Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Cache-Aware and Cache-Oblivious Adaptive
Sorting
Gerth Stølting Brodal1,⋆ , Rolf Fagerberg2, and Gabriel Moruz1
1
2
BRICS⋆⋆ , Department of Computer Science, University of Aarhus,
DK-8000 Århus C, Denmark. E-mail: {gerth,gabi}@brics.dk
Department of Mathematics and Computer Science, University of Southern
Denmark, DK-5230 Odense M, Denmark. E-mail: [email protected]
Abstract. This paper introduces two new adaptive sorting algorithms
which perform an optimal number of comparisons with respect to the
number of inversions in the input. The first algorithm is based on a new
linear time reduction to (non-adaptive) sorting. The second algorithm
is based on a new division protocol for the GenericSort algorithm by
Estivill-Castro and Wood. From both algorithms we derive I/O-optimal
cache-aware and cache-oblivious adaptive sorting algorithms. These are
the first I/O-optimal adaptive sorting algorithms.
1
Introduction
1.1
Adaptive sorting
A basic fact concerning sorting is that optimal comparison based sorting algorithms uses Θ(n log n) comparisons [9]. However, in practice there are many
cases where the input sequences are already nearly sorted, i.e. have low disorder
according to some measure. In such cases one can hope for the sorting algorithm
to be faster.
In order to quantify the disorder of input sequences, several measures of presortedness have been proposed. One of the most commonly considered measures
of presortedness is Inv , the number of inversions, defined by Inv (X) = |{(i, j) |
i < j ∧ xi > xj }| for a sequence X = (x1 , . . . , xN ). Other measures of presortedness have been proposed, e.g. see [11, 16, 18]. A sorting algorithm is denoted
adaptive if the time complexity is a function dependent on the size as well as
the presortedness of the input sequence [19]. For a survey concerning adaptive
sorting, see [13].
Manilla [18] introduced the concept of optimality of an adaptive sorting algorithm. An adaptive sorting algorithm S is optimal with respect to some measure
of presortedness D, if for some constant c > 0 and for all inputs X, the time
complexity TS (X) satisfies:
TS (X) ≤ c · max(|X|, log |below(X, D)|) ,
⋆
⋆⋆
Supported by the Carlsberg Foundation (contract number ANS-0257/20).
Basic Research in Computer Science, www.brics.dk, funded by the Danish National
Research Foundation.
where below(X, D) = {Y | Y is a permutation of {1, . . . , |X|} ∧ D(Y ) ≤ D(X)}.
An optimal adaptive sorting algorithm with respect to the measure Inv performs
Θ(n(log( Inv
n + 1) + 1) comparisons [15].
1.2
The I/O model and the cache-oblivious model
Traditionally, the RAM model has been used in the design and analysis of algorithms. It consists of a CPU and an infinite memory, in which all memory
accesses are assumed to take equal time. However, this model is not always adequate in practice, due to the memory hierarchy found on modern computers.
Modern computers have many memory levels, each level having smaller size and
access time than the next one. Typically, a desktop computer contains CPU
registers, L1, L2, and L3 caches, main memory and hard-disk. The access time
increases from one cycle for registers and level 1 cache to around 10, 100 and
1,000,000 cycles for level 2 cache, main memory and disk, respectively. Therefore, the I/Os of the disk often become a bottleneck with respect to the runtime
of a given algorithm, and I/Os, not CPU cycles, should be minimized.
Several models have been proposed in order to capture the effect of memory
hierarchies. The most successful of these is the I/O model, introduced by Aggarwal and Vitter [2]. It models a simple two-level memory hierarchy consisting of
a fast memory of size M and a slow infinite memory. The data transfers between
the slow and fast memory are performed in blocks of size B of consecutive data,
see Figure 1. The I/O complexity of an algorithm is the number of transfers it
performs between the slow and the fast memories. A comprehensive list of I/O
efficient algorithms for different problems have been proposed (see the surveys
by Vitter [21] and Arge [1]). Among the fundamental results for the I/O model
N
is that sorting a sequence of N elements requires Θ( N
B logM/B B ) I/Os [2].
The I/O model assumes that the size M of the fast memory and the block
size B are known, which does not always hold in practice. Moreover, as the
modern computers have multiple memory levels with different sizes and block
sizes, different parameters are required at the different memory levels. Frigo et
al. [14] proposed the cache-oblivious model, which is similar to the I/O model,
but assumes no knowledge about M and B. In short, a cache-oblivious algorithm
is an algorithm described in the RAM model, but analyzed in the I/O model with
an analysis valid for any values of M and B. The power of this model is that
if a cache-oblivious algorithm performs well on a two-level memory hierarchy
with arbitrary parameters, it performs well between all the consecutive levels
of a multi-level memory hierarchy. If the analysis of a cache-oblivious algorithm
shows it to be I/O optimal (up to a constant factor), it uses an optimal number
of I/Os for all levels of a multi-level memory hierarchy [14].
