1. Note: it is convention to use small ‘t’ for the RV for the t distribution (breaking the convention to use capital letters for the RV and small letters for its values). We will use small ‘t’ to stand for both the RV and its values. The t distribution: a one-parameter family of RVs, with values defined on (−∞, ∞) density function 𝑣+1 𝑣+1 − 2 2 Γ 𝑡 2 𝑓 𝑡; 𝑣 = 1 + 𝑣 𝑣 𝑣𝜋Γ 2 mean value 0 (for 𝑣 > 1), otherwise undefined variance 𝑣 𝑣−2 (for 𝑣 > 2), ∞ for 1 < 𝑣 < 2, otherwise undefined The t distribution is symmetric about 0, and very close to the standard normal distribution. In fact the t distribution → the standard normal distribution as 𝑣 → ∞. The t distribution has “heavier” tails than the standard normal distribution (i.e. there is higher probability in the tails of the t distribution). It is often referred to as “student’s t distribution” 𝑣 𝑣 𝑣 𝑣 The parameter v in the t distribution is referred to as the (number of) degrees of freedom (df) Recall that the sum of the sample deviations 𝑥𝑖 − 𝑥 is 0, hence only n ─ 1 of the deviations are independent of each other. Thus the RVs 𝑆 2 and, by the same reasoning, t both have n ─ 1 degrees of freedom. Similar to the 𝑧𝛼 for the standard normal distribution, we define the 𝑡𝛼 for the t distribution. Because of the symmetry of the standard normal and t distributions we have 𝑧1−𝛼 = −𝑧𝛼 , 𝑡1−𝛼 = −𝑡𝛼 Recall that Table 3 lists values of the cumulative standard normal distribution 𝐹(𝑧) for various values of z In contrast, Table 4 lists values of 𝑡𝛼 for various values of 𝛼 and v. (Recall, 𝛼 is the probability in the right-hand tail above 𝑡𝛼 ) By symmetry, the probability in the left-hand tail below −𝑡𝛼 is also 𝛼. Note that for 𝑛 → ∞, 𝑡𝛼 = 𝑧𝛼 The standard normal distribution provides a good approximation to the t distribution for samples of size 30 or more. Practical use of theorem 6.4: You have a population whose distribution is ( assumed to be) normal and whose mean 𝜇 you assume that you know (but whose standard deviation you do not know). You sample the population with a sample of size n. From the sample you compute a sample mean value 𝑥 and the sample standard deviation s. Theorem 6.4 will tell you the probability of getting the values 𝑥 and s given your assumptions on normality and the value of 𝜇 . To test your assumption, compute the standardized sample mean z using the measured 𝑥 and s and the assumed values 𝜇. Theorem 6.4 states that the probability of getting the value 𝑥 , s is the same as the probability of getting the value t in a t distribution with 𝑣 = 𝑛 − 1 e.g. a manufacturer’s fuses (the population) will blow in 12.40 minutes on average when subjected to a 20% overload. A sample of 20 fuses are subjected to a 20% overload. The sample average and standard deviation were observed to be, respectively, 10.63 and 2.48 minutes. What is the probability of this observation given the manufacturers claim? 