Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
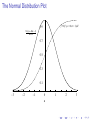
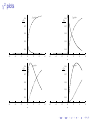
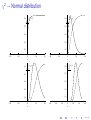
Statistics for Astronomy I: Introduction and Probability Theory B. Nikolic Astrophysics Group, Cavendish Laboratory, University of Cambridge 20 October 2008 ‘Astronomers cannot avoid statistics, and there are several reasons for this unfortunate situation.’ [Wall(1979)] ‘Astronomers cannot avoid statistics, and there are several reasons for this unfortunate situation.’ [Wall(1979)] ◮ You should aim to make best use of available data: thorough understanding of statistics is the key to that ◮ Statistical inference is relevant both to interpreting observation and simulation Simply applying formulae often not sufficient: ◮ ◮ ◮ Need to understand the theory, limitations, etc Computer based processing essential Course goals ◮ Review of essential statistics ◮ ◮ ◮ Basic applications of statistics in astronomy ◮ ◮ Some topics that everybody should know I expect there is a range of backgrounds here so for some this may be all very familiar Some classic applications Introduction to advanced statistics ◮ A survey rather than a thorough tutorial Goals for this Lecture Course introduction Probability Theory Moments Characteristic functions The central limit theorem Well-known probability distributions Normal Distribution Binomial distribution Poisson distribution χ2 distribution Reference materials J. V. Wall and C. R. Jenkins, Practical Statistics for Astronomers (CUP) D. J. C. MacKay Information Theory, Inference, and Learning Algorithms (CUP) Mike Irwin lectures http://www.ast.cam.ac.uk/˜mike/lect.html Penn State University Center for Astrostatistics http://astrostatistics.psu.edu/ My lectures and supporting materials http://www.mrao.cam.ac.uk/˜bn204/lecture/ J. V. Wall’s papers: 1979QJRAS..20..138W and 1996QJRAS..37..519W http://adsabs.harvard.edu/abstract_service.html Probability Dual use of ‘probability’: ◮ Quantify with what frequency a ‘random-variable’ is expected to take its possible values ◮ A measure of the degree of belief that a hypothesis is true Random variables ◮ ◮ Random variable: outcome of an experiment that we can not determine in advance The cause of apparent randomness is often simply that we do not know the initial conditions of the experiment ◮ ◮ ◮ ◮ e.g., flipping a coin or a roll of the roulette wheel are both easily predictable given fairly rudimentary measurements of initial conditions when coin/ball are launched. [Yes, this has been exploited in practice] output of a computer random number generator is exactly predictable if you know the internal state of the generator (it usually is from 8 to 128 bits long) and almost completely unpredictable if you do not ‘Randomness’ of an experiment is therefore subjective and a function of prior knowledge about the experiment Random variables can be continuous or discrete PDF X is a continuous random variable Probability Density Function (PDF) P(x)dx is the probability of X being in range x to x + dx ◮ P(x) is non-negative: P(x) ≥ 0 ◮ Area under P(x) is unity: Z ∀x (1) P(x)dx = 1 (2) CDF Cumulative Density Function (CDF) C(x) is the probability