Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
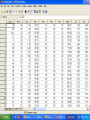
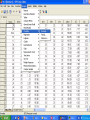
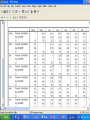
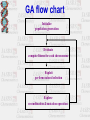
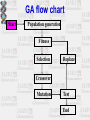
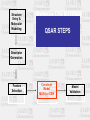
In the name of GOD Basic Steps of QSAR/QSPR Investigations M.H. FATEMI Mazandaran University [email protected] QSAR • Qualitative Structure-Activity Relationships • Can one predict activity (or properties in QSPR) simply on the basis of knowledge of the structure of the molecule? • In other, words, if one systematically changes a component, will it have a systematic effect on the activity? What is QSAR? A QSAR is a mathematical relationship between a biological activity of a molecular system and its geometric and chemical characteristics. QSAR attempts to find consistent relationship between biological activity and molecular properties, so that these “rules” can be used to evaluate the activity of new compounds. Why QSAR? The number of compounds required for synthesis in order to place 10 different groups in 4 positions of benzene ring is 104 Solution: synthesize a small number of compounds and from their data derive rules to predict the biological activity of other compounds. QSXR X=A X=P X=R Activity Property Retention X= bo+ b1D1+ b2D2+…..+ bnDn bi regression coefficient Di descriptors n number of descriptors History Early Examples • Hammett (1930s-1940s) COOH X COOH X COOH X X para = log10 Kp K0 meta = log10 Km K0 COO + H K0 COO + H Kp COO + H Km Hammett (cont.) • Now suppose have a related series X CH2COOH CH2COO X log10 K'x = r K'0 reflect sensitivity to substituent r reflect sensitivity to different system +H K'x Free-Wilson Analysis • Log 1/C = S ai + m where C=predicted activity, ai= contribution per group, and m=activity of reference Free-Wilson example Br X N Y HCl activity of analogs Log 1/C = -0.30 [m-F] + 0.21 [m-Cl] + 0.43 [m-Br] + 0.58 [m-I] + 0.45 [m-Me] + 0.34 [p-F] + 0.77 [p-Cl] + 1.02 [p-Br] + 1.43 [p-I] + 1.26 [p-Me] + 7.82 Problems include at least two substituent position necessary and only predict new combinations of the substituents used in the analysis. Hansch Analysis Log 1/C = a p + b + c where p(x) = log PRX – log PRH and log P is the water/octanol partition This is also a linear free energy relation Applications of QSAR • • • • • 1-Drug design 2-Prediction of Chemical toxicity 3-Prediction of environmental activity 4-Prediction of molecular properties 5-Investigation of retention mechanism Structure Entry & Molecular Modeling Steps in QSPR/QSAR QSAR STEPS Descriptor Generation Feature Selection Construct Model MLRA or CNN Model Validation Data set selection • 1-Structural similarity of studied molecules • 2-Data collected in the same conditions • 3-Data set would be as large as possible Structure Entry & Molecular Modeling Steps in QSPR/QSAR QSAR STEPS Descriptor Generation Feature Selection Construct Model MLRA or CNN Model Validation INTRODUCTION to Molecular Descriptors • Molecular descriptors are numerical values that characterize properties of molecules • Molecular descriptors encoded structural features of molecules as numerical descriptors • Vary in complexity of encoded information and in compute time • Examples: – Physicochemical properties (empirical) – Values from algorithms, such as 2D fingerprints Classical Classification of Molecular Descriptors O Constitutional, Topological 2-D structural formula * O CH2 CH2 O O CH2 CH2 NH CH O O CH2 OH Geometrical 3-D shape and structure Quantum Chemical Physicochemical Hybrid descriptors CH2 O n * Topological Indexes: Example: • Wiener Index • Counts the number of bonds between pairs of atoms and sums the distances between all pairs • Molecular Connectivity Indexes – Randić branching index • Defines a “degree” of an atom as the number of adjacent non-hydrogen