Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
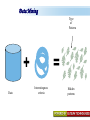
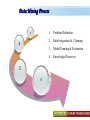
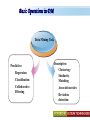
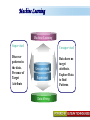
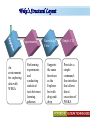
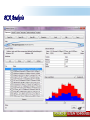
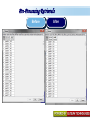
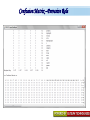
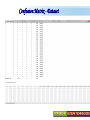
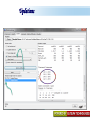
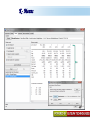
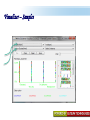
A Kit For Knowledge Discovery Data, Data everywhere yet ... I can’t find the data I need data is scattered over the network many versions, subtle differences I can’t get the data I need need an expert to get the data I can’t understand the data I found available data poorly documented I can’t use the data I found results are unexpected data needs to be transformed from one form to other 2 ? • There are sequence of steps (with eventual feedback loops) that should be followed to discover knowledge (e.g., patterns) in data. • Achieving Standardized Process Model What is KDD ? Knowledge Discovery in Data is the significant method of evaluating 1 2 Legitimate Probably Innovative useful 3 Accurate understandable patterns in data. Knowledge Discovery Process Interpretation & Evaluation Knowledge Knowledge RawData Integration DATA Ware house Target Data Transformed Data Patterns and Rules Understanding __ __ __ __ __ __ __ __ __ Outcomes of Data Mining Forecasting Future Classification on Recognizing patterns Clustering Based On Attributes Events Correlation – Association Sequencing Events ~ Later Predictions Data Mining Look for hidden patterns and trends in data that is not immediately apparent from summarizing the data Data Mining + Data = Interestingness criteria Hidden patterns Data Mining Type of Patterns + Data = Interestingness criteria Hidden patterns Data Mining Type of data Type of Interestingness criteria + Data = Interestingness criteria Hidden patterns What is a Data Warehouse? A single, complete and consistent store of data obtained from a variety of different sources made available to end users in a what they can understand and use in a business context. What is Data Warehousing? Information A process of transforming data into information and making it available to users in a timely enough manner to make a difference Data 12 Data Mining Process 1 2 3 4 1. Problem Definition 2. Data Integration & Cleaning 3. Model Framing & Evaluation 4. Knowledge Discovery Basic Operations in DM Data Mining Task Predictive: Regression Classification Collaborative Filtering Descriptive: Clustering / Similarity Matching Association rules Deviation detection Why Machine Learning Growing flood of online data Budding industry Progress in algorithms and theory • Data mining: using historical data to improve decision – medical records ⇒ medical knowledge – log data to model user • Software applications we can’t program by hand – autonomous driving – speech recognition • Self customizing programs – Newsreader that learns user interests Machine Learning Machine Learning Supervised Discover patterns in the data. Presence of Target Attribute Unsupervised Text Unsupervised Supervised Data Mining Data have no target attribute. Explore Data to find Patterns Applications Of Data Mining Applications of Data Mining Fraud/Non-Compliance Anomaly detection Isolate the factors that lead to fraud, waste and abuse Target auditing and investigative efforts more effectively Credit/Risk Scoring Intrusion detection Recruiting/Attracting customers Maximizing profitability (cross selling, identifying profitable customers) Service Delivery and Customer Retention Build profiles of customers likely to use which services Tools For Data Mining LinkOut NCBI Sequin Rapid Miner LibSvm ADaM etc…. Why Weka Weka is a collection of machine learning algorithms for data mining tasks. The algorithms can either be applied directly to a dataset or called from your own Java code. Weka contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization. It is also well-suited for developing new machine learning schemes. About WEKA Waikato Environment for Knowledge Analysis (WEKA) Developed by the Department of Computer Science, University of Waikato, New Zealand Machine learning/data mining software coded in Java Used for research, education, and applications Exclusively for KDD. Various Versions are available such as Version 2.3, 1998; Version 3.0, 1999; Version 3.4, 2003; Version 3.6, 2008. Weka GUI Chooser A Vital Part In Weka Explorer ww.themegallery.com Weka !!!!!!!! Weka is a collection of machine learning algorithms for data mining tasks. The algorithms can either be applied directly to a dataset or called from your own Java code. Weka contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization. Perfectly suited for developing new machine learning schemes. Weka’s Structural Layout Experimenter An environment for exploring data with WEKA Performing experiments and conducting statistical tests between learning schemes Knowledge Flow Supports the same functions as the Explorer but with drag-anddrop Simple