Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Serializability wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Concurrency control wikipedia , lookup
Relational model wikipedia , lookup
Functional Database Model wikipedia , lookup
Clusterpoint wikipedia , lookup
Topic 4: Data Mining I
Data mining (knowledge discovery in databases):
Extraction of interesting (non-trivial, implicit,
previously unknown and potentially useful)
information or patterns from data in large databases
Why Data Mining?
The data explosion problem: Automated data
collection tools and mature database technology
lead to tremendous amounts of data stored in
databases, data warehouses and other information
repositories; We are drowning in data, but starving
for knowledge!
Dr. N. Mamoulis
Advanced Database Technologies
1
Data Mining Applications
Database analysis and decision support
Market analysis and management
target marketing, customer relation management, market basket
analysis, cross selling, market segmentation
Risk analysis and management
Forecasting, customer retention, improved underwriting, quality
control, competitive analysis
Fraud detection and management
Other Applications
Text mining (news group, email, documents) and Web analysis.
Intelligent query answering (do you want to know more? do you
want to see similar results? are you also interested in this?)
Dr. N. Mamoulis
Advanced Database Technologies
2
Data Mining Applications
Database analysis and decision support
Market analysis and management
target marketing, customer relation management, market basket
analysis, cross selling, market segmentation
Risk analysis and management
Forecasting, customer retention, improved underwriting, quality
control, competitive analysis
Fraud detection and management
Other Applications
Text mining (news group, email, documents) and Web analysis.
Intelligent query answering (do you want to know more? do you
want to see similar results? are you also interested in this?)
Dr. N. Mamoulis
Advanced Database Technologies
3
Market Analysis and Management (1)
Where are the data sources for analysis?
Credit card transactions, loyalty cards, discount coupons,
customer complaint calls, plus (public) lifestyle studies
Target marketing
Find clusters of “model” customers who share the same
characteristics: interest, income level, spending habits, etc.
Determine customer purchasing patterns over time
Conversion of single to a joint bank account: marriage, etc.
Cross-market analysis
Associations/co-relations between product sales
Prediction based on the association information
Dr. N. Mamoulis
Advanced Database Technologies
4
Market Analysis and Management (2)
Customer profiling
data mining can tell you what types of customers buy what
products (clustering or classification)
Identifying customer requirements
identifying the best products for different customers
use prediction to find what factors will attract new customers
Provides summary information
various multidimensional summary reports
statistical summary information (data central tendency and
variation)
Dr. N. Mamoulis
Advanced Database Technologies
5
Corporate Analysis and Risk Management
Finance planning and asset evaluation
cash flow analysis and prediction
contingent claim analysis to evaluate assets
cross-sectional and time series analysis (financial-ratio, trend
analysis, etc.)
Resource planning:
summarize and compare the resources and spending
Competition:
monitor competitors and market directions
group customers into classes and a class-based pricing
procedure
set pricing strategy in a highly competitive market
Dr. N. Mamoulis
Advanced Database Technologies
6
Fraud Detection and Management (1)
Applications
widely used in health care, retail, credit card services,
telecommunications (phone card fraud), etc.
Approach
use historical data to build models of fraudulent behavior and
use data mining to help identify similar instances
Examples
auto insurance: detect a group of people who stage accidents to
collect on insurance
money laundering: detect suspicious money transactions (US
Treasury's Financial Crimes Enforcement Network)
medical insurance: detect professional patients and ring of
doctors and ring of references
Dr. N. Mamoulis
Advanced Database Technologies
7
Fraud Detection and Management (2)
Detecting inappropriate medical treatment
Australian Health Insurance Commission identifies that in many
cases blanket screening tests were requested (save Australian
$1m/yr).
Detecting telephone fraud
Telephone call model: destination of the call, duration, time of
day or week. Analyze patterns that deviate from an expected
norm.
British Telecom identified discrete groups of callers with frequent
intra-group calls, especially mobile phones, and broke a
multimillion dollar fraud.
Retail
Analysts estimate that 38% of retail shrink is due to dishonest
employees.