Many problems have been addressed within the cache-oblivious model (for
details, see the surveys by Arge et al. [3], Brodal [7], and Demaine [10]). Among
these are several optimal cache-oblivious sorting algorithms. Frigo et al. [14] gave
two optimal cache-oblivious algorithms for sorting: Funnelsort and a variant
of Distributionsort. Brodal and Fagerberg [6] introduced a simplified version
of Funnelsort, Lazy Funnelsort. The I/O complexity of all these algorithms is
N
O( N
). All these algorithms require a tall cache assumption, i.e. M ≥
B log M
B B
1+ε
B
for a constant ε > 0. In [8] it is shown that a tall cache-assumption is
required for all optimal cache-oblivious sorting algorithms.
Results and outline of paper
In Section 2 we introduce the concepts of I/O-adaptiveness and I/O-optimality.
We apply the result from [4] to obtain lower bounds for sorting algorithms that
are adaptive with respect to different measures of presortedness.
In Section 3 we present a linear time reduction from adaptive sorting to
general (non-adaptive) sorting, directly implying time optimal and I/O-optimal
cache-aware and cache-oblivious algorithms with respect to measure Inv .
In section 4 we describe a cache-aware generic sorting algorithm, cache-aware
GenericSort based on GenericSort, introduced in [12], and characterize its I/O
adaptiveness. Section 5 introduces the cache-oblivious version of cache-aware
GenericSort.
In Section 6 we introduce a new greedy division protocol for GenericSort,
interesting in its own right due to its simplicity. We prove that the resulting
algorithm, GreedySort, is time optimal with respect to measure Inv. We also
show that using our division we can easily obtain both cache-aware and cacheoblivious optimal algorithms with respect to Inv .
2
I/O-adaptiveness and I/O-optimality
We now define the concepts of I/O-adaptiveness and the I/O-optimality with
respect to some measure of presortedness of a sorting algorithm.
Definition 1. A sorting algorithm A is I/O adaptive with respect to the measure
of presortedness D if the I/O complexity of A depends both on the size of the
input sequence and the presortedness D.
We define the I/O-optimality of a sorting algorithm with respect to some
measure of presortedness analogously to the optimality definition in [18] for
comparison-based sorting algorithms. Let X be an input sequence let D be a
measure of presortedness. Consider the set of all permutations Y for the input
sequence with D(Y ) ≤ D(X), denoted by below(X, D.
For a comparison based sorting algorithm A, consider its decision tree (see
[9]) restricted to the inputs in below(X, D). The tree has at least |below(X, D)|
leaves and therefore A must perform at least log |below(X, D)| comparisons in
the worst case.
Arge et al. [4] introduced a general method for converting lower bounds on
the number of comparisons into lower bounds on the number of I/Os for sorting
algorithms.
Theorem 1 ([4, Theorem 1]). Let A be a sorting algorithm and I/OA (X)
the number of I/Os performed by A to sort an input sequence X. There exists a
comparison decision tree TA such that for all input sequences X:
|pathTA (X)| ≤ n log B + I/OA (X) · Tmerge (M − B, B)
where Tmerge (m, n) denotes the number of comparisons required to merge two
sorted lists of length m and n respectively.
We know that any sequence X there exists a sequence Y ∈ below(X,
mathcalD) such that log |below(X, D)| ≤ |pathTA (Y )|.
Using Theorem 1, we obtain that for all input sequences X there is an input
sequence Y ∈ below(X, D) such that:
|pathTA (X)| ≤ |X| log B + I/OA (X) · Tmerge (M − B, B) ,
log(|below(X, D)|) ≤ |pathTA (Y )|
where Tmerge (n1 , n2 ) denotes the number of comparisons needed for merging two
sorted sequences of sizes n1 and n2 respectively.
Since any sorting algorithm has to scan the entire input, this leads to the
following definition.
Definition 2. Let A be a sorting algorithm and D a measure of presortedness.
A is denoted I/O − optimal with respect to measure D if there is a constant
c > 0 such that for all inputs X:
|X| maxY ∈below(X,D) |pathTA (Y )| − |X| log B
I/OA (X) ≤ c · max
,
B
Tmerge (M − B, B)
Lemma 1 gives a lower bound for the number of I/Os performed by sorting
algorithms adaptive with respect to Inv .
