Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
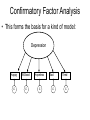
Factor Analysis & Structural Equation Models 1 Sociology 8811, Class 28 Copyright © 2007 by Evan Schofer Do not copy or distribute without permission Announcements • Paper #2 due today! • Schedule: Structural equation models • I’ll start with related issue: • Factor Analysis • Path Models • Monday lab: • Factor analysis • Whatever else we can squeeze in (Path models, SEM) • NO graded lab assignment Factor Analysis • Factor analysis is an exploratory tool • Often called “Exploratory Factor Analysis” • Helps identify simple patterns that underlie complex multivariate data – Not about hypothesis testing – Rather, it is more like data mining • And also helps us understand some principles of SEM – Note: Factor analysis is informally used to refer to two different methods • Factor analysis (FA) • Principle component analysis (PCA) • Differences aren’t critical here – I will focus on FA, which is most useful in understanding SEM – Most of lecture will apply to PCA. Factor Analysis • The basic idea: FA seeks to identify a small number of “underlying variables” that effectively summarize multivariate data • Ex: Suppose we have many political opinion variables – Approval of president; environmental views; etc. • Perhaps one unmeasured “factor” accounts for people’s positions on all those variables… – Ex: Liberalism vs. conservatism… • FA seeks to identify common patterns – But, it is up to the researcher to determine what the underlying pattern really means… Factor Analysis: ‘Depression’ • Suppose we believe in a theoretical construct such as “depression”. • There is no single variable that perfectly measures it… but we believe it exists • Hypothetical questions: • HAPPY: How happy are you? (1-10) • WORLDGOOD: How much do you agree with the statement that “The world is a good place”? (1-5) • HOPELESS: Do you often feel hopeless? (1-5) • SAD: Do you often feel sad? (1-5) • TIRED: Do you often feel tired or discouraged? (1-10) Example: ‘Depression’ • Strategy 1: We could ask many questions & create an index that combines all measures • Note: we would have to flip signs on some measures • “Happy” would have to be reversed to effectively measure ‘depression’ • Strategy 2: We could ask many questions and then conduct a factor analysis • To see if answers to questions exhibit an underlying pattern (which we could label “depression”). Factor Analysis: Depression • Hypothetical results from a factor analysis: Happy WorldGood Hopeless Sad Tired Factor Loadings Factor 1 Factor 2 -.86 … -.75 .92 .95 .71 … … … … A factor is a variable that explains lots of variance among the variables being analyzed (Happy, sad, hopeless, etc) Loadings are the correlation between each variable and the unobserved factor… The loadings tell you a lot about patterns of variation among cases… Notably: People who score high on “sad” & “hopeless” & “tired” tend to score very low on “happy” and “worldgood” and vice versa… Factor Analysis: Depression • Issue: It is wholly up to the researcher to interpret the factors • We are just data mining… • To ascribe meaning to factors requires much careful thought – and is ideally informed by theory… Happy WorldGood Hopeless Sad Tired Factor 1 -.86 -.75 .92 .95 .71 What might factor 1 represent? Does it seem like it captures “Depression”? Might it mean something else? Factor Analysis: Depression • Factor analysis is agnostic to direction of factor variables… results might look like this: Happy WorldGood Hopeless Sad Tired Factor 1 .86 .75 -.92 -.95 -.71 For all intents & purposes, these results are identical… but flipped The factor is capturing the inverse of depression… (happiness?) Factor Analysis • Things you can do with factor analysis: • 1. Examine factor loadings – Use them to interpret factors that are identified in the data • 2. Plot factor loadings – Vividly describe which variables “go together” (people score high on one tend to score high on another or vice versa) • 3. Compute factor scores – Estimate how individual cases score on underlying factors – How depressed is each case? • 4. Determine variation explained by factors – See which factors account for the major patterns in your data • 5. “Rotate” the factors – Modify them to enhance interpretability… Will discuss later. FA Example: Civic Engagement • How do people participate in politics? • Do people vary systematically in civic participation? • Is there such a thing as “civic engagement”? – A common pattern of behavior that appears in empirical data? – World Values Survey Data for USA: • • • • • • Membership in civic groups Volunteering Participation in demonstrations Participation in strikes Participation in