Dr. N. Mamoulis
Advanced Database Technologies
8
Other Applications
Sports
IBM Advanced Scout analyzed NBA game statistics (shots
blocked, assists, and fouls) to gain competitive advantage for
New York Knicks and Miami Heat
Astronomy
JPL and the Palomar Observatory discovered 22 quasars with
the help of data mining
Internet Web Surf-Aid
IBM Surf-Aid applies data mining algorithms to Web access logs
for market-related pages to discover customer preference and
behavior pages, analyzing effectiveness of Web marketing,
improving Web site organization, etc.
Dr. N. Mamoulis
Advanced Database Technologies
9
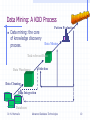
Data Mining: A KDD Process
Data mining: the core
of knowledge discovery
process.
Pattern Evaluation
Data Mining
Task-relevant Data
Selection
Data Warehouse
Data Cleaning
Data Integration
Databases
Dr. N. Mamoulis
Advanced Database Technologies
10
Steps of a KDD Process
Learning the application domain:
relevant prior knowledge and goals of application
Creating a target data set: data selection
Data cleaning and preprocessing: (may take 60% of effort!)
Data reduction and transformation:
Find useful features, dimensionality/variable reduction, invariant
representation.
Choosing functions of data mining
summarization, classification, regression, association, clustering.
Choosing the mining algorithm(s)
Data mining: search for patterns of interest
Pattern evaluation and knowledge presentation
visualization, transformation, removing redundant patterns, etc.
Use of discovered knowledge
Dr. N. Mamoulis
Advanced Database Technologies
11
Why Data Preprocessing?
Data in the real world is dirty
incomplete: lacking attribute values, lacking certain attributes of
interest, or containing only aggregate data
noisy: containing errors or outliers
inconsistent: containing discrepancies in codes or names
No quality data, no quality mining results!
Quality decisions must be based on quality data
Data warehouse needs consistent integration of quality data
Dr. N. Mamoulis
Advanced Database Technologies
12
Major Tasks in Data Preprocessing
Data cleaning
Fill in missing values, smooth noisy data, identify or remove outliers,
and resolve inconsistencies
Data integration
Integration of multiple databases, data cubes, or files
Data transformation
Normalization and aggregation
Data reduction
Obtains reduced representation in volume but produces the same or
similar analytical results
Data discretization
Part of data reduction but with particular importance, especially for
numerical data
Dr. N. Mamoulis
Advanced Database Technologies
13
Data Cleaning
Data cleaning tasks
Fill in missing values
Identify outliers and smooth out noisy data
Correct inconsistent data
Age Income
Religion
Gender
23
24,200
Muslim
M
39
?
Christian F
45
45,390
?
F
Fill missing values using aggregate functions (e.g., average) or
probabilistic estimates on global value distribution
Dr. N. Mamoulis
Advanced Database Technologies
14
Data Integration
Data integration:
combines data from multiple sources into a coherent store
Schema integration
integrate metadata from different sources
Entity identification problem: identify real world entities from
multiple data sources, e.g., A.cust-id B.cust-#
Detecting and resolving data value conflicts
for the same real world entity, attribute values from different
sources are different
possible reasons: different representations, different scales,
e.g., metric vs. British units
Dr. N. Mamoulis
Advanced Database Technologies
15
Data Integration Example
Data source 2
Data source 1
Emp-id Age
Income
Gender
ekey
age
salary
gender
10002
23
24,200
M
30004
43
60,234
M
10003
39
32,000
F
30020
23
47,000
F
10004
45
40,000
F
30025
56
93,030
M
Integrated Data
1. Integrate
attribute names
Dr. N. Mamoulis
Emp-id Age
Income
Gender
10002
23
36,300
M
10003
39
46,000
F
10004
45
60,000
F
30004
43
60,234
M
30020
23
47,000
F
30025
56
93,030
M
Advanced Database Technologies
2. Covert data types
1 GBP = 1.5 USD
16
Data Transformation
Smoothing: remove noise from data
Aggregation: summarization, data cube construction
Generalization: concept hierarchy climbing
Normalization: scaled to fall within a small, specified
range
min-max normalization
z-score normalization
normalization by decimal scaling
Attribute/feature construction
New attributes constructed from the given ones
Dr. N. Mamoulis
Advanced Database Technologies
17
Data Reduction Strategies
Warehouse may store terabytes of data: Complex data
analysis/mining may take a very long time to run on the
complete data set
Data reduction
Obtains a reduced representation of the data set that is much
smaller in volume but yet produces the same (or almost the
same) analytical results
Data reduction strategies
Data cube aggregation (reduce to summary data)
Dimensionality reduction (as in multimedia data)
Numerosity reduction (model data using functions or
summarize them using histograms)
Dr. N. Mamoulis
Advanced Database Technologies
18
Discretization and Concept Hierarchy
Discretization
reduce the number of values for a given continuous attribute
by dividing the range of the attribute into intervals. Interval
labels can then be used to replace actual data values.
