Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
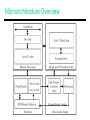
CS 7810 Lecture 22 Processor Case Studies, The Microarchitecture of the Pentium 4 Processor G. Hinton et al. Intel Technology Journal Q1, 2001 Clock Frequencies • Aggressive clocks => little work per pipeline stage => deep pipelines => low IPC, large buffers, high power, high complexity, low efficiency • 50% increase in clock speed => 30% increase in performance Mispredict latency = 10 cyc Mispredict latency = 20 cyc Deep Pipelines Variable Clocks • The fastest clock is defined as the time for an ALU operation and bypass (twice the main processor clock) • Different parts of the chip operate at slower clocks to simplify the pipeline design (e.g. RAMs) Microarchitecture Overview Front End • ITLB, RAS, decoder • Trace Cache: contains 12Kmops (~8K-16KB I-cache), saves 3 pipe stages, reduces power • Front-end BTB accessed on a trace cache miss and smaller Trace-cache BTB to detect next trace line – no details on branch pred algo • Microcode ROM: implements mop translation for complex instructions Execution Engine • Allocator: resource (regs, IQ, LSQ, ROB) manager • Rename: 8 logical regs are renamed to 128 phys regs; ROB (126 entries) only stores pointers (Pentium 4) and not the actual reg values (unlike P6) – simpler design, less power • Two queues (memory and non-memory) and multiple schedulers (select logic) – can issue six instrs/cycle Schedulers • 3GHz clock speed = time for a 16-bit add and bypass NetBurst • 3GHz ALU clock = time for a 16-bit add and bypass to itself (area is kept to a minimum) • Used by 60-70% of all mops in integer programs • Staggered addition – speeds up execution of dependent instrs – an add takes three cycles • Early computation of lower 16 bits => early initiation of cache access Detailed Microarchitecture Data Cache • 4-way 8KB cache; 2-cycle load-use latency for integer instrs and 6-cycle latency for fp instrs • Distance between load scheduler and execution is longer than load latency • Speculative issue of load-dependent instrs and selective replay • Store buffer (24 entries) to forward results to loads (48 entries) – no details on load issue algo Cache Hierarchy • 256KB 8-way L2; 7-cycle latency; new operation every two cycles • Stream prefetcher from memory to L2 – stays 256 bytes ahead • 3.2GB/s system bus: 64-bit wide bus at 400MHz Performance Results Quick Facts • November 2000: Willamette, 0.18m, Al interconnect, 42M transistors, 217mm2, 55W, 1.5GHz • February 2004: Prescott, 0.09m, Cu interconnect, 125M transistors, 112mm2, 103W, 3.4GHz Improvements • Willamette (2000) Prescott (2004) • L1 data cache 8KB 16KB • L2 cache 256KB 1MB • Pipeline stages 20 31 • Frequency 1.5GHz 3.4GHz • Technology 0.18m 0.09m Pentium M • Based on the P6 microarchitecture • Lower design complexity (some inefficiencies persist, such as copying register values from ROB to architected register file) • Improves on P4 branch predictor PM Changes to P6, cont. • Intel has not released the exact length of the pipeline. • Known to be somewhere between the P4 (20 stage) and the P3 (10 stage). Rumored to be 12 stages. • Trades off slightly lower clock frequencies (than P4) for better performance per clock, less branch prediction penalties, … Banias • 1st version • 77 million transistors, 23 million more than P4 • 1 MB on die Level 2 cache • 400 MHz FSB (quad pumped 100 MHZ) • 130 nm process • Frequencies between 1.3 – 1.7 GHz • Thermal Design Pointhttp://www.intel.com/pressroom/archive/photos/centrino.htm of 24.5 watts Dothan • Launched May 10, 2004 • 140 million transistors • 2 MB Level 2 cache • 400 or 533 MHz FSB • Frequencies between 1.0 to 2.26 GHz • Thermal Design Point of 21(400 MHz FSB) http://www.intel.com/pressroom/archive/photos/centrino.htm to 27 watts Branch Prediction • Longer pipelines mean higher penalties for mispredicted branches • Improvements result in added performance and hence less energy spent per instruction retired Branch Prediction in Pentium M • Enhanced version of Pentium 4 predictor • Two branch predictors added that run in tandem with P4 predictor: – Loop detector – Indirect branch detector • 20% lower misprediction rate than PIII resulting in up to 7% gain in real performance Branch Prediction Based on diagram found here: http://www.cpuid.org/reviews/PentiumM/index.php Loop Detector • A predictor that always branches in a loop will always incorrectly branch on the last iteration • Detector analyzes branches for loop behavior • Benefits a wide variety of program types http://www.intel.com/technology/itj/2003/volume07 issue02/art03_pentiumm/p05_branch.htm Indirect Branch Predictor • Picks targets based on global flow control history • Benefits programs compiled to branch to calculated addresses http://www.intel.com/technology/itj/2003/volume07iss ue02/art03_pentiumm/p05_branch.htm Benchmark Battery Life UltraSPARC IV • CMP with 2 UltraSPARC IIIs – speedups of 1.6 and 1.14 for swim and lucas (static parallelization) • UltraSPARC III : 4-wide, 16 queue entries, 14 pipeline stages • 4KB branch predictor – 95% accuracy, 7-cycle penalty • 2KB prefetch buffer between L1 and L2 Alpha 21364 • Tournament predictor – local and global; 36Kb • Issue queue (20-Int, 15-FP), 4-wide Int, 2-wide FP • Two clusters, each with 2 FUs and a copy of the 80-entry register file Title • Bullet