boycotts Sign petitions. FA Example: Civic Engagement • Factor analysis of US civic participation . factor member volunteer petition boycott demonstrate strike occupybldg Factor analysis/correlation Method: principal factors Rotation: (unrotated) Number of obs = Retained factors = Number of params = 1110 3 18 -------------------------------------------------------------------------Factor | Eigenvalue Difference Proportion Cumulative -------------+-----------------------------------------------------------Factor1 | 1.51105 0.71238 0.8319 0.8319 Factor2 | 0.79867 0.67994 0.4397 1.2717 Factor3 | 0.11872 0.20190 0.0654 1.3370 Factor4 | -0.08318 0.04249 -0.0458 1.2912 Factor5 | -0.12567 0.05446 -0.0692 1.2221 Factor6 | -0.18013 0.04305 -0.0992 1.1229 Factor7 | -0.22318 . -0.1229 1.0000 -------------------------------------------------------------------------LR test: independent vs. saturated: chi2(21) = 1405.19 Prob>chi2 = 0.0000 Initial output describes process of factor extraction – identifying factors within the data. Stata identifies many factors (all possible patterns until it runs out of variation). But, only factors with large eigenvalues explain a lot… FA Example: Civic Engagement • Output (cont’d) Factor loadings (pattern matrix) and unique variances ----------------------------------------------------------Variable | Factor1 Factor2 Factor3 | Uniqueness -------------+------------------------------+-------------member | 0.7111 -0.5941 0.0984 | 0.1316 volunteer | 0.6689 -0.6450 0.0939 | 0.1278 petition | 0.3485 0.2288 -0.6927 | 0.3464 boycott | 0.6350 0.3756 -0.2149 | 0.4095 demonstrate | 0.6210 0.4021 -0.1098 | 0.4406 strike | 0.4035 0.4387 0.4021 | 0.4830 occupybldg | 0.2698 0.4038 0.5597 | 0.4509 ----------------------------------------------------------- Next, stata reports the main factors it finds. Factor 1 explains most variation, others less… Factor 1 correlates with ALL measures of civic participation In other words, people tend to be high on all measures or low on all. Factor 2: Some people are LOW on membership & moderately high on demonstrations/strikes. Others are the converse… Is this “civic engagement”? Maybe some people are alienated or active in social movements? FA Example: Civic Engagement • Output (cont’d) Factor loadings (pattern matrix) and unique variances ----------------------------------------------------------Variable | Factor1 Factor2 Factor3 | Uniqueness -------------+------------------------------+-------------member | 0.7111 -0.5941 0.0984 | 0.1316 volunteer | 0.6689 -0.6450 0.0939 | 0.1278 petition | 0.3485 0.2288 -0.6927 | 0.3464 boycott | 0.6350 0.3756 -0.2149 | 0.4095 demonstrate | 0.6210 0.4021 -0.1098 | 0.4406 strike | 0.4035 0.4387 0.4021 | 0.4830 occupybldg | 0.2698 0.4038 0.5597 | 0.4509 ----------------------------------------------------------- Factor 3 finds that some people engage in strikes/occupation of buildings but do not sign petitions. A bit hard to interpret… Focus your energies on first few factors that have big eigenvalues… FA Example: Civic Engagement • A visual representation of factor loadings .4 Factor loadings Command: “loadingplot” -- run after factor analysis demonstrate boycott .2 strike occupybldg petition -.2 0 Descriptive patterns emerge from the data -.4 member volunteer 0 .2 .4 Factor 1 .6 .8 Membership & volunteering go together… But are far from strikes, protests, etc. Factor Rotation • Factors can be “rotated” • Rotation = recalculating them to maximize differences between them • This can improve interpretability of factors Rotated factor loadings (pattern matrix) and unique variances ----------------------------------------------------------Variable | Factor1 Factor2 Factor3 | Uniqueness -------------+------------------------------+-------------member | 0.8061 0.0974 0.0139 | 0.3405 volunteer | 0.8055 0.0377 -0.0087 | 0.3497 petition | 0.0615 0.3130 -0.1456 | 0.8771 boycott | 0.1504 0.5724 0.0165 | 0.6494 demonstrate | 0.1358 0.5614 0.0671 | 0.6619 strike | 0.0371 0.3536 0.2421 | 0.8150 occupybldg | -0.0030 0.2439 0.2501 | 0.8780 ----------------------------------------------------------- Here, we see a clearer pattern… Factors 1 & 2 are more distinct. Factor 1 = civic membership; factor 2 = protest/social mvmts, etc… FA Example: Civic Engagement • Let’s plot the rotated factor loadings: Factor loadings .6 Pattern is similar to unrotated… But, rotation moves variables closer to axes .4 boycott demonstrate strike petition .2 occupybldg 0 member volunteer 0 Rotation: orthogonal varimax Method: principal factors .2 .4 Factor 1 .6 .8 Factor Scores • Factors = variables… • We can compute the value of them for a given case… • Ex: How high do I score on F1 (depression)? • Stata syntax: “predict f1 f2 f3…” – If you only want scores from first 2 factors, just list 2 variable names… – Note: If done after rotation, scores will be based on rotated factor loadings! Results will differ – This is a powerful way to create index variables… • Ex: Depression. You could sum several variables to create an index… • Or do a factor analysis and compute scores for a factor that appeared to reflect depression… FA Example: Civic Engagement • Factor scores from some sample cases: . predict f1 f2 f3 (regression scoring assumed) Scoring coefficients (method = regression; based on varimax rotated factors) . list member volunteer f1 f2 1. 