E.g., ages 0-10 1, ages 11-20 2, etc.
Concept hierarchies
reduce the data by collecting and replacing low level concepts
(such as numeric values for the attribute age) by higher level
concepts (such as young, middle-aged, or senior).
E.g., ages 0-12 child, ages 13-20 teenager, etc.
Dr. N. Mamoulis
Advanced Database Technologies
19
Summary of the KDD process
All steps of the KDD process are important and crucial
for the effectiveness of discovery.
Data mining is the most interesting one due to the
challenge of automatic discovery of interesting
information
Next, we will present some data mining techniques
focusing on discovery of association rules and discovery
of frequent patterns in long sequences
Dr. N. Mamoulis
Advanced Database Technologies
20
Mining Association Rules
Association rule mining:
Finding frequent patterns, associations, correlations, or
causal structures among sets of items or objects in
transaction databases, relational databases, and other
information repositories.
Applications:
Basket data analysis, cross-marketing, catalog design, lossleader analysis, clustering, classification, etc.
Examples.
Rule form: “Body Head [support, confidence]”.
buys(x, “diapers”) buys(x, “beers”) [0.5%, 60%]
major(x, “CS”) takes(x, “DB”) grade(x, “A”) [1%, 75%]
Dr. N. Mamoulis
Advanced Database Technologies
21
Association Rule: Basic Concepts
Given: (1) database of transactions, (2) each transaction
is a list of items (purchased by a customer in a visit)
Find: all rules that correlate the presence of one set of
items with that of another set of items
E.g., 98% of people who purchase tires and auto accessories also
get automotive services done
Applications
* Maintenance Agreement (What the store should do to
boost Maintenance Agreement sales)
Home Electronics * (What other products should the store
stocks up?)
Attached mailing in direct marketing
Detecting “ping-pong”ing of patients, faulty “collisions”
Dr. N. Mamoulis
Advanced Database Technologies
22
Formal Definition
Given
A (potentially unknown) set of literals I={i1, i2, …,in}, called
items,
A set of transactions D, where each transaction T D is a
subset of I, i.e., T I,
A support threshold s, 0<s≤1 and
A confidence threshold c, 0<c≤1
Find
All rules of the form X Y, where X I, Y I, X Y =
and (i) at least s% of the transactions in D contain X Y, (ii)
at least c% of the transactions in D which contain X, also
contain Y.
Dr. N. Mamoulis
Advanced Database Technologies
23
General Procedure for Mining Association
Rules
Find all frequent itemsets F, where for each Z F, at
least s% of the transactions in D contain Z.
Generate association rules from F as follows. Let X
Y F and X F. Then conf(XY) = supp(X)/supp(X
Y). If conf(XY) c then rule XY is generated,
because:
supp(XY) = supp(X Y) s and
conf(XY) c
Therefore mining association rules reduces to mining
frequent itemsets and correlations between them.
Dr. N. Mamoulis
Advanced Database Technologies
24
Finding Frequent Itemsets – The Apriori
algorithm
The most important part of the mining process is to find
all itemsets with minimum support s in the database D.
Apriori is an influential algorithm for this task
It is based on the following observation: an itemset l =
{i1,i2,…,in} can be frequent, only if all subsets of l are
frequent. In other words, supp(l)s only if supp(l’ )s,
l’’l.
Thus the frequent itemsets are found in a level-wise
manner. First freq. itemsets L1 with only 1 item are found.
Then candidate itemsets C2 of size 2 are generated from
them and verified, and so on.