Lemma 1. A sorting algorithm performs Ω( N
(1 +
B (1 + log M
B
sorting an input sequence of size N .
Inv
N B )))
I/Os for
Proof. Consider an adaptive sorting algorithm A and some input sequence
X with |X| = N . Let I/OA (X) be the number of I/Os required by
A to sort X. Using the Corollary 1 in [4] and the fact [16] that
Tmerge (M − B, B) ≥ B log(M/B) + 3B, we obtain:
M
log(|below(X, Inv )|) ≤ N log B +
max
I/OA (Y ) B log
+ 3B .
B
Y ∈below(X,Inv )
Since log(|below(X, Inv )|) = Ω(N (1 + log(1 + Inv
N )) [15], we have:
Inv
N
1 + log M 1 +
.
max
I/OA (Y ) = Ω
B
B
NB
Y ∈below(X,Inv )
⊓
⊔
Using a similar technique we obtain lower bounds on the number of I/Os
performed for other measures of presortedness, introduced in Figure 2. See [13]
for a definition of the measures of presortedness.
3
GroupSort
In this section we describe a reduction to derive Inv adaptive sorting algorithms
from non-adaptive sorting algorithms. The reduction is cache-oblivious and requires O(N ) comparisons and O(N/B) I/Os.
The basic idea is to distribute the input sequence into a sequence of buckets
S1 , . . . , Sk each of size at most (Inv/N )O(1) , where the elements in bucket Si
are all smaller than or equal to the elements in Si+1 . Each Si is then sorted independently by a non-adaptive cache-oblivious sorting algorithm [6, 14]. During
the construction of the buckets S1 , . . . , Sk some elements can fail to get inserted
into an Si and are instead inserted into a fail set F . It will be guaranteed that at
most half of the elements are inserted into F . The fail set F is sorted recursively
and merged with the sequence of sorted buckets.
The Si buckets are constructed by scanning the input left-to-right and inserting an element x into the rightmost bucket Sk if x ≥ min(Sk ) and otherwise
insert x in F . During the construction we keep increasing bucket capacities
βj = 2 · 4j , which will be used for αj = N/(2 · 2j ) insertions into F . If |Sk | > βj
the bucket Sk is split into Sk and Sk+1 by computing its median using the cacheoblivious selection algorithm from [5] and distributing its elements relatively to
the median. This ensures |Si | ≤ βj for 1 ≤ i ≤ k. We will maintain the invariant
|Sk | ≥ βj /2 if there are at least two buckets.
The pseudo-code of the reduction is given in Figure 3. We assume that
S1 , . . . , Sk are stored consecutively in an array by storing the start index and the
minimum element from each bucket on a separate stack, i.e. the concatenation
of Sk−1 and Sk can done implicitly in O(1) time. Similarly F1 , . . . , Fj are stored
consecutively in an array.
Theorem 2. GroupSort is cache-oblivious and is comparison optimal and I/Ooptimal with respect to Inv , assuming M = Ω(B 2 ).
Proof. Consider the last bucket capacity βj and fail set size αj . Each element x
inserted into the fail set Fj induces in the input sequence at least βj /2 inversions,
since |Sk | ≥ βj /2 when x is inserted into Fj and all element in Sk appear before x
in the input and are larger than x.
βi
N
2·4i
For i = ⌈log Inv
N ⌉+1, we have αi · 2 ≤ 2·2i · 2 ≤ Inv , i.e. Fi is guaranteed to
⌉+1,
be able to store all failed elements. This immediately leads to j ≤ ⌈log Inv
Pj
Pj N
Inv 2
j
and βj = 2·4 ≤ 32 N
. The fail set F has size at most i=1 αi = i=1 N/(2·
2i ) ≤ N/2.
Taking into account the total size of the fail sets is at most N/2, the number of
comparisons performed by GroupSort is given by the following recurrent formula:
T (N ) = T
N
2
+
k
X
TSort (|Si |) + O(N ) ,
i=1
where the O(N ) term accounts for the bucket splittings and the final merge of S
and F . The O(N ) term for splitting buckets follows from that when a bucket is
split then at least βj /4 elements in a bucket have been inserted since the most
recent bucket splitting of increase in bucket capacity, and we can charge the
splitting of the bucket to these recent βj /4 elements.
2
Since TSort (N ) = O(N log N ) and each |Si | ≤ βj = O(( Inv
N ) ) the number of
comparisons performed by GroupSort is:
2 !!!