2. 3. 4. 5. 6. 8. 9. 12. 13. 14. 15. 16. +-------------------------------------------+ | member volunt~r f1 f2 | |-------------------------------------------| | 3 2 .3280279 .4303528 | | 1 0 -.6338809 -.305814 | | 3 3 .575327 -.8480528 | | 5 5 1.52282 .3150256 | | 7 3 1.450748 .4064942 | | 4 4 1.044003 -.4640276 | | 0 0 -.8484179 .5083777 | | 5 5 1.523822 -.9253936 | | 2 2 .1134908 1.244545 | | 1 0 -.6204671 .5076937 | | 5 4 1.276523 .353012 | | 7 5 1.956463 -.4956342 | | 9 1 1.374107 -.3197608 | Cases that are high on membership & volunteering score very high on factor 1 FA Example: Civic Engagement • Factor scores can also be plotted This is most useful when you have a small number of cases… Ex: countries, which can be labeled on plot -1 0 1 2 3 Score variables (factor) -2 Rotation: orthogonal varimax Method: principal factors 0 2 Scores for factor 1 4 6 Stata: Loadingplots & scoreplots • Notes: • 1. Plots can be done of all factors… – I’ve only showed first two… to keep things simple – Syntax: loadingplot, factors(3) • 2. Case labels can be useful on scoreplots – Scoreplot, mlabel(countryid) – Jitter can sometimes be useful, too… • 3. Some software allows “biplots” – Plotting loadings & scores together – Helps uncover patterns in data. Example: Biplot • Cross-national data on civic participation Biplot (axes F1 and F2: 74.71 %) Note that France falls near to activities like “strikes” 4 do ccupy 3 dstrike italy F2 (16.35 %) 2 chile -5 -4 france ddemo n spain belgium po land 1 argentina russian mexico denmark robelarus mania federatio n peru ukraine po rtugal so uth africaluxembo urg philippines 0 hungary czech republic -3 turkey -2 -1 0East 1 2 3 4 netherlands ireland Germany slo vakia -1 West Germany austria japan finland -2 canada great britain united states wto t -3 F1 (58.36 %) mtosweden t dpetitio n dbo yco tt 5 US is nearer to mtot (memberhip) Factor Analysis: Methods • There are MANY algorithms to extract & rotate factors • A thorough discussion is beyond the scope of this class • Some defaults (if you don’t choose): – SPSS: Principle components extraction, varimax rotation – Stata: Principle factors extraction; varimax rotation • Results can vary if you use different methods… – In practice, few people are skilled in choosing among methods… people mainly use defaults – I recommend trying multiple methods to ensure that results are robust… Confirmatory Factor Analysis • Factor analysis is purely exploratory • It is data mining, not a model • However, it is based on the idea that factors – which are unobserved – give rise to (i.e., cause) variation on observed variables Depression Happy WGood Hopeless Sad Tired Confirmatory Factor Analysis • Idea: Let’s imagine that depression is a latent variable • i.e., a variable we can’t directly measure… but gives rise to observed patterns in things we can observe • Note: No observed variable perfectly measures the latent variable – There is error… – So, observed variables aren’t perfectly correlated with latent variable (even though they are “caused” by it)… Confirmatory Factor Analysis • This forms the basis for a kind of model: Depression Happy WGood Hopeless e e e Sad e Tired e Confirmatory Factor Analysis • Idea: We can model real data based on those presumed relationships… • Estimate slope coefficients for each arrow – How do latent variables affect observed variables? • Examine overall model fit – How much does our theoretically-informed view of the world map onto observed data? – If model fits well, our concept of “depression” (and measurement strategy) are likely to be good • “Confirmatory” implies that we aren’t just “exploring” – Different from “exploratory factor analysis”… – Rather than data mining, we’re testing a theoretically-informed model. SEM • Next step: Structural Equation Models (SEM) with Latent Variables • Once we’ve identified latent variables, it makes sense to analyze them! • We can develop models in which we estimate slopes relating latent variables… • This is particularly useful when we are interested in latent concepts that are difficult to measure with any single variable.