Dr. N. Mamoulis
Advanced Database Technologies
25
The Apriori Algorithm
Join Step: Ck is generated by joining Lk-1with itself
Prune Step: Any (k-1)-itemset that is not frequent cannot be
a subset of a frequent k-itemset
Pseudo-code:
Ck: Candidate itemset of size k
Lk : frequent itemset of size k
L1 = {frequent items};
for (k = 1; Lk !=; k++) do begin
Ck+1 = candidates generated from Lk;
for each transaction t in database do
increment the count of all candidates in Ck+1
that are contained in t
Lk+1 = candidates in Ck+1 with min_support
end
return k Lk;
Dr. N. Mamoulis
Advanced Database Technologies
26
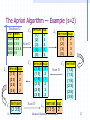
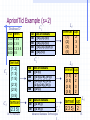
The Apriori Algorithm — Example (s=2)
Database D
TID
100
200
300
400
C1
itemset sup.
Items
{1}
2
134
{2}
3
235
Scan D
{3}
3
1235
{4}
1
25
{5}
3
C2
L2 itemset sup
{1 3}
{2 3}
{2 5}
{3 5}
2
2
3
2
C3 itemset
{2 3 5}
Dr. N. Mamoulis
itemset sup
{1 2}
1
{1 3}
2
{1 5}
1
{2 3}
2
{2 5}
3
{3 5}
2
Scan D
L1
itemset sup.
{1}
2
{2}
3
{3}
3
{5}
3
C2 itemset
Scan D
L3 itemset sup
{2 3 5} 2
Advanced Database Technologies
{1
{1
{1
{2
{2
{3
2}
3}
5}
3}
5}
5}
27
How to Generate Candidates?
Suppose the items in Lk-1 are listed in an order
Step 1: self-joining Lk-1
insert into Ck
select p.item1, p.item2, …, p.itemk-1, q.itemk-1
from Lk-1 p, Lk-1 q
where p.item1=q.item1, …, p.itemk-2=q.itemk-2, p.itemk-1 < q.itemk-1
Step 2: pruning
forall itemsets c in Ck do
forall (k-1)-subsets s of c do
if (s is not in Lk-1) then delete c from Ck
Dr. N. Mamoulis
Advanced Database Technologies
28
Example of Generating Candidates
L3={abc, abd, acd, ace, bcd}
Self-joining: L3*L3
abcd from abc and abd
{a,c,e}
{a,c,d,e}
X
acde from acd and ace
acd ace ade cde
X
Pruning:
{a,c,d}
acde is removed because ade is not in L3
C4={abcd}
Dr. N. Mamoulis
Advanced Database Technologies
29
How to Count Supports of Candidates?
Why counting supports of candidates a problem?
The total number of candidates can be huge
One transaction may contain many candidates
Method:
Candidate itemsets are stored in a hash-tree
Leaf node of hash-tree contains a list of itemsets and counts
Interior node contains a hash table
Subset function: finds all the candidates contained in a
transaction
Dr. N. Mamoulis
Advanced Database Technologies
30
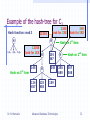
Example of the hash-tree for C3
Hash function: mod 3
H
H
1,4,.. 2,5,.. 3,6,..
Hash on 3rd item
Dr. N. Mamoulis
H
145
H
124
457
125
458
234
567
345
Hash on 1st item
H
356
689
Hash on 2nd item
367
368
159
Advanced Database Technologies
31
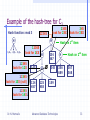
Example of the hash-tree for C3
Hash function: mod 3
12345
H
1,4,.. 2,5,.. 3,6,..
H
12345
look for 1XX H
Hash on 3rd item
Dr. N. Mamoulis
2345
look for 2XX
145
H
124
457
125
458
234
567
345
345
look for 3XX
Hash on 1st item
H
356
689
Hash on 2nd item
367
368
159
Advanced Database Technologies
32
Example of the hash-tree for C3
Hash function: mod 3
12345
H
1,4,.. 2,5,.. 3,6,..
