Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
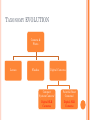
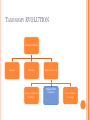
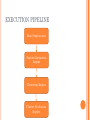
CLUSTERING FOR TAXONOMY EVOLUTION By -Anindya Das - Sneha Bankar PROBLEM STATEMENT Problem -Due to lack of correct category many a times products are placed in the wrong category -This could be an indication of taxonomy evolution Solution -Clustering products based on product descriptions TAXONOMY EVOLUTION Camera & Photo Lenses Flashes Digital Cameras Compact System Camera/ Point & Shoot Cameras/ Digital SLR Cameras Digital SLR Cameras TAXONOMY EVOLUTION Camera & Photo Lenses Flashes Compact System Camera Digital Cameras Digital SLR Camera Point & Shoot Cameras FEATURE EXTRACTION Use product description as features Brand Removal Stemming Use of unigrams and bigrams Feature Weighing based on Term Frequency Feature Weighing based on TFIDF HIERARCHICAL AGGLOMERATIVE CLUSTERING Initially, each item is considered a cluster. The closest pair is chosen. Those two clusters are merged. Each iteration reduces one cluster. Continues till terminating condition satisfies. No. of clusters Inter cluster Distance UPGMA used for measuring cluster distance. DISTANCE MEASURES Edit Distance Euclidean Distance Sum of square of weights of all disjoint features Jaccard Distance Min. operations to convert A into B 1− 𝑛(𝐴∩𝐵) 𝑛(𝐴∪𝐵) Hamming Distance 𝑛 𝐴− 𝐴∩𝐵 + 𝑛(𝐵 − (𝐴 ∩ 𝐵)) K-MEANS Select K initial centroids Assign data points(ASIN feature vector) to the centroids based on distances Update Mean for the Centroids Re-assign and update the centroids till data points can be reassigned EXECUTION PIPELINE Data Preprocessor Feature Extraction Engine Clustering Engine Cluster Evaluation Engine CLUSTER EVALUATION How many items in a cluster are talking about the top most frequent features of a cluster? Precision = true positives / (true positives + false positives) Recall = true positives /( true positives + false negatives) RESULTS Precision Values HAC K-Means Dataset 1 95% 92% Dataset 2 92% 96% Dataset 3 93% 90% Recall values for all cases lie between 20% to 30% FUTURE WORK Mining topics from product descriptions using them as features Approach to detect outliers and merge them to form a new category Use of association rule mining for evaluation instead of top frequent words REFERENCES http://en.wikipedia.org/wiki/Hierarchical_clusteri ng http://en.wikipedia.org/wiki/K-means_clustering Liu, Tao. "An Evaluation on Feature Selection for Text Clustering." N.p., 2003. Web.