𝑡= 10.63 − 12.40 = −3.19, 𝑣 = 20 − 1 = 19 2.48/ 20 From Table 4, for v = 19, we see that a t value of 2.861 already has only 0.5% probability (𝛼 = 0.005) of being exceeded. Consequently there is less than a 0.5% probability that a t value smaller than -2.861 will occur. Since the t value obtained in our sample of 20 is ─3.19, we conclude that there is less than 0.5% probability of getting this result. We therefore suspect that the manufacturers claim is incorrect, and that the manufacturers fuses will blow in less than 12.40 minutes on average when subjected to 20% overload. If the population is not normal, studies have shown that the distribution of 𝑋−𝜇 𝑆 𝑛 is fairly close to that of the t distribution as long as the population distribution is relatively bell-shaped and not too skewed. This can be checked using a normal scores plot on the population. 6.4 The Distribution of the Sample Variance 𝑺𝟐 Theorem 6.5 Consider a random sample of size n taken from a normal population having variance 𝜎 2 . Then the RV 𝑛 2 2 (𝑛 − 1)𝑆 𝑋 − 𝑋 𝑖 𝑖=1 2 ≡ = 𝜎2 𝜎2 has the chi-square distribution with parameter 𝑣 = 𝑛 − 1 The chi-square distribution: a one-parameter family of RVs, with values defined on (0, ∞) density function 𝑣 𝑣 1 −1 − 𝑓 𝑥; 𝑣 = 𝑣 𝑥2 𝑒 2 𝑣 22 Γ 2 mean value v variance 2v 𝑣 The chi-square distribution is just the gamma distribution with 𝛼 = 2 , 𝛽 = 2 Again, the parameter v is referred to as the (number of) degrees of freedom (df) We define the 2𝛼 notation similar to that of 𝑧𝛼 and 𝑡𝛼 . Just as for Table 4, Table 5 lists values of 2𝛼 for various values of 𝛼 and v. 𝑣 𝑣 𝑣 𝑣 𝑣 𝑣 e.g. (the population) glass “blanks” from an optical firm suitable for grinding into lenses Variance or refractive index of glass is 1.26 ∙ 10−4 . Random sample of size 20 selected from any shipment, and if variance of refractive index of sample exceeds 2 ∙ 10−4 , the sample is rejected. What is probability of rejection assuming underlying population is normal? For the measured sample of 20 20 − 1 2 ∙ 10−4 ≡ = 30.2 1.26 ∙ 10−4 From Table 5, for 𝑣 = 19, 30.2 corresponds to a value 𝛼 = 0.05. There is therefore a 5% probability of rejected a shipment 2 Practical use of theorem 6.5: You have a population whose distribution is ( assumed to be) normal and whose variance 𝜎 2 you assume that you know. You sample the population with a sample of size n. From the sample you compute a sample variance 𝑠 2 . Theorem 6.5 will tell you the probability of getting the value 𝑠 2 given your assumptions on normality and the value of 𝜎 2 . To test your assumption, compute the chi square value 2 using the measured 𝑠 2 and the assumed value 𝜎 2 . Theorem 6.5 states that the probability of getting the value 𝑠 2 is the same as the probability of getting the value 2 in a chi square distribution with 𝑣 = 𝑛 − 1 Recap sample space (N outcomes if finite) sample 1 n outcomes 𝑦1 … 𝑦𝑛 values for RV 𝑥1 … 𝑥𝑛 e.g. n k-dice sums sample 2 e.g. n throws each of k dice sample j Think of each 𝑥𝑖 value as resulting from a RV 𝑋𝑖 such that 1. each 𝑋𝑖 has the same density 𝑓(𝑥), mean 