Inv
N
+ O N 1 + log 1 +
T (N ) = T
.
2
N
It follows that GroupSort performs T (N ) = O N 1 + log 1 + Inv
, comparN
isons, which is optimal.
The cache-oblivious selection algorithm from [5] performs O(N/B) I/Os and
N
the cache-oblivious sorting algorithms [6, 14] perform O( N
B logM/B B ) I/Os for
M = Ω(B 2 ). Since GroupSort otherwise does sequential access to the input and
data structures, we get that GroupSort is cache-oblivious and the number of
I/Os performed is given by:
!!!
2
N
N
Inv
TI/O (N ) = TI/O
+O
1 + logM/B 1 +
/B
.
2
B
N
(1 +
It follows that GroupSort performs O( N
B (1 + log M
B
2
I/O-optimal for M ≥ B .
Inv
N )))
I/Os, which is
⊓
⊔
Pagh et al. [20] gave a related reduction for adaptive sorting on the RAM
model. Their reduction assumes that a parameter q is provided such that the
number of inversions is at most qN . A valid q is found by selecting increasing
values for q such that the running time doubles for each iteration. In the cache
oblivious setting the doubling approach fails, since the first q value should depend
on the unknown parameter M . We circumvent this limitation of the doubling
technique by selecting the increasing βj values internally in the reduction.
4
Cache-aware GenericSort
Estivill-Castro and Wood [12] introduced a generic sorting algorithm, GenericSort, as shown in Figure 4. It is a generalization of Mergesort, and is described
using a generic division protocol, i.e. an algorithm for separating an input sequence into two or more subsequences. A particular division protocol gives a
particular version of the algorithm, and different division protocols may give
different adaptive properties.
We modify the original GenericSort such that we achieve a generic I/Oadaptive sorting algorithm. Consider some input sequence X = (x1 , . . . , xN )
and DP some division protocol such that DP splits the input sequence in s ≥ 2
subsequences of roughly equal sizes in a single scan and visiting each element of
the input exactly once. We derive a new division protocol DP ′ by modifying DP
to identify the longest sorted prefix of X: we scan the input sequence until we find
some i such that xi < xi−1 . Denote S = (x1 , . . . , xi−1 ) and X ′ = (xi , . . . , xN ).
We apply DP only to X ′ , as we know S is sorted.
Let T be the recursion tree of GenericSort and DP ′ the new division protocol. We obtain a new tree T ′ by contracting T such that every node in T ′
M
has a fanout of ⌊ 2B
⌋. It follows immediately that each node in T ′ corresponds
M
to a subtree of height O(logs M
B ) in T and that there are O( B ) sorted subse′
′
quences corresponding to every node in T . For each node of T , we scan its input
sequence and distribute it accordingly to one of the O( M
B ) output sequences.
Theorem 3 is gives a an adaptive characterization of cache-aware GenericSort
in the I/O model.
Theorem 3. Let D be a measure of presortedness, d and s constants, 0 < d < 2
M
and s ≤ 2B
, and DP a division protocol that splits some input sequence of length
N into s subsequences of size O( Ns ) each using O( N
B ) I/Os. If DP performs the
splitting in one scan visiting each element of the input exactly once, then:
– cache-aware GenericSort is worst case optimal; that is, it performs O( N
B log M
B
I/Os in the worst case;
– if for all sequences X, DP satisfies that for the division of X into X1 , . . . , Xs :
s
X
s
D(Xj ) ≤ d⌊ ⌋ · D(X) ,
2
j=1
then cache-aware GenericSort performs O
is A is adaptive with respect to D.
|X|
B (1
+ log M D(X)) I/Os, that
B
Proof. We follow the proof in [12]. Consider some input sequence X, DP the
division protocol in GenericSort and DP ′ our division protocol. Taking into
account that DP splits the input sequence visiting each element of the input
once, DP ′ can also split the input visiting each element once.
Considering that at each node in T ′ cache-aware GenericSort performs O( N
B)
)
it
follows
immediately
that
cache-aware
I/Os and the fanout of T ′ is Θ( M
B
N
) I/Os.
GenericSort is worst case optimal as it performs O( N
B log M
B B
We prove the adaptive bound by induction after the length of the input
sequence. For DP ′ let S1 , . . . , Sm−1 be the sorted sequences and X1 , . . . , Xm
the unsorted sequences corresponding to a node in T ′ , m = Θ( M
B ). Also, denote
kj = D(Xj ), k = D(X) and I/O(N, k) the number of I/Os performed for some
input X with |X| = N and D(X) = k.