CLI Provides a simple commandline interface that allows direct execution of WEKA Algorithms www.themegallery.com WEKA ! File WEKA stores data in flat files (ARFF format). Easy to transform EXCEL file to ARFF format. ARFF file consists of a list of instances ARFF file can be created using Notepad or Word. Name of the dataset is with @relation Attribute information is with @attribute Data is with @data. Attribute Relation File Format (ARFF) Sample ARFF Intrinsic Operations Select Attributes 5 Associate 4 Cluster 3 Classify 2 Preprocess 1 Preprocessing Changing Data formats as per the Needs. Varies as Per Mining Datasets. Some of the Preprocessing Steps Adding/removing attributes Attribute value substitution Discretization (MDL, Kononenko, etc.) Time series filters (delta, shift) Sampling, randomization Missing value management Normalization and other numeric transformations Algorithms Pre-Processing Opening Files Browse for the data file in local file system. Current Relation Relations Instances Schema Operations Attributes Filters Weka – Formulating Files Dataset -.txt Format Weka ~ Dataset’s Missing Values GenericObjectEditor A Property Editor for objects as editable in the GenericObjectEditor configuration file, which lists possible values that can be selected from, and themselves configured. The configuration file is called "GenericObjectEditor.props" and may live in either the location given by "user.home" or the current directory (this last will take precedence), and a default properties file is read from the weka distribution. Weka ~ GenericObjectEditor This Editor allows configure a filter. Same kind of dialog box is used to configure other objects, such as classifiers and clusterers. Sample - Cluster Attributes for Cluster Weka’s Viewer PCA Analysis Pre-Processing Retrievals Before After Retrieving Significant Attributes Algorithms Feature Selection Some columns are noisy or redundant. This noise makes it more difficult to discover meaningful patterns from the data; To discover quality patterns, most data mining algorithms require much larger training data set on high-dimensional data set. Feature selection, also known as variable selection, feature reduction, attribute selection or variable subset selection, is the technique of selecting a subset of relevant features for building robust learning models Attribute Selection Attribute selection involves searching through all possible combinations of attributes in the data to find which subset of attributes works best for prediction. To do this, two objects must be set up: The evaluator determines what method is used to assign a worth to each subset of attributes. The search method determines what style of search to be done The Attribute Selection Mode box has two options: 1. Use full training set. 2. Cross-validation. Attribute Selection Very flexible: arbitrary combination of search and evaluation methods Both filtering and wrapping methods Search methods best-first genetic ranking ... Evaluation mmeasures Relief information gain gain ratio ... Applying Algorithm Best Attribute Algorithm…… Classification Classification is a data mining function that assigns items in a collection to target categories or classes. The goal of classification is to accurately predict the target class for each case in the data. A classification task begins with a data set in which the class assignments are known. For example, a classification model that predicts credit risk could be developed based on observed data for many loan applicants over a period of time Classification ~ Naive Bayes classifier A naive Bayes classifier assumes that the presence (or absence) of a particular feature of a class is unrelated to the presence (or absence) of any other feature, given the class variable. For example, a fruit may be considered to be an apple if it is red, round, and about 4" in diameter. Even if these features depend on each other or upon the existence of the other features, a naive Bayes classifier considers all of these properties to independently contribute to the probability that this fruit is an apple. Naive Bayes Classifier Confusion Matrix –Pervasive Role Confusion Matrix - Dataset Second Fold -Classification Algorithms Clustering Clustering is the task of assigning a set of objects into groups (called clusters) so that the objects in the same cluster are more similar (in some sense or another) to each other than to those in other clusters. Belong to Unsupervised Learning Example ~ Weka Attributes Replacements Updations K- Means Visualizer Open Saved File Save File => Will Store in ARFF Visualizer – Samples Association rules Association rules are if/then statements that help uncover relationships between seemingly unrelated data in a relational database or other information repository. Finding frequent patterns, associations, correlations, or causal structures among sets of items or objects in transaction databases. An example of an association rule would be "If a customer buys a dozen eggs, he is 90% likely to also purchase milk.“ Market Basket Analysis Association Description Rules Framing Rules Set Visualize Result Analysis Result 2 Weka Result 1 Concept