that X is less than x: Z x P(x ′ )dx ′ C(x) = (3) −∞ ◮ Cumulative functions are easier to estimate from observations: ◮ ◮ ◮ They can be visualised more faithfully (i.e., with fewer assumptions) They form a basis of a number of important statistical tests Mathematically CDFs are a slightly more general way of describing probabilities than PDFs Discrete random variables ◮ Most results retain equivalent forms, with integrals turned to sums etc ◮ Probability density function usually renamed ‘Probability Mass Function’ (PMF) The possible values of the random variables need not have a defined ordering ◮ ◮ ◮ e.g., X = H or X = T for heads or tails outcomes no ordering =⇒ no cumulative distribution Moments of probability distributions µn (r ), n-th moment around value r : Z µn (r ) = (x − r )n P(x)dx Mean, µ, is the first moment around r = 0: Z µ = xP(x)dx n-th central moment is the n-th moment around the mean: Z µn (r = µ) = (x − µ)n P(x)dx Note that moments do not necessarily exist even for some common theoretical distributions. (4) (5) (6) Moments II µ2 second central moment = variance = σ 2 µ3 /σ 3 Skew: a measure of asymmetry of the distribution µ4 /σ 4 Kurtosis: a measure of peakiness / fatness Conversion between central moments (µn ) and moments about origin (µ′n ) : n X n µn = (−1)n−j µ′j µn−j (7) j j=0 E.g.: µ2 = µ′2 − µ2 (8) Moments III: why all the fuss? ◮ ◮ As we will see shortly, moments are a way of expanding a probability distribution into coefficients quite similar to say Taylor expansion of a function Can quantitatively compare to normal distribution, e.g.: ◮ ◮ ◮ Expect Skew = 0 for normal distribution Expect Kurtosis =3 for normal distribution Central-limit theorem Characteristic function Characteristic function of a probability distribution: Z φ(t) = exp(itx)P(x)dx (9) ◮ Note the sign in the exponent means that the φ(t) is the inverse Fourier transform of the probability density function ◮ φ(0) ≡ 1 ◮ Moments of the PDF are closely related to the Taylor expansion of the Characteristic function: n ′ −n d φ(t) µn = i n dt t=0 One reason for fussing about the moments! (10) Characteristic function II Expand the characteristic function explicitly in terms of moments: φ(t) = 1 + itµ − t3 t4 t2 ′ µ2 − i µ′3 + µ′4 + · · · 2 3! 4! (11) The central limit ◮ ◮ φX (t) is the characteristic of PX (x) if Y = X1 + X2 , what is φY , the characteristic function of Y ? ◮ ◮ ◮ φY (t) = φX1 (t) × φX2 (t) Think of this in terms of the convolution theorem in Fourier analysis If Y = ◮ P k ak Xk ? φY (t) = Q k φXk (ak t) Sums of independent random variables The analysis above shows that for sums of lots of independent random variables, the characteristic function must: φY (t) → 0 when |t| >> 1 almost regardless of distributions of component variables (12) The central limit II Look for function which: What about: φ(0) = 1 (13) φ(t) → 0 quickly when |t| >> 1 (14) t 2 σ2 φ(t) = exp − 2 (15) The central limit II Look for function which: What about: φ(0) = 1 (13) φ(t) → 0 quickly when |t| >> 1 (14) t 2 σ2 φ(t) = exp − 2 The PDF that corresponds to this characteristic function: 1 x2 N(x; σ) = √ exp − 2 2σ 2πσ 2 (15) (16) The Normal Distribution ◮ Results naturally where a large number of independent