𝜇, and variance 𝜎 2 2. the 𝑋𝑖 are independent random sample The population of outcomes in the sample space generates values for the RVs 2 Each sample generates a sample mean 𝑥 and a sample variance 𝑠 = 𝑛 𝑖=1 𝑛−1 Think of the sample means and variances are values for the RVs 𝑋 and 𝑆 2 What are 𝐹 𝑋 , 𝐸 𝑋 , 𝑉𝑎𝑟 𝑋 , 𝐹 𝑆 2 , 𝐸 𝑆 2 , 𝑉𝑎𝑟 𝑆 2 ? Chapter 5 states: 𝐸 𝑋 = 𝜇, 𝐸 𝑋 = 𝜇, 𝑉𝑎𝑟 𝑋 = 𝜎 2 /𝑛 for an infinite population 𝑉𝑎𝑟 𝑋 = 𝜎 2 𝑁−𝑛 𝑛 𝑁−1 for an infinite population Chapter 6 addresses the questions on 𝐹 𝑋 , 𝐹 𝑆 2 Law of large numbers for a single sample (and single value of 𝑋) 𝜎2 𝑃 𝑋−𝜇 >𝜖 < 2 𝑛𝜖 Central limit theorem 𝑋−𝜇 𝑍≡ 𝜎 𝑛 is a RV whose distribution 𝐹 𝑍 → standard normal 𝑁(0,1) as 𝑛 → ∞ (i.e. 𝑋 is a RV whosedistribution 𝐹 𝑋 → 𝑁(𝜇, 𝜎) as 𝑛 → ∞) 𝑥𝑖 −𝑥 2 If the 𝑿𝒊 are normally distributed with mean 𝜇 and variance 𝜎 2 𝑋−𝜇 𝑍≡ 𝜎 𝑛 is a RV whose distribution 𝐹 𝑍 = 𝑁(0,1) for all n i.e. 𝑋 is a RV whose distribution 𝐹 𝑋 = 𝑁(𝜇, 𝜎) for all n If the 𝑿𝒊 are normally distributed with mean 𝜇 𝑋−𝜇 𝑡≡ 𝑆 𝑛 is a RV whose distribution 𝐹 𝑡 is the t-distribution with df 𝑣 = 𝑛 − 1 If the 𝑿𝒊 are normally distributed with variance 𝜎 2 𝑛 2 2 (𝑛 − 1)𝑆 𝑋 − 𝑋 𝑖 𝑖=1 2 ≡ = 𝜎2 𝜎2 is a RV whose distribution 𝐹 2 is the chi−square distribution with df 𝑣 = 𝑛 − 1 Assume we have two populations. We may wish to inquire whether they have the same variance. Assume 𝑆12 and 𝑆22 are measured sample variances for each population. Theorem 6.6 If 𝑆12 and 𝑆22 are measured sample variances of independent random samples of respective sizes 𝑛1 and 𝑛2 taken from two normal populations having the same variance then 𝑆12 𝐹= 2 𝑆2 is a RV having the F distribution with parameters 𝑣1 = 𝑛1 − 1 and 𝑣2 = 𝑛2 − 1. The F distribution: a two-parameter family of RVs, with values defined on (0, ∞) density function 𝑓 𝑥; 𝑣1 , 𝑣2 = mean value variance 𝑣2 𝑣2 −2 1 𝑣1 𝑣2 𝑣 𝑣 𝐵 21 , 22 𝑣1 2 𝑣1 𝑥 2 −1 𝑣1 1+ 𝑥 𝑣2 𝑣 +𝑣 − 12 2 for 𝑣2 > 2 2𝑣22 (𝑣1 +𝑣2 −2) 𝑣1 𝑣2 −2 2 (𝑣2 −4) for 𝑣2 > 4 The F distribution is similar to the beta distribution. 𝐵 1 𝐵 𝑥, 𝑦 = 0 𝑡 𝑥−1 1 − 𝑡 𝑣1 𝑣2 , 2 2 𝑦−1 𝑑𝑡 is the beta function F distribution 𝑣1 𝑣1 𝑣1 𝑣1 𝑣1 𝑣2 𝑣2 𝑣2 𝑣2 𝑣2 The parameter 𝑣1 is referred to as the numerator degrees of freedom (df of nunerator) The parameter 𝑣2 is referred to as the denominator degrees of freedom (df of denominator) As with 𝑧𝛼 , 𝑡𝛼 , etc we define 𝐹𝛼 . Values of 𝐹𝛼 are given in Table 6 for various values of 𝑣1 and 𝑣2 for 𝛼 = 0.05 (Table 6(a)) and 𝛼 = 0.01(Table 6(b)) Practical use of theorem 6.6: You have two population whose distribution are ( assumed to be) normal and whose variances you assume to be equal. You sample population 1 with a sample of size 𝑛1 and population 2 with a sample of size 𝑛2 . From each sample you compute sample variances 𝑠12 and 𝑠22 . Theorem 6.6 will tell you the probability of getting the ratio 𝑠12 𝑠22 given your assumptions on normality and equality of variance. To test your assumption, compute the value F. Theorem 6.6 states that the probability of getting the