H
12345
look for 1XX H
12345
look for 12X
12345
look for 13X (null)
12345
look for 14X
Dr. N. Mamoulis
2345
look for 2XX
145
H
124
457
125
458
234
567
345
345
look for 3XX
Hash on 1st item
H
356
689
Hash on 2nd item
367
368
159
Advanced Database Technologies
33
AprioriTid: Use D only for first pass
The database is not used after the 1st pass.
Instead, the set Ck’ is used for each step, Ck’ =
<TID, {Xk}> : each Xk is a potentially frequent
itemset in transaction with id=TID.
At each step Ck’ is generated from Ck-1’ at the
pruning step of constructing Ck and used to
compute Lk.
For small values of k, Ck’ could be larger than
the database!
Dr. N. Mamoulis
Advanced Database Technologies
34
AprioriTid Example (s=2)
Database D
TID
100
200
300
400
Items
134
235
1235
25
itemset
{1 2}
C2 {1 3}
{1 5}
{2 3}
{2 5}
{3 5}
C3 itemset
{2 3 5}
Dr. N. Mamoulis
L1
C1’
TID
100
200
Sets of itemsets
{{1},{2},{4}}
{{2},{3},{5}}
300
{{1},{2},{3},{5}}
400
{{2},{5}}
itemset sup.
{1}
2
{2}
3
{3}
3
{5}
3
C1’
TID
100
200
Sets of itemsets
{{1 3}}
{{2 3},{2 5},{3 5}}
300
400
{{1 2},{1 3},{1 5},
{2 3},{2 5},{3 5}}
{{2 5}}
TID
200
Sets of itemsets
{{2 3 5}}
300
{{2 3 5}}
L2
itemset
{1 3}
{2 3}
{2 5}
{3 5}
C3’
Advanced Database Technologies
sup
2
2
3
2
itemset sup
{2 3 5} 2
L3
35
Experiments with Apriori, AprioryTid
Experiments show that Apriori is faster than
AprioriTid, in general.
This is because the Ck’ generated during the
early phases of AprioriTid are very large.
An AprioriHybrid method is proposed that uses
Apriori in the early phases and AprioriTid in the
latter phases.
Dr. N. Mamoulis
Advanced Database Technologies
36
Methods to Improve Apriori’s Efficiency
Hash-based itemset counting: A k-itemset whose corresponding
hashing bucket count is below the threshold cannot be frequent
Transaction reduction: A transaction that does not contain any
frequent k-itemset is useless in subsequent scans
Partitioning: Any itemset that is potentially frequent in DB must be
frequent in at least one of the partitions of DB
Sampling: mining on a subset of given data, lower support
threshold + a method to determine the completeness
Dynamic itemset counting: add new candidate itemsets only when
all of their subsets are estimated to be frequent
Dr. N. Mamoulis
Advanced Database Technologies
37
Is Apriori Fast Enough? — Performance
Bottlenecks
The core of the Apriori algorithm:
Use frequent (k – 1)-itemsets to generate candidate frequent kitemsets
Use database scan and pattern matching to collect counts for the
candidate itemsets
The bottleneck of Apriori: candidate generation
Huge candidate sets:
104 frequent 1-itemset will generate 107 candidate 2-itemsets
To discover a frequent pattern of size 100, e.g., {a1, a2, …,
a100}, one needs to generate 2100 1030 candidates.
Multiple scans of database:
Needs (n +1 ) scans, n is the length of the longest pattern
Dr. N. Mamoulis
Advanced Database Technologies
38
Mining Frequent Patterns Without
Candidate Generation
Compress a large database into a compact, FrequentPattern tree (FP-tree) structure
highly condensed, but complete for frequent pattern mining
avoid costly database scans
Develop an efficient, FP-tree-based frequent pattern
mining method
A divide-and-conquer methodology: decompose mining tasks into
smaller ones
Avoid candidate generation: sub-database test only!
