Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
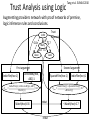
Trust Analysis on Heterogeneous Networks Manish Gupta 17 Mar 2011 Survey Roadmap • • • • • • • • Basic Iterative Fact Finder Models Extensions to Basic Fact Finder Models Source Copying Detection Trust Analysis for Homogeneous Networks Trust Metrics Trust Analysis using Logic Applications of Trust Analysis Models Conclusion Yin et al. TKDE 2008 Basic Iterative Fact Finder Models Three components of model – Trustworthiness of provider t(p) – Confidence of fact s(f) – Implications between facts imp(f, f’) Pasternack et al. COLING 2010 Basic Iterative Fact Finder Models • Sums (Hubs and Authorities) • Average.Log • Investment • Pooled Investment Galland et al. WSDM 2010 Extensions to Basic Fact Finder Models (Incorporating Hardness of Facts) • An answer to an easy question should earn less trust than to a hard one. • Three iterative approaches: Cosine, 2Estimates, 3-Estimates • 3-Estimates iteratively computes three things: hardness of facts (propensity of sources to be wrong on this fact), confidence in the T(true) value of the fact and the error (1trustworthiness) of the sources. Pasternack et al. WWW 2011 Extensions to Basic Fact Finder Models (Probabilistic Assertions) • The sources may provide facts with some uncertainty. • Rather than a unweighted provider-fact network, one can consider a k-partite weighted graph. • Weight on source-claim edge depends on probability that source asserted claim according to the information extractor, certainty expressed by the source in the claim, and similarity among claims. • Sums, Average.Log, Investment and TruthFinder are rewritten to incorporate weight of edges. • Introduce the notion of layered model, one which consists of multiple layers rather than just two layers. Gupta et al. WWW 2011 Extensions to Basic Fact Finder Models (Cluster-based Fact Finding) • Providers perform better in their areas of focus. • Basic Cluster-based Fact Finder (BCFF) – Computes object-conditional provider trust. – Clusters objects using Kmeans over object-conditional trust vectors. • Advanced Cluster-based Fact Finder (ACFF) – Starts with an initial clustering using BCFF. – Iteratively • Performs cluster-conditional trust analysis using current clustering. • Refines the clusters using current analysis obtained on the previous set of clusters. – Smooth cluster-based fact confidence score using the global computations. Pasternack et al. COLING 2010 Extensions to Basic Fact Finder Models (Using Common-Sense Reasoning) • Fact finders should be able to incorporate common sense knowledge. • Common sense knowledge is expressed using first order logic rules and then transformed into a tractable linear program. • This linear program constrains the claim beliefs produced by a fact finder, ensuring that the belief state is consistent with both common-sense and known facts. • Iterative framework: – Compute trustworthiness values using confidence of facts. – Update confidence of facts based on trustworthiness of providers. – Correct confidence of facts using the linear program. Berti-Equille et al. CIDR 2009 Source Copying Detection (Overview) • Sourced copy from each other. • The higher the similarity between the data sources, the more is the likelihood of similarity dependence. • Direction of dependence: consider the data source whose different subsets of data show different properties (e.g., accuracy, average rating) as more likely to be dependent on the other. • Two different settings: static and dynamic • Complex copying relationships: co-copying, transitive copying, copying from multiple sources, lazy copying Dong et al. VLDB 2009 Source Copying Detection (For Static snapshots) • Data sources that share common false values are much more likely to be dependent than data sources that share common true values. • Bayesian analysis model (iterative solution) – Determine true values – Compute accuracy of sources – Discover dependence between every pair of sources • Further extensions – Handle similarity between values when computing the confidence of a value – Removes the assumption of “false values of an object being uniformly distributed” – Incorporate the accuracy of a source when computing the dependency between pair of sources. Dong et al. VLDB 2009 Source Copying Detection (Dynamic scenarios) • True values can evolve over time. Also copying relationships can evolve over time. • Data sources that share common false values are much more likely to be dependent than data sources that share common recent or outdated true values. • Data sources that perform the same updates in close enough time frame are more likely to be dependent, especially if the same update trace is rarely observed from other sources. • HMM Model to detect copying dependence over time. • Bayesian analysis model (iterative solution) – Compute CEF (coverage, exactness and freshness) for each source – Compute probability of copying between sources – Decide the life span of each object Dong et al. VLDB 2010 Source Copying Detection (Complex copying relationships) • Complex copying relationships exist like cocopying, transitive copying, copying from multiple sources and correlated copying. • The first step