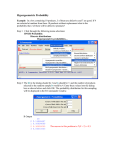
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
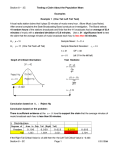
Checking for Fit ©2005 Dr. B. C. Paul The Assumption of Normalcy We have learned statistical tests and confidence intervals that work for normally distributed data We did ANOVA but assumed that all the random errors between classes were equal and normally distributed We did Regression and assumed that all the random error around the regression line was normally distributed. Do We Really Believe the Whole World is Normally Distributed? Probably not We talked about levels of effort 1- Just have faith and assume (which we have done a lot of lately) 2- Graphical Inspection (with our regression we started looking at plots of residuals) 3- Actual tests and calibration Testing to See if Data is Normally Distributed Must of course begin with a Data set. Click on Analyze to Pull Down The menu Highlight Descriptive Statistics To bring out side menu Highlight and Click Explore Load Up the Variable to Study In this case I brought MPG Over to be analyzed. Note that the default is to give me both plots and statistics Click on the Statistics Tab to Take a Closer Look at What We Get I just checked off the works The default is the descriptive Statistics and a confidence Interval on the mean. Reading Output Mean Value 95% Confidence Interval on Mean Variance This Might Not Be Normal Skewness – derived from The sum of deviations of Samples from the mean Cubed. (Thus it has a Sign – a long upper tail Pulls positive – a long Lower tail pulls negative) Our Skewness is negative (long lower tail?) Standard error is large Enough we cannot be Sure this is not a sample Quirk. A Kase of Kurtosis Kurtosis is a function of the Fourth power of the deviations Of individual scores from the Mean. Positive values indicate extra Weight in the tails – it indicates That the confidence intervals On the standard deviations are Wider than expected Kurtosis 1 means about 1.5 Times normal standard deviation Kurtosis 2 means about twice Negative Kurtosis indicates a flat top distribution – Ie the pile at the center is too small This distribution has a negative Kurtosis that could be somewhat flattened. A Shifted Mean We have Skewness and a Median Value suggesting a long lower Tail. Mathematical Averages for the mean Assume high and low values are Equally likely. A negative tail tends To shift likely estimates of the mean Down. There are several suggested ways Of trying to compensate. (Using them with confidence intervals is another matter. Normality Testing Kolmogorov-Smirnov Test Count what percentage of the samples are within certain distance of the estimated mean Compare the percentage with what you would expect from a normal distribution (or other expected distribution) If the deviations are large the test statistic will be large Does tend to need larger samples Shapiro-Wilk Test Similar type of test but tends to be geared more for samples under about 50 in size. Check Our Stats The departure from Normal is interesting But does not meet levels normally needed To reject a normal distribution. Shapiro-Wilk found deviations enough to Be suspicious Pretty Pictures Big Chunk in the Lower tail may Be our problem. We expect the mean about here. The Normal Probability Plot Upper part does not look to bad, but there Is that lower tail lump. Spread Around the Median Can see a negative tail (although we Suspect a lump in the tail). So What Does This Mean? The distribution is showing some suspicious deviations from normal Our ability to categorically reject a normal distribution is limited (K-S test did not reject) Problem appears to center on a clump of lower tail values From a science standpoint is there a reason to believe there may be something bimodal about this population? If there is no science then one may want to allow normal test procedures to go forward (with some caution about the lower tail if you think there might be some science to it) Robustness Many of the statistics procedures are fairly robust and yield answers fairly close to right for normal-like populations We are fitting models to populations – sometimes we may fool ourselves if we assume we can get 6 place accuracy from a mathematical model with a convenient similarity to our data Note that when one rejects in boarder-line cases calls for scientific judgment about what it is you are modeling (computer can’t study your subject for you).