The base case of the induction occurs when at some node in T ′ all the elements in the input are distributed among the sorted subsequences Si . In this
N
case I/O(N, k) = O( N
B ) = O( B (1 + log M (1 + k))).
B
(1 + k ′ ))) for all N ′ < N and for
Assume that I/O(N ′ , k ′ ) = O( N
B (1 + log M
B
′
all k < max|X|=n D(X).
N
B)
P
If DP splits an input sequence X in s subsequences such that sj=1 D(Xj ) ≤
Pm
d⌊ 2s ⌋·D(X), then for each node in T ′ the following inequality holds: j=1 D(Xj ) ≤
(d⌊ 2s ⌋)logs m D(X)).
Let c be constants such that I/O(N ′ , k ′ ) ≤ c · ( N
(1 + k ′ ))) for
B (1 + log M
B
all N ′ < N and for all k ′ < max|X|=n D(X). Also, assume that splitting the
N
input in the Θ( M
B ) subsequences and merging takes at most a B I/Os, for some
constant a.
We have that:
m
I/O(n, k) ≤ a
=
m
N X N
N X N
T ( , kj ) ≤ a +
c
+
(1 + logm (1 + kj ))
B j=1 m
B j=1 mB
m
m
m
X
Y
1
1
aN
cN X 1
cN
aN
logm (1 + kj ) m ) =
(1 + kj ) m )
+
(
+
+
(1 + logm
B
B j=1 m j=1
B
B
j=1
Pm
m
X
(1
+
k
)
j
cN
aN
cN
aN
j=1
kj )
+
(1 + logm
)≤
+
(1 + logm
B
B
m
B
B
j=1
≤
aN
cN
s
aN
cN
s
+
(1 + logm ((d⌊ ⌋)logs m k)) ≤
+
(1 + logm k + logs d⌊ ⌋)
B
B
2
B
B
2
N
= O( (1 + log M k)).
B
B
⊓
⊔
5
Cache-oblivious GenericSort
We give a cache-oblivious algorithm that achieves the same adaptive bounds as
the cache-aware GenericSort introduced before. It works only for those division
protocols that split the input into two subsequences.
We store the recursion tree of the cache-aware GenericSort as a k − merger,
as introduced in [14]. A k − merger is a binary tree stored in the van Emde Boas
layout. Each edge in this tree stores a buffer. The tree and the buffer sizes are
recursively defined as follows: consider an input sequence of size N and h the
1
height of the tree. We split the tree at level h2 yielding N 2 + 1 subtrees, each of
1
1
size O(N 2 ). The buffers at this level have sizes N 2 .
Each node receives some input sequence from its parent and splits it in the
three subsequences. The unsorted subsequences are stored in the buffers to its
children, whereas the sorted subsequence is stored as a linked list of memory
2
chunks, each of them having the size of N 3 , where N is the size of the input,
see Figure A. All the memory chunks representing the sorted subsequences are
stored as a linked list.
The algorithm takes the input and fills the buffers in the recursion tree in a
top-down fashion and then merges the resulted sorted subsequences in a bottomup manner.
Lemma 2. The linked list containing the unsorted subsequences of the cacheoblivious GreedySort uses O(N ) extra space.
2
Proof. Every node with an input buffer size N uses N 3 extra space. We analyze
the extra space for a problem size N excluding the input buffer. At the middle
1
level of the recursion tree we have O(N 2 ) nodes, each having an input buffer
1
1
of size N 2 . Taking into account that each node uses N 3 extra space, we obtain
that the total amount of extra space is given by:
1
1
T (N ) = N 3 T (N 2 ) ,
which yields T (N ) = O(N ). Adding the top level recursion that consumes
2
O(N 3 ) extra space, we conclude that our linked list uses O(N ) extra space. ⊓
⊔
Lemma 3. Cache-oblivious GenericSort has the same time and I/O complexity
as cache-aware Generic sort, for division protocols that split the input into two
subsequences.
Proof. The cache-oblivious GenericSort performs the same number of comparisons as cache-aware GenericSort because its recursion tree is the same one used
by the cache-aware GreedySort. Therefore the time complexity of the two algorithms is the same.
We analyze the number of I/Os performed by cache-oblivious GenericSort.
The algorithm spends no I/Os when the size of the recursive tree reaches O(M ).
Taking into account that a k − merger uses O(k 2 ) space and that M = Ω(B 2 ),
we obtain that the height of the recursive tree in the base case is O(log M
B ).