variables are additively combined " (x − µ)2 exp − N(x; µ, σ) = √ 2σ 2 2πσ 2 t 2 σ2 φN (t; µ, σ) = exp itµ − 2 1 # (17) (18) The Normal Distribution Plot Rx 0.9 N (x;µ =0,σ =1) 0.399 N(x′ ; µ = 0, σ = 1)dx′ 0.7 0.5 0.3 0.1 −3 −2 −1 0 x 1 2 3 Ubiquity of the Normal Distribution ◮ Voltage fluctuations across a resistor at finite temperature: σ 2 ∝ 4kB TR ◮ Limiting form of a number of other distributions ◮ Analytically tractable But it is clearly not always applicable: ◮ ◮ Experiments involving human intervention almost never normally distributed: ‘possibility of outliers’ Non-linear processing algorithms: ◮ ◮ Object detection / de-blending De-convolution ◮ Electronics: 1/f noise and drift ◮ Sometimes ‘pre-process ’ observation to get the errors closer to normally distributed (inevitably this leads to loss of information) Binomial distribution If p is the probability of ‘success’ in one trial, binomial distribution gives the probability of j successes in n independent trials: n j P(j) = p (1 − p)n−j j (Easily derived through combinatorial arguments) (19) Poisson distribution Poisson distribution Probability that n events will occur in time interval of length T given that the underlying rate is λ per unit time: P(n; T , λ) = (λT )n exp(−λT ) n! (20) ◮ Derived by generalising the binomial and then multinomial distributions ◮ A discrete distribution: n is a discrete random variable ◮ Moments: µ = λT mean (21) µ2 = λT variance (22) Poisson Distribution Plots Rx 0.9 Poissonλ =2 (x) 0.270671 Poissonλ =2 (x′ )dx′ Poissonλ =5 (x) 0.175467 0.7 0.7 0.5 0.5 0.3 0.3 0.1 Poissonλ =5 (x′ )dx′ 0.1 −2.5 0 2.5 5 7.5 −2.5 10 x Rx 0.9 Poissonλ =10 (x) 0.12511 Poissonλ =10 (x′ )dx′ 0 2.5 5 7.5 10 x Rx 0.9 Poissonλ =100 (x) 0.039861 0.7 0.7 0.5 0.5 0.3 0.3 0.1 −5 Rx 0.9 Poissonλ =100 (x′ )dx′ 0.1 0 5 10 x 15 20 −50 0 50 100 x 150 200 Poisson → Normal distribution ◮ As seen above, Poisson distribution quickly approaches the normal distribution as T λ >> 1. ◮ The parameters of the limiting normal distribution: µ = Tλ √ σ = Tλ (23) (24) The χ2 distribution Y = n X Xi2 X ∼ N(µ = 0, σ = 1) i=1 =⇒ Y ∼ χ2n Pχ2 (y; n) = (25) (26) y (n/2)−1 exp (−y/2) 2n/2 Γ(n/2) ◮ Key use of the χ2 distribution is in model testing ◮ If fi is model for i-th random variable (=observable): n X Xi − fi 2 Y = σi i=1 (27) (28) χ2 plots Rx 2 ′ χ (x )dx′ 0.9 −6 −4 0.7 0.5 0.5 0.3 0.3 0.1 0.1 0 x 2 4 6 −6 −4 Rx 2 ′ χ (x )dx′ 0.9 −2 0.7 0.7 0.5 0.5 0.3 0.3 −4 −2 2 4 6 4 6 Rx 2 ′ χ (x )dx′ 5 χ 52 (x) 0.15418 0.1 −6 0 x 0.9 3 χ 32 (x) 0.241971 2 χ 22 (x) 0.497506 0.7 −2 Rx 2 ′ χ (x )dx′ 0.9 1 χ 12 (x) 3.96953 0.1 0 x 2 4 6 −6 −4 −2 0 x 2 χ2 → Normal distribution 0.9 −20 Rx 2 ′ χ (x )dx′ 0.7 0.5 0.5 0.3 0.3 0.1 0.1 0 x 10 20 −20 −10 0 x Rx 2 ′ χ10 (x )dx′ 0.9 −10 20 2 (x) χ 30 0.0529946 0.7 0.7 0.5 0.5 0.3 0.3 0.1 0.1 0 x 10 Rx 2 ′ χ30 (x )dx′ 0.9 2 (x) χ 10 0.0976834 −20 5 χ 52 (x) 0.15418 0.7 −10 Rx 2 ′ χ (x )dx′ 0.9 1 χ 12 (x) 225626 10 20 −60 −40 −20 0 x 20 40 60 χ2 → Normal distribution II For χ2n : ◮ µ1 = n ◮ µ2 = 2n ◮ Kurtosis 3 + 12/k : converges to Normal F -distribution X1 ∼ χ2j =⇒ ◮ X1 /j ∼ Fj,k X2 /k X2 ∼ χ2k Key use of the F −distribution is in testing of variances (29) (30) Bibliography Wall J. V., 1979, QJRAS, 20, 138