Dr. N. Mamoulis
Advanced Database Technologies
39
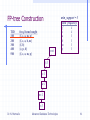
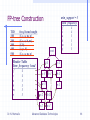
FP-tree Construction
TID
100
200
300
400
500
Items bought
(ordered) frequent items
{f, a, c, d, g, i, m, p}
{f, c, a, m, p}
{a, b, c, f, l, m, o}
{f, c, a, b, m}
{b, f, h, j, o}
{f, b}
{b, c, k, s, p}
{c, b, p}
{a, f, c, e, l, p, m, n}
{f, c, a, m, p}
Steps:
min_support = 3
Item frequency
f
4
c
4
a
3
b
3
m
3
p
3
1. Scan DB once, find frequent 1-itemset
(single item pattern)
2. Order frequent items in frequency
descending order
3. Scan DB again, construct FP-tree
Dr. N. Mamoulis
Advanced Database Technologies
40
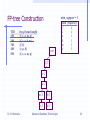
FP-tree Construction
TID
100
200
300
400
500
min_support = 3
freq. Items bought
{f, c, a, m, p}
{f, c, a, b, m}
{f, b}
{c, p, b}
{f, c, a, m, p}
root
Item frequency
f
4
c
4
a
3
b
3
m
3
p
3
f:1
c:1
a:1
m:1
p:1
Dr. N. Mamoulis
Advanced Database Technologies
41
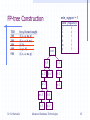
FP-tree Construction
TID
100
200
300
400
500
min_support = 3
freq. Items bought
{f, c, a, m, p}
{f, c, a, b, m}
{f, b}
{c, p, b}
{f, c, a, m, p}
root
Item frequency
f
4
c
4
a
3
b
3
m
3
p
3
f:2
c:2
a:2
Dr. N. Mamoulis
m:1
b:1
p:1
m:1
Advanced Database Technologies
42
FP-tree Construction
TID
100
200
300
400
500
min_support = 3
freq. Items bought
{f, c, a, m, p}
{f, c, a, b, m}
{f, b}
{c, p, b}
{f, c, a, m, p}
root
f:3
c:2
c:1
b:1
a:2
Dr. N. Mamoulis
Item frequency
f
4
c
4
a
3
b
3
m
3
p
3
b:1
p:1
m:1
b:1
p:1
m:1
Advanced Database Technologies
43
FP-tree Construction
TID
100
200
300
400
500
min_support = 3
freq. Items bought
{f, c, a, m, p}
{f, c, a, b, m}
{f, b}
{c, p, b}
{f, c, a, m, p}
Header Table
Item frequency head
f
4
c
4
a
3
b
3
m
3
p
3
Dr. N. Mamoulis
Item frequency
f
4
c
4
a
3
b
3
m
3
p
3
root
f:4
c:3
c:1
b:1
a:3
b:1
p:1
m:2
b:1
p:2
m:1
Advanced Database Technologies
44
Benefits of the FP-tree Structure
Completeness:
never breaks a long pattern of any transaction
preserves complete information for frequent pattern
mining
Compactness
reduce irrelevant information—infrequent items are
gone
frequency descending ordering: more frequent
items are more likely to be shared
never be larger than the original database (if not
count node-links and counts)
Example: For Connect-4 DB, compression ratio could
be over 100
Dr. N. Mamoulis
Advanced Database Technologies
45
Mining Frequent Patterns Using the FP-tree
General idea (divide-and-conquer)
Recursively grow frequent pattern path using the FPtree
Method
For each item, construct its conditional pattern-base,
and then its conditional FP-tree
Repeat the process on each newly created conditional
FP-tree
Until the resulting FP-tree is empty, or it contains only
one path (single path will generate all the combinations of its
sub-paths, each of which is a frequent pattern)
Dr. N. Mamoulis
Advanced Database Technologies
46
Mining Frequent Patterns Using the FP-tree
(cont’d)
Start with last item in order (i.e., p).
Follow node pointers and traverse only the paths containing p.
Accumulate all of transformed prefix paths of that item to form a
conditional pattern base
f:4
p
c:3
b:1
a:3
p:1
m:2
p:2
Dr. N. Mamoulis
c:1
Conditional pattern base for p
fcam:2, cb:1
Constructing a new FPtree based on this
pattern base leads to
only one branch c:3
Thus we derive only
one frequent pattern
cont. p. Pattern cp
Advanced Database Technologies
47
Mining Frequent Patterns Using the FP-tree
(cont’d)
Move to next least frequent item in order, i.e., m
Follow node pointers and traverse only the paths containing m.