Each element is pushed down the recursion tree until it is stored in a linked
list. Therefore, if an element xi reaches level di in the recursion tree of cacheaware GenericSort, at most ⌊ logdiM ⌋ + 1 I/Os will be performed by the cacheB
oblivious GenericSort for getting di to its sorted subsequence.P
Therefore the number of I/Os performed by cache-oblivious GenericSort is O(( ni=1 di ))/(log M
B )).
For Pcache-aware GenericSort the number of I/Os performed is still
n
O(( i=1 di )/(log M
B )) because each node in the contracted tree corresponds
M
O(log B ) levels in the recursion tree of GenericSort. Therefore, cache-aware
GenericSort and cache-oblivious GenericSort have the same I/O complexity. ⊓
⊔
6
GreedySort
We introduce GreedySort, a sorting algorithm based on the GenericSort described in the previous section combined with a new division protocol. The
protocol is inspired by a variant of the Kim-Cook division protocol, which was
analyzed in [17]. The current division protocol achieves the same adaptive performance, but is very simple and moreover facilitates cache-aware and cacheoblivious versions. It may be viewed at being of a greedy type, hence the name.
We first describe GreedySort and its division protocol and then prove that it is
optimal with respect to Inv .
Our division protocol partitions the input sequence X into three subsequences
S, A and B, where S is sorted and A and B have balanced sizes, i.e. |B| ≤ |A| ≤
|B| + 1. In one scan it builds an ascending subsequence S of the input in a
greedy fashion and in the same time distributes the remaining elements in two
subsequences, A and B, using an odd-even approach. The pseudo-code of our
division protocol, called GreedySplit, and of the sorting algorithm GreedySort, is
shown in Figures A and 6.
Lemma 4. Greedysplit splits an input sequence X in the three subsequences S,
A and B, where S is sorted and Inv (X) ≥ 54 · (Inv (A) + Inv(B)).
Proof. Denote X = (x1 , . . . xN ). By construction S is sorted. Consider an inversion in A, ai > aj , i < j and i1 and j1 the indices in X of ai and aj respectively.
Due to the odd-even construction of A and B, there exists an xk ∈ B such that
in the original sequence X we have i1 < k < j1 .
We prove that there is one inversion between xk and at least one of xi1 and
xj1 , for any i1 < k < j1 . Indeed, if xi1 > xk , we get an inversion between
xi1 and xk . If xi1 ≤ xk , we get an inversion between xj1 and xk , because we
assume that ai > aj which yields xi1 > xj1 . Let bi , . . . , bj−1 be all the elements
from B which appear between ai and aj in the original sequence. We know that
there exists at least an inversion between b(i+j)/2 and ai or aj . The inversion
(ai , b(i+j)/2 ) can be counted for two different pairs in A, (ai , ai+2⌊(j−i)/2⌋ ) and
(ai , ai+1+2⌊(j−i)/2⌋ ). Similarly, the inversion (b(i+j)/2 , j) can be counted for two
different pairs in A. Taking into account that the inversions involving elements
of A and elements of B appear in X, but neaither in A and B, we obtain:
Inv (X) ≥ Inv (A) + Inv (B) +
Inv (A)
.
2
(1)
Inv (B)
.
2
(2)
In a similar manner we get:
Inv (X) ≥ Inv (A) + Inv (B) +
Summing (1) and (2) we obtain:
Inv (X) ≥
5
(Inv (A) + Inv (B)) .
4
⊓
⊔
Theorem 4. GreedySort sorts a sequence X of length N using O(N (1 + log(1 +
Inv (X)
))) comparisons, therefore it is time optimal with respect to Inv .
N
Proof. Similar to [17], we first prove the claimed bound for the upper levels of
recursion where the total number of inversions is greater than N/4 and then
prove that the total number of comparisons for the remaining levels is linear.
Let Invi (X) denote the total number of inversions in the subsequences at the
ith level of recursion. We want to find the first level ℓ of the recursion for which:
ℓ
N
4
Inv(X) ≤
,
5
4
which is
ℓ=
log(4Inv(X)/N )
log(5/4)
.
By Lemma 4, we have Inv ℓ (X) ≤ N/4. At each level of recursion GreedySort
performs O(N ) comparisons. Therefore on the first ℓ levels of recursion the total
number of comparisons performed is:
Inv (X)
.
O(ℓ · N ) = O N 1 + log 1 +
N
We now prove that the remaining levels perform a linear number of comparisons.
Let |(X, i)| denote the total length of A’s and B’s at level i of the recursion.