atoms • Bond connectivity value is the reciprocal of the square root of the product of the degree of the two atoms in the bond. • Branching index is the sum of the bond connectivities over all bonds in the molecule. – Chi indexes – introduces valence values to encode sigma, pi, and lone pair electrons Electronic descriptors • Electronic interactions have very important roles in controlling of molecular properties. • Electronic descriptors are calculated to encode aspects of the structures that are related to the electrons • Electronic interaction is a function of charge distribution on a molecule Physicochemical Properties Used in this QSAR 1. Liquid solubility Sw,L in mg/L and mmol/m3 2. Octanol-water partition coefficient Kow 3. Liquid Vapor Pressure Pv,L in Pa 4. Henry’s Law constant Hc in Pa∙m3/mole 5. Boiling point Structure Entry & Molecular Modeling Steps in QSPR/QSAR QSAR STEPS Descriptor Generation Feature Selection Construct Model MLRA or CNN Model Validation Feature Selection • E.g. comparing faces first requires the identification of key features. • How do we identify these? • The same applies to molecules. Objective feature selection • After descriptors have been calculated for each compound, this set must be reduced to a set of descriptors which is as information rich but as small as possible 1- Deleting of constant or near constant descriptors 2- Pair correlation cut-off selection 3- Cluster analysis 4- Principal component analysis 5- K correlation analysis Descriptive Statistics N homo lumo dip mw mia mib mic polar x0 x1p x2p x3p x3c x4p x4c noa pcpa pcna edn edp dspn s hape volm s urf s 1zy s 2zx s 3xy s s1 s s2 s s3 logp bcf number Valid N (lis twis e) 55 55 55 55 55 55 55 54 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 54 55 53 Minimum .01 .02 .00 123.11 .02 .00 .00 63.45 4.07 2.20 1.41 .79 .10 .43 .14 12.00 .05 -.45 4.05 .75 .98 1.42 106.12 129.62 44.02 22.66 18.74 .57 .65 .64 1.49 1.02 1.00 Maximum 9.44 708.00 7.35 307.99 .19 .23 312.00 153.63 9.13 4.68 4.56 2.71 1.14 1.90 1.79 28.00 .58 -.05 6.37 6.95 6.94 3.93 218.34 262.24 80.88 56.08 38.74 .80 .92 .90 6.63 5.62 110.00 Mean .6524 13.2664 2.7035 192.4207 .0580 .0270 5.6900 95.7878 5.9576 3.1949 2.3626 1.4072 .2799 .8358 .4958 17.3091 .3319 -.2652 5.2470 2.5227 2.2400 2.6579 146.2387 175.1636 57.0065 31.9507 25.0053 .7089 .8291 .8080 3.6971 3.1893 37.5636 Std. Deviation 1.66861 95.41298 2.06794 42.41658 .03451 .03070 42.06771 23.58493 1.24159 .76452 .74960 .49032 .16722 .38795 .27697 4.11804 .19432 .11673 .99529 1.99339 1.62828 .43353 25.62153 28.52871 8.44310 7.16801 4.42347 .05104 .07153 .05988 1.19562 .84204 33.22246 Variable reduction • Principal Component Analysis Principal Component • PC1 = a1,1x1 + a1,2x2 + … + a1,nxn • PC2 = a2,1x1 + a2,2x2 + … + a2,nxn • Keep only those components that possess largest variation • PC are orthogonal to each other Subjective Feature Selection • • • • • • • The aim is to reach optimal model 1-Search all possible model (Best MLR) 2-Forward, Backward & Stepwise methods 3-Genetic algorithm 4-Mutation and selection uncover models 5-Cluster significance analysis 6-Leaps & bounds regression Feature Selection: Most existing feature selection algorithms consist of : Starting point in the feature space Search procedure Evaluation function Criterion of stopping the search Feature Selection: Starting point in the feature space - no features - all features - random subset of features Forward Selection • 1- variables are sequentially entered into the model. The first variable considered for entry into the equation is the one with the largest positive or negative correlation with the dependent variable. This variable is entered into the equation only if it satisfies the criterion for entry. 