Accumulate all of transformed prefix paths of that item to form a
conditional pattern base
f:4
Conditional pattern base for m
c:3
m
fca:2, fcab:1
a:3
m:2
b:1
m:1
Dr. N. Mamoulis
Constructing a new FP-tree
based on this pattern base
leads to path fca:3
From this we derive frequent
patterns fcam, fcm, cam, fm,
cm, am
Advanced Database Technologies
48
Properties of FP-tree for Conditional
Pattern Base Construction
Node-link property
For any frequent item ai, all the possible frequent
patterns that contain ai can be obtained by following ai's
node-links, starting from ai's head in the FP-tree header
Prefix path property
To calculate the frequent patterns for a node ai in a path
P, only the prefix sub-path of ai in P need to be
accumulated, and its frequency count should carry the
same count as node ai.
Dr. N. Mamoulis
Advanced Database Technologies
49
Conditional Pattern-Bases for the example
Item Conditional pattern-base Conditional FP-tree
p
{(fcam:2), (cb:1)}
{(c:3)}|p
m
{(fca:2), (fcab:1)}
{(f:3, c:3, a:3)}|m
b
{(fca:1), (f:1), (c:1)}
Empty
a
{(fc:3)}
{(f:3, c:3)}|a
c
{(f:3)}
{(f:3)}|c
f
Empty
Empty
Dr. N. Mamoulis
Advanced Database Technologies
50
Why Is Frequent Pattern Growth Fast?
Performance studies show that
FP-growth is an order of magnitude faster than
Apriori, and is also faster than tree-projection
Reasoning
No candidate generation, no candidate test
Use compact data structure
Eliminate repeated database scan
Basic operation is counting and FP-tree building
Dr. N. Mamoulis
Advanced Database Technologies
51
FP-growth vs. Apriori: Scalability With
the Support Threshold
Data set T25I20D10K
100
D1 FP-grow th runtime
90
D1 Apriori runtime
80
Run time(sec.)
70
60
50
40
30
20
10
0
0
Dr. N. Mamoulis
0.5
1
1.5
2
Support threshold(%)
Advanced Database Technologies
2.5
3
52
FP-growth vs. Tree-Projection: Scalability
with Support Threshold
Data set T25I20D100K
140
D2 FP-growth
Runtime (sec.)
120
D2 TreeProjection
100
80
60
40
20
0
0
Dr. N. Mamoulis
0.5
1
Support
threshold
(%)
Advanced
Database
Technologies
1.5
2
53
Additional issues on the FP-tree
How to use this method for large databases?
Partition the database cleverly and build one FP-tree for each partition
Make the FP-tree disk resident (like the B+-tree). However, node link
traversal and accessing of paths may cause many random I/Os
Materialize the FP-tree
No need to build it for each query. However, the construction is based
on predefined minimum support threshold.
Incremental Updates on the Tree
Useful for incremental updates of association rules. However, it is only
possible when the minimum support is 1. Another solution is to adjust
the minimum support with the update of the database.
Dr. N. Mamoulis
Advanced Database Technologies
54
Finding Frequent Episodes in Event
Sequences
Problem definition:
Given a sequence of events in time, and a time window
win find all episodes that appear frequently in all
windows of size win in the sequence
An episode is defined as an serial or parallel cooccurrence of event types.
The problem is similar to mining frequent itemsets in a
database of transactions, but the different type of data
make it special.
Dr. N. Mamoulis
Advanced Database Technologies
55
Finding Frequent Episodes in Event
Sequences: An example
A C ED B C F
BA A
C D EA A C
D CE A C F D A B
w1
w2
w3
w4
time
The frequency of an episode α is defined by the number of windows where
α appears divided by the total number of time windows:
| {w W ( S , win) | w} |
fr( , S , win)
| W ( S , win) |
For example, the episode (C appears after A) is very frequent in the above
sequence
Dr. N. Mamoulis
Advanced Database Technologies
56
Types of episodes
Serial episode: F appears after E
E
F
Parallel episode: A appears with
B in any order
A
Hybrid serial-parallel episode:
B
there is no total order in the
appearance of the elements, but
there is a partial order
Dr. N. Mamoulis
Advanced Database Technologies
A
F
B
57
Main Algorithm
Like Apriori
First find frequent events (e.g., A,B,C)
Generate candidate episodes for next level
(e.g., AB, AC, BC). Prune candidates for which a
sub-episode is not freq. in the previous level.