As each element in A and B is obtained as a result of an inversion in the sequence
X, we have |(X, i)| ≤ Invi−1 (X). Using Lemma 4 we obtain:
i−1
i−1 ℓ
N
4
4
4
·
· Inv (X) ≤
.
|(X, ℓ + i)| ≤ Inv ℓ+i−1 (X) ≤
5
5
5
4
Taking into account that the sum of the |(X, ℓ + i)|’s is O(n) and that at each
level ℓ + i we perform a linear number of comparisons with respect to |(X, ℓ + i)|,
we conclude that the total number of comparisons performed at the lower levels
of the recursion tree is O(N ). We conclude that GreedySort performs O(N (1 +
⊓
⊔
log(1 + Inv
N ))) comparisons.
We show that it is easy to derive both cache-aware and cache-oblivious algorithms by plugging our greedy division protocol into the both cache-aware
and cache-oblivious GenericSort frameworks. In both cases the division protocol
considered does not identify the longest prefix of the input, but simply apply
the greedy division protocol. We prove that these new algorithms, cache-aware
GreedySort and cache-oblivious GreedySort achieve the I/O-optimality with respect to Inv under the tall cache assumption M = Ω(B 2 ).
Theorem 5. Cache-aware GreedySort and cache-oblivious GreedySort are I/Ooptimal with respect to Inv , provided that M = Ω(B 2 ).
Proof. Consider some input sequence X, with |X| = N . We observe that under
the assumption M = Ω(B 2 ) we have:
I/O = Ω(
Inv
N
Inv
N
(1 + log M (1 +
))) = Ω( (1 + log M (1 +
)))
B
B
B
NB
B
N
Following the proof of Theorem 4, we immediately obtain the I/O-complexity
for the cache-aware GreedySort to be Θ( N
(1 + Inv
B (1 + log M
N ))), which is optiB
mal. Taking into account that the cache-aware GenericSort and cache-oblivious
GenericSort have the same I/O complexities, we conclude that both cache-aware
GreedySort and cache-oblivious GreedySort are I/O-optimal.
⊓
⊔
References
1. J. Abello, P.M. Pardalos, and M. G. C. Resende. Handbook of Massive Data Sets,
pages 313–358. Kluwer Academic Publishers, 2002.
2. A. Aggarwal and J. S. Vitter. The input/output complexity of sorting and related
problems. Communications of the ACM, 31(9):1116–1127, 1988.
3. L. Arge, G. S. Brodal, and R. Fagerberg. Cache-oblivious data structures. In Dinesh
Mehta and Sartaj Sahni, editors, Handbook of Data Structures and Applications,
page 27. CRC Press, 2004.
4. L. Arge, M. Knudsen, and K. Larsen. A general lower bound on the I/O-complexity
of comparison-based algorithms. In Proceedings of Workshop on Algorithms and
Data Structures, 1993.
5. Manuel Blum, Robert W. Floyd, Vaughan Pratt, Ronald L. Rivest, and Robert Endre Tarjan. Time bounds for selection. Journal of Computer and System Sciences,
7:448–461, 1973.
6. G. S. Brodal and R. Fagerberg. Cache oblivious distribution sweeping. In Proc.
29th International Colloquium on Automata, Languages, and Programming, volume
2380 of Lecture Notes in Computer Science, pages 426–438. Springer Verlag, Berlin,
2002.
7. Gerth Stølting Brodal. Cache-oblivious algorithms and data structures. In Proc.
9th Scandinavian Workshop on Algorithm Theory, Lecture Notes in Computer
Science. Springer Verlag, Berlin, 2004.
8. Gerth Stølting Brodal and Rolf Fagerberg. On the limits of cache-obliviousness.
In Proc. 35th Annual ACM Symposium on Theory of Computing, pages 307–315,
2003.
9. Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein.
Introduction to Algorithms, 2nd Edition. MIT Press, 2001.
10. E. Demaine. Cache-oblivious algorithms and data structures. Lecture Notes from
the EEF Summer School on Massive Data Sets, 2002.
11. V. Estivill-Castro and D. Wood. A new measure of presortedness. Information
and Computation, 83(1):111–119, 1989.
12. V. Estivill-Castro and D. Wood. Practical adaptive sorting. In Advances in Computing and Information - Proceedings of the International Conference on Computing and Information, pages 47–54. Springer-Verlag, 1991.
13. V. Estivill-Castro and D. Wood. A survey of adaptive sorting algorithms. ACM
Computing Surverys, 24(4):441–475, 1992.
14. M. Frigo, C. E. Leiserson, H. Prokop, and S. Ramachandran. Cache oblivious
algorithms. In 40th Annual IEEE Symposium on Foundations of Computer Science,
pages 285–298. IEEE Computer Society Press, 1999.