ratio 𝑠12 𝑠22 is the same as the probability of getting the value F in an F distribution with 𝑣1 = 𝑛1 − 1, 𝑣2 = 𝑛2 − 1. e.g. Two random samples of size 𝑛1 = 7 and 𝑛2 = 13 are taken from the same normal population. What is the probability that the variance of the first sample will be at least 3 times that of the second. For 𝑣1 = 6 and 𝑣2 = 12, Table 6(a) shows an F value of 3.00 for 𝛼 = 0.05. Therefore there is a 5% probability that the variance of the first sample will be at least 3 times that of the second. 6.5 Representations of normal distributions Defining new random variables in terms of others is referred to as a representation chi-square Let 𝑍1 , 𝑍2 , … , 𝑍𝑣 be independent standard normal RVs. Define the RV 𝑣 𝑍𝑖2 2𝑣 = 𝑖=1 Then 2𝑣 has a chi square distribution with v df Thus we also see that the square of a standard normal RV is a chi-square RV Let 𝑣1 𝑣1 +𝑣2 𝑍𝑖2 and 22 = 12 = 𝑖=1 𝑍𝑖2 𝑖=𝑣1 +1 where the 𝑍𝑖 are independent standard normal RVs (and thus 12 and 22 are independent of each other). Then 12 + 22 has a chi square distribution with 𝑣1 + 𝑣2 df. Thus we see that the sum of two independent chi square RVs is also a chi square RV with the sum of the individual df t distribution Let 𝑍 be a standard normal RV and 2 be a chi-square RV with v df. Assume 𝑍 and 2 are independent. Then 𝑍 𝑡≡ 2 𝑣 has a t distribution with 𝑣 df F distribution Let 12 and 22 be chi-square RVs with df 𝑣1 and 𝑣2 respectively. Assume 12 and 22 are independent. Then 12 𝑣1 𝐹𝑣1,𝑣2 ≡ 2 2 𝑣2 has an F distribution with 𝑣1 , 𝑣2 df Thus we see that 𝑡2 is a RV with an 𝑭𝟏,𝒗 distribution 𝑍2 1 ≡ 2 𝑣 e.g. Let 𝑋1 , 𝑋2 , … , 𝑋𝑛 be n independent normal RVs all having mean 𝜇 and standard deviation 𝜎. Then 𝑋𝑖 − 𝜇 𝑍𝑖 = 𝜎 is a standard normal RV for each i. Then 1 𝑛𝑍 ≡ 𝑛 𝑛 𝑛 𝑖=1 1 𝑍𝑖 = 𝑛 𝑛 is also a standard normal RV. Consider 𝑛 𝑛 𝑍𝑖 − 𝑍 𝑖=1 i.e. 2 𝑛 𝑖=1 𝑛 𝑍𝑖2 − 2𝑍 = 𝑖=1 𝑛 𝑛 𝑍𝑖2 − 𝑛𝑍 2 𝑍𝑖 + 𝑛𝑍 2 = 𝑖=1 𝑖=1 𝑛 𝑍𝑖2 = 𝑖=1 𝑋𝑖 − 𝜇 𝑋−𝜇 = 𝜎 𝜎/ 𝑛 𝑍𝑖 − 𝑍 2 + 𝑛𝑍 2 𝑖=1 Note that the LHS is chi square distribution with 𝑛df. The last term on the RHS is chi square with 1 df. This implies that the first term on the RHS is chi-square with 𝑛 − 1df. Thus we see that 𝑛 𝑛 2 (𝑛 − 1)𝑆 2 𝑋 − 𝑋 𝑖=1 𝑖 = = 𝑍𝑖 − 𝑍 2 2 2 𝜎 𝜎 𝑖=1 has a chi square distribution with 𝑛 − 1df (as claimed in Theorem 6.5) Let 𝑋𝑖 be 𝑁(𝜇𝑖 , 𝜎𝑖2 ) for 𝑖 = 1, … , 𝑛 be n independent normal RVs Then 𝑛 𝑋= 𝑋𝑖 𝑖=1 is normal with 𝑛 𝐸𝑋 = 𝑛 𝑢𝑖 , 𝜎𝑖2 𝑉𝑎𝑟 𝑋 = 𝑖=1 𝑖=1 A sum of normal RVs is a normal RV Let 𝑋𝑖 be a chi-square RV with df= 𝑣𝑖 for 𝑖 = 1, … , 𝑛 ; assume the 𝑋𝑖 are independent Then 𝑛 𝑋= 𝑋𝑖 𝑖=1 is a chi-square RV with df 𝑛 𝑣= v𝑖 𝑖=1 A sum of chi-square RVs is chi-square Let 𝑋𝑖 be a Poisson RV with parameter λ𝑖 for 𝑖 = 1, … , 𝑛 ; assume the 𝑋𝑖 are independent Then 𝑛 𝑋= 𝑋𝑖 𝑖=1 is a Poisson RV with parameter 𝑛 λ= λ𝑖 𝑖=1 A sum of Poisson RVs is Poisson







































![z[i]=mean(sample(c(0:9),10,replace=T))](http://s1.studyres.com/store/data/008530004_1-3344053a8298b21c308045f6d361efc1-150x150.png)