Count the frequencies of candidates and find
frequent episodes.
Apply iteratively for next-level episodes.
Dr. N. Mamoulis
Advanced Database Technologies
58
Counting frequencies of candidates
This is the main difference; the rest is like
Apriori in transactional data
Observation: Consecutive windows contain
similar events:
A C ED B C F
BA A
C D EA A C
D CE A C F D A B
w1
w2
w3
w4
time
We do not have to count the episodes in
each window
Dr. N. Mamoulis
Advanced Database Technologies
59
Counting frequencies of candidates (cont’d)
A C ED B C F
w1
BA A
C D EA A C
D CE A C F D A B
w2
time
While sliding the window we update the
frequencies of episodes considering only the
new events which enter the window and the
events which are no longer in the window
For example, when moving from w1 to w2 we
update only the frequencies of episodes
containing B (the incoming event).
Dr. N. Mamoulis
Advanced Database Technologies
60
WINEPI
This method is called WINEPI (mining frequent
episodes using a sliding time window)
If we count parallel episodes (the order of events
does not matter) computation is simple
If we count serial episodes (the events are ordered in
the episode) computation is based on automata
Hybrid episodes (with partial event orders) are
counted hierarchically; they are broken to serial or
parallel sub-episodes, the frequencies of them are
counted, and the frequencies of the hybrid episode are
computed by checking the co-existence of the parts.
Dr. N. Mamoulis
Advanced Database Technologies
61
MINEPI
Another method (MINEPI) follows a different strategy
(not counting frequencies in sliding windows)
The approach is based on counting minimal occurrences
of episodes
A minimal occurrence of an episode α is a time interval
w=[ts, te) such that (i) α occurs in w and (ii) no subwindow of w contains α
Example: minimal occurrences of AB
A C ED B C F
BA A
C D EA A C
D CE A C F D A B
time
Dr. N. Mamoulis
Advanced Database Technologies
62
MINEPI (cont’d)
The algorithm is again level-wise. The frequent episodes with
k events are computed from the frequent episodes with k-1
events.
At level k the algorithm computes the minimal occurrences of
all episodes with k events.
The level k+1 episodes are found by performing a temporaljoin of the minimal occurrences of the sub-episodes of size k.
Example. To find the frequency an minimal occurrences of
ABC, we join the MO of AB with the MO of BC
A C ED B C F
BA A
C D EA A C
D CE A C F D A B
occurrence of ABC
Dr. N. Mamoulis
Advanced Database Technologies
time
63
WINEPI vs. MINEPI
MINEPI is very efficient in finding frequent episodes, but it
may suffer from the excessive space needed to store the
minimal occurrences. These may not fit in memory for large
problems. Especially the early phases of MINEPI can be very
expensive.
However the temporal join is much more efficient than the
counting of WINEPI. Moreover, MINEPI is independent to the
window size.
In general, the algorithms may produce different results
because of the different definition of frequency.
WINEPI and MINEPI can be combined to derive frequent
episodes efficiently.
Dr. N. Mamoulis
Advanced Database Technologies
64
References
Jiawei Han and Micheline Kamber: "Data Mining:
Concepts and Techniques ", Morgan Kaufmann, 2001
Rakesh Agrawal, Ramakrishnan Srikant: Fast
Algorithms for Mining Association Rules in Large
Databases, VLDB 1994
Jiawei Han, Jian Pei, Yiwen Yin: Mining Frequent
Patterns without Candidate Generation, ACM SIGMOD,
2000
Heikki Mannila, Hannu Toivonen, and A. Inkeri
Verkamo: Discovery of frequent episodes in event
sequences. Data Mining and Knowledge Discovery
1(3): 259 - 289, November 1997
V. Kumar and M. Joshi, “Tutorial on High Performance
Data Mining”, http://wwwusers.cs.umn.edu/~mjoshi/hpdmtut/
Dr. N. Mamoulis
Advanced Database Technologies
65