15. L. J. Guibas, E. M. McCreight, M. F. Plass, and J. R. Roberts. A new representation of linear lists. In Proc. 9th Ann. ACM Symp. on Theory of Computing, pages
49–60, 1977.
16. D. E. Knuth. The Art of Computer Programming. Vol 3, Sorting and searching.
Addison-Wesley, 1973.
17. C. Levcopoulos and O. Petersson. Splitsort – an adaptive sorting algorithm. Information Processing Letters, 39(1):205–211, 1991.
18. H. Manilla. Measures of presortedness and optimal sorting algorithms. IEEE
Trans. Comput., 34:318–325, 1985.
19. K. Mehlhorn. Data structures and algorithms. Vol. 1, Sorting and searching.
Springer, 1984.
20. Anna Pagh, Rasmus Pagh, and Mikkel Thorup. On adaptive integer sorting. In
Proc. 12th Annual European Symposium on Algorithms, volume 3221, pages 556–
567. 2004.
21. J. S. Vitter. External memory algorithms and data structures: Dealing with massive data. ACM Computing Surveys, 33(2):209–271, 2001.
A
List of figures
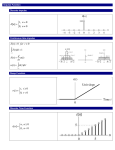
Slow memory
Fast memory
Block
CPU
Fig. 1. The I/O model.
Measure of pre- Lower bound
sortedness
1 + log M 1 +
Dis
Ω N
B
B
Exc
Ω
Enc
Ω
Inv
Ω
Max
Ω
Osc
Reg
Rem
Ω
Ω
Ω
Runs
Ω
SMS
Ω
SUS
Ω
N
B
N
B
N
B
N
B
N
B
N
B
N
B
N
B
N
B
N
B
Dis
B
(1+Exc)Exc
B
B
1 + log M
1 + log M 1 +
B
1 + log M 1 +
B
1 + log M 1 +
B
1 + log M 1 +
B
1 + log M 1 +
B
1 + log M
B
B
1 + log M 1 +
B
1 + log M 1 +
B
Enc
B
Inv
NB
M ax
B
Osc
NB
Rem
Reg
B
(1+Rem)
B
1 + log M 1 +
Runs
B
SM S
B
SU S
B
Fig. 2. Lower bounds on the number of I/Os for different measures of presortedness.
procedure GroupSort(X)
Input: Sequence X = (x1 , . . . , xN )
Output: Sequence X sorted
begin
S1 = (x1 ), F1 = ();
β1 = 8; α1 = N/4, j = 1; k = 1;
for i = 2 to N
if xi ≥ min(Sk )
append(Sk , xi );
if |Sk | > βj
(Sk , Sk+1 ) = split(Sk ); k = k + 1;
else
if |Fj | ≥ αj
βj+1 = βj · 4; αj+1 = αj /2; j = j + 1;
while k > 1 and |Sk | < βj /2
Sk−1 = concat(Sk−1 , Sk ); k = k − 1;
append(Fj , xi );
S = concat(sort(S1 ), sort(S2 ), . . . , sort(Sk ));
F = concat(F1 , F2 , . . . , Fj );
GroupSort(F );
X = merge(S, F );
end
Fig. 3. Linear time reduction to non-adaptive sorting
procedure GenericSort(X)
Input: X, the sequence to be sorted
Output:X, the sorted input sequence
begin
if X is sorted then return
else if X is small then sort it using some simple sorting algorithm
else
Apply a division protocol to divide X into s ≥ 2 disjoint subsequences
Recursively sort the subsequences using GenericSort
Merge the sorted subsequences
end
Fig. 4. GenericSort
procedure Greedysplit(X, S, A, C)
Input: X the sequence to be partitioned
Output: S the sorted subsequence,
A and C the unsorted
balanced subsequences
begin
S = (x1 ), A = (), C = ()
for i = 2 to |X|
if xi > f ront(S) then
append(S, xi )
else
if |A| = |C| then
append(A, xi )
else
append(C, xi )
end
procedure GreedySort(X)
Input: X the sequence to be sorted
Output:X the sorted input sequence
begin
if X is small
sort X using an alternative sorting algorithm
return
else
Greedysplit(X, S, A, C)
if |S| = |X|
return
else
GreedySort(A)
GreedySort(C)
X = merge(S, A, C)
end
Fig. 5. Greedy division protocol
Fig. 6. GreedySort
Sorted subsequences
...
. . .
1
Buffer size n 2
Fig. 7. Cache-oblivious GenericSort