locally decides possibility of copying and copying direction between each pair of sources using completeness, accuracy and formatting of data and correlated copying. • The second step (greedy algorithm) globally identifies co-copying and transitive copying and copying from multiple sources and correlated copying Blanco et al. CAiSE 2010 Source Copying Detection (Using multiple attributes) • Data sources usually provide complex data, i.e. collections of tuples with many attributes. Different attributes may exhibit different evidence of dependence. • They compute (i) probability that the observed properties of an object assume certain values (ii) accuracy of a provider with respect to each observed property. • When performing copy detection, they combine information from multiple properties. • They consider stock data with multiple attributes and show that some 3-attribute configurations perform better than 1attribute configurations. But considering all 5 attributes results in lower accuracy. Balakrishnan et al. WWW 2011 Trust Analysis for Homogeneous Networks (SourceRank) • Trust analysis for deep web (non-cooperative) sources. • They build an agreement graph with nodes as sources and edges weights=Agreement based on sample query results using partial queries. Compute source importance using random walks. • Agreement=Similarity in attribute value, tuple, answer set. • Combat source collusion based on topk answers to large answer queries and adjust agreement by (1-collusion). Yin et al. WWW 2011 Trust Analysis for Homogeneous Networks (Semi-supervised truth finder) • Including some level of supervision can help guide the iterative fact finding algorithms in the right direction. • The approach is based on three principles: (i) facts provided by the same data source should have similar confidence scores, (ii) similar (and therefore mutually supportive) facts should have similar confidence scores and (iii) if two facts are conflicting, they cannot be both true. • These principles are encoded into a facts graph using appropriate edge weights • Truth discovery is then equivalent to solving an optimization problem that aims to assign scores to graph nodes that are consistent with the relationships indicated by the graph edges. This involves minimizing a convex function using an iterative algorithm which converges to an optimal solution. Nelson et al. CHANTS 2010 Trust Analysis for Homogeneous Networks (Trust in presence of non-cooperative sources) • All facts may not be available before performing trust analysis. • Delay Tolerant Networks (DTNs): use of group information requires that nodes throughout the network be aware of the membership lists for all groups. • MembersOnly that collects group membership information from each node it meets and consolidates it on-the-fly. • Nodes propagate group membership lists only for groups of which they are members, to every contact that node makes. • MembersOnly calculates the difference between the strength of the (sigmoid transformations of) positive evidence and the strength of the (sigmoid transformations of) negative evidence. Castelfranchi et al. ICMAS 1998, Gil et al. Web Semantics 2007, Pasternack et al. ARL 2010 Trust Metrics Multiple factors can determine trust • • • • • • • • • • Topic/Cluster Context and criticality Popularity Perceived authority Direct experience Recommendation Related resources Provenance User expertise Bias • • • • • • • • • Incentive Limited resources Agreement Specificity Likelihood Age Appearance Deception Recency Trust Analysis using Logic Tang et al. EUMAS 2010 Augmenting providers network with proof networks of premise, logic inference rules and conclusions. Trust network John 0.8 0.9 Mary 0.7 0.8 0.7 Dave Jane First argument IndieFilm(hce:1) 𝛿Dave = Second argument DirectedBy(hce, ABC):1 SpanishFilm(hce:1) 𝐼𝑛𝑑𝑖𝑒𝐹𝑖𝑙𝑚(𝑥) ∧ 𝐷𝑖𝑟𝑒𝑐𝑡𝑒𝑑𝐵𝑦(𝑥, 𝐴𝐵𝐶) : 0.8 𝑊𝑎𝑡𝑐ℎ(𝑥) Watch(hce):0.8 𝛿Jane = rebut rebut IndieFilm(hce):1 𝐼𝑛𝑑𝑖𝑒𝐹𝑖𝑙𝑚(𝑥) ∧ 𝑆𝑝𝑎𝑛𝑖𝑠ℎ𝐹𝑖𝑙𝑚(𝑥) : 0.7 ¬𝑊𝑎𝑡𝑐ℎ(𝑥) ¬Watch(hce):0.7 Applications of Trust Analysis Models Dai et al. BNCOD 2008, Wu et al. WebDB 2007, Gao et al. ACAI 2009, Le et al. ISPN 2011 Applications of Trust Analysis Models • Provenance-based Access Control Systems – Credibility of a data item based on data similarity, data conflict, path similarity and data deduction • Ranking web results (graph of answers and websites) • Website ranking (graph of webpages and websites) • Sensor networks Liao et al. ICDE 2010, Dong et al. VLDB 2009, Miao et al. PRICAI 2010 Applications of Trust Analysis Models • Quality Inference on User Generated Content (Annotator-Article graph) • Data fusion (data and sources) • News Finding (news articles-websites-topics) Conclusion • We reviewed the work in the data mining community on performing heterogeneous network-based trust analysis based on the data provided by multiple information sources for different objects. • We presented a classification of the approaches based on the network design used and the sub-problems solved. • We discuss various aspects of trust including the basic fact finder models, their extensions, source dependency models, logic based models, homogeneous trust network models, and semisupervised learning models. References References References Thanks!