2-If the first variable is entered, the independent variable not in the equation that has the largest partial correlation is considered next. 3-The procedure stops when there are no variables that meet the entry criterion. Forward Selection example Model Summary Model 1 2 3 4 R R Square .704 a .496 .762 b .581 .810 c .655 .834 d .695 Adjus ted R Square .486 .564 .634 .670 a. Predictors : (Constant), logp b. Predictors : (Constant), logp, mw c. Predictors : (Constant), logp, mw, dip d. Predictors : (Constant), logp, mw, dip, mia Std. Error of the Es timate .59485 .54785 .50184 .47674 Backward Elimination • 1- All variables are entered into the equation and then sequentially removed. • 2-The variable with the smallest partial correlation with the dependent variable is considered first for removal. If it meets the criterion for elimination, it is removed. • 3- After the first variable is removed, the variable remaining in the equation with the smallest partial correlation is considered next. • 4-The procedure stops when there are no variables in the equation that satisfy the removal criteria. Stepwise • Stepwise. At each step, the independent variable not in the equation that has the smallest probability of F is entered, if that probability is sufficiently small. Variables already in the regression equation are removed if their probability of F becomes sufficiently large. The method terminates when no more variables are eligible for inclusion or removal. Stepwise Example Model Summary Model 1 2 3 4 5 R R Square .704 a .496 .762 b .581 .810 c .655 .834 d .695 .824 e .679 Adjus ted R Square .486 .564 .634 .670 .660 a. Predictors : (Constant), logp b. Predictors : (Constant), logp, mw c. Predictors : (Constant), logp, mw, dip d. Predictors : (Constant), logp, mw, dip, mia e. Predictors : (Constant), logp, dip, mia Std. Error of the Es timate .59485 .54785 .50184 .47674 .48403 Forward, Backward & Stepwise variable selection methods • Advantages • Fast and simple • Can do with very packages • Limitation • Risk of Local minima Genetic algorithm Genetic Algorithm Search Space Definition Genetic algorithm is a general purpose search and optimization method based on genetic principles and Darwin’s law that applicable to wide variety of problems Darvin’s rules Survival of fittest individuals Recombination Mutation Biological background • • • • • Chromosome Gene Reproduction Mutation Fitness GA basic operation • Population generation (chromosome ) • Selection (according to fitness ) • Recombination and mutation (offspring) • Repetition GA flow chart Initialize population generation Evaluate compute fitness for each chromosome Exploit perform natural selection Explore recombination & mutation operation Binary Encoding Every of chromosome is a string of bit 0 or 1 Chromosome A 1 0 1 1 0 0 1 1 1 0 0 0 0 1 Chromosome B 0 0 1 0 0 1 1 1 0 1 0 0 1 1 Selection The best chromosome should survive and create new offspring. • Roulette wheel selection • Rank selection • Steady state selection Roulette wheel selection Fitness 1> 2 > 3 >4 Crossover ( binary encoding ) *Single point 11001011+11011111 = 11001111 * Two point crossover 11001011 + 11011111 = 11011111 Mutation * Bit inversion (binary encoding ) 11001001 => 10001001 * Ordering change ( permutation encoding ) (1 2 3 4 5 6 8 9 7) => (1 8 3 4 5 6 2 9 7) GA flow chart Start Population generation Fitness Selection Replace Crossover Mutation Test End Parameters of GA • • • • • • Crossover rate Mutation rate Population size Selection type Encoding Crossover and mutation type Advantages of GA • • • • Parallelism Provide a group of potential solutions Easy to implement Provide global optima How many descriptors can be used in a QSAR model? Rule of tumb: - Per descriptor at least 5 data point (molecule) must be exist in the model Otherwise possibility of finding coincidental correlation is too high Structure Entry & Molecular Modeling Steps in QSPR/QSAR QSAR STEPS Descriptor Generation Feature Selection Construct Model MLRA or CNN Model Validation Questions?