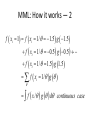Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
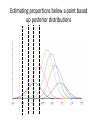
Latent regression models Where does the probability come from? • Why isn’t the model deterministic. • Each item tests something unique – We are interested in the average of what the items assess • Stochastic subject argument • Random sampling of subjects Two different models Random sampling Pr X ni xni ; i | n Stochastic subject Pr X ni xni ; i ,n A Random Effects (Sampling) Model -1 Part 1: A Model for the population ~ N , equivalently g ; , 2 2 2 1 exp 2 2 2 2 A Random Effects Model -- 2 Part 2: A Model for the item response mechanism Example: SLM (but can be any) Pr X ni xni ; i | f xni ; i | exp xni i 1 exp i A Random Effects Model -- 3 Part 3: Putting them together f xni ; , , i f xni ; i | g ; , 2 The unknowns are: 2 d , 2 and i is not an unknown, it is variable of integration What is analysed is item response, what is estimated is item parameters and population parameters Why do this? • Solves some theoretical estimation problems – For non-Rasch models • Provides better estimates of population characteristics Problems with point estimates var ˆn var n en var n var en var n Problem with discreteness • For a 6-item test, there are only 7 possible ability estimates to assign to people, those getting a score of 0,1,2,3,4,5,6. (raw score is sufficient statistic for ability) • Suppose we want to know where the 25th percentile point is. That is, 25% of the population are below this point. We need extrapolation. The Resulting JML Ability Distribution Score 3 Score 4 Score 2 Score 5 Score 1 Score 0 Score 6 Proficiency on Logit Scale Distribution for a six item test Score 3 Score 4 Score 2 Score 5 Score 1 Score 0 Score 6 Proficiency on Logit Scale Traditional approach is a two-step analyses First estimate abilities ˆn Then compute population estimates such as mean, variance, percentiles using ˆn leads to biased results due to measurement error. In the case of the population variance, we can correct the bias (disattenuate) by multiplying by the reliability. But in other cases, it is less obvious how to correct for the bias caused by measurement error. Distribution of Estimates is Discrete • One ability for each raw score • Ability estimates have a discrete distribution • We imagine (and the model’s premise) is a continuous distribution • The distribution of ability estimates is distorted by measurement error Solutions • Direct estimation of population parameters (directly via item responses, and not through the estimated abilities) • Complicated analyses that take into account the error – Not always possible MML: How it works — 1 • Item Response Model for item i: f xi 1 / exp i 1 exp i • Population Model (discrete) -1.5 -0.5 0 0.5 1.5 g() 0.1 0.2 0.4 0.2 0.1 MML: How it works — 2 f xi 1 f xi 1/ 1.5 g 1.5 f xi 1/ 0.5 g 0.5 f xi 1/ 1.5 g 1.5 f xi 1/ g f x / g d continuous case The Implications — 1 • If g ~ N , , 2 then f x contains parameters – Note that no ability parameters are involved, only population parameters. , ,, , , 1 2 I • Use maximum likelihood estimation method to estimate the item difficulty parameters and population parameters. • Thus, we directly estimate population parameters through the item responses Bayes Theorem Pr A | B Pr A B Pr B Pr A B Pr A | B Pr B Pr B | A Pr A B Pr A Pr A B Pr B | A Pr A Pr A | B Pr B Pr B | A Pr A Pr A | B Pr B | A Pr A Pr B The Idea of Posterior Distribution Pr A | B Pr B | A Pr A Pr | x Pr B Pr x | Pr Pr x • If a student’s item response pattern is x then the posterior distribution is given by h | x f x | g f x f x | g f x | g d The Idea of Posterior Distribution • Instead of obtaining a point estimate ˆnfor ability, there is now a (posterior) probability distribution h | x • h | x incorporates measurement error for the uncertainty in the estimate. The Resulting JML Ability Distribution Score 3 Score 4 Score 2 Score 5 Score 1 Score 0 Score 6 Proficiency on Logit Scale Resulting MML Posterior Distributions Score 3 Score 4 Score 2 Score 5 Score 1 Score 6 Score 0 Proficiency on Logit Scale MML EAP Estimates – an aside Score 3 Score 4 Score 2 Score 5 Score 1 Score 6 Score 0 Proficiency on Logit Scale MML EAP Estimates – an aside • Biased at the individual level • Discrete scale, bias & measurement error leads to bias in population parameter estimates • Requires assumptions about the distribution of proficiency in the population Distribution for a six item test Score 3 Score 4 Score 2 Score 5 Score 1 Score 0 Score 6 Proficiency on Logit Scale Estimating proportions below a point based up posterior distributions More General Form of the Model Pr Xn x n ; n , b, A, ξ exp x n b n Aξ exp z b zn n Aξ Item response model ~ N x y z ~ N Yβ, 2 , 2 Population model Population Not Normal • E.g., sample consists of grades 5 and 8. 0.45 0.4 0.35 0.3 0.25 0.2 0.15 0.1 0.05 0 1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 The underlying population distribution is a mixture of two normal distributions, with different means ( 1 and 2). Latent Regression - 1 g ~ N x, 2 • where x=0 if a student is in group 1 and x=1 if a student is in group 2. In this case, we estimate , 2and . Note that is the difference between the means of the two distributions. That is, group 1 has mean (as x=0), and group 2 has mean (as x=1). Latent Regression - 2 • We call “x” a “regressor”, or a “conditioning variable”, or a “background variable”. We can generalise to include many conditioning variables. g ~ N x y z , 2