Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
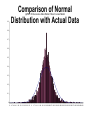
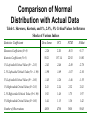
CHAPTER 3 Review of Statistics INTRODUCTION • The creation of histograms and probability distributions from empirical data. • The statistical parameters used to describe the distribution of losses: mean, standard deviation, skew, and kurtosis. • Examples of market-risk and credit-risk loss distributions to give an understanding of the practical problems that we face. • The idealized distributions that are used to describe risk: the Normal and Beta probability distributions. Construction of Probability Densities from Historical Data • Two Examples – The daily return rates of U.S. S&P 500 stock index – The daily return rates of Taiwan company: Acer 2353 Distribution of Return Rate for U.S. Market 0.35 Use 2-year data (near 500 daily return rates data) to simulate the underlying distribution of return rates of our portfolio Assume the return rate in the next trading day is drawn from the same distribution 0.3 0.25 Rt, for t=1 to 500 Rt, for t=501,502, … 0.2 If we assume the return rate follows the normal distribution, then the potential loss can be presented by standard error 0.15 Standard0.1 error, σ Standard error, σ 0.05 0 -4 -3 -2 -1 0 1 2 3 4 Distribution of Return Rate for U.S. Market (1)If we assume the return rate follows the normal distribution, then the potential loss can be presented by standard error 0.35 (2) The P[ return rate<-2.33Xσ]=1% The P[ return rate<-1.96Xσ]=2.5% 0.3 The P[ return rate<-1.645Xσ]=5% 0.25 (3) If we assume the initial investment amount is 100,000, the loss of ”>100,000X 2.33Xσ” in the next day0.2 will have 1% probability of occurrences 0.15 Standard0.1 error, σ Standard error, σ (0.94%) 0.05 0 -4 -3 -2 -1 0 1 2 3 4 DESCRIPTIVE STATISTICS: MEAN, STANDARD DEVIATION, SKEW, AND KURTOSIS • Mean • Standard Deviation DESCRIPTIVE STATISTICS: MEAN, STANDARD DEVIATION, SKEW, AND KURTOSIS • Skew • Kurtosis The Normal Distribution • The Noemal distribution is also known as the Gaussian distribution or Bell curve. • It is the distribution most commonly used to describe the random changes in market-risk factors, such as exchange rates, interest rates, and equity prices. • This distribution is very common in nature because of the Central Limit Theorem, which states that if a large amount of independent, identically distributed, random numbers are added together, the outcome will tend to be Normally distributed The Normal Distribution • The equation for the Normal distribution is as follows: Comparison of Normal Distribution with Actual Data (a)PDF of Dow Jones Index Return Shock: Linear Model 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 -5 -4.7 -4.4 -4.1 -3.8 -3.5 -3.2 -2.9 -2.6 -2.3 -2 -1.7 -1.4 -1.1 -0.8 -0.5 -0.2 0.12 0.42 0.72 1.02 1.32 1.62 1.92 2.22 2.52 2.82 3.12 3.42 3.72 4.02 4.32 4.62 4.92 Comparison of Normal Distribution with Actual Data Table 1. Skewness, Kurtosis, and 1%, 2.5%, 5% Critical Values for Returns Shocks of Various Indices Statistics Coefficients Dow Jones FCI FTSE Nikkei Skewness Coefficients (N=0) -2.26 2.20 -0.53 0.17 Kurtosis Coefficients (N=3) 58.21 157.14 22.92 18.03 1% Left-tailed Critical Value (N= -2.33) -2.43 -2.46 -2.49 -2.78 2.5% Left-tailed Critical Value (N= -1.96) -1.90 -1.69 -1.87 -2.10 5% Left-tailed Critical Value (N= -1.65) -1.45 -1.26 -1.46 -1.55 1% Right-tailed Critical Value (N=2.33) 2.43 2.24 2.32 2.82 2.5% Right-tailed Critical Value (N=1.96) 1.92 1.48 1.75 1.97 5% Right-tailed Critical Value (N=1.65) 1.44 1.15 1.36 1.42 Number of Observations 4838 4758 3801 5045 The Solutions for Non-Normality Historical simulation method Student t setting Stochastic volatility settings Jump diffusion models Extreme value theory (EVT) The Log-Normal Distribution • The Log-normal distribution is useful for describing variables which cannot have a negative value, such as interest rates and stock prices. • If the variable has a Log-normal distribution, then the log of the variable will have a Normal distribution: • If x~ Log-Normal Then Log(x) ~ Normal The Log-Normal Distribution • Conversely, if you have a variable that is Normally distributed, and you want to produce a variable that has a Log-normal distribution, take the exponential of the Normal variable: • If z ~ Normal Then ez ~ Log-Normal The Log-Normal Distribution The Beta Distribution • The Beta distribution is useful in describing credit-risk losses, which are typically highly skewed. • The formula for the Beta distribution is quite complex; however, it is available in most spreadsheet applications. The Beta Distribution • As with the Normal distribution, it only requires two parameters (in this case called α and β) to define the shape. • α and β are functions of the desired mean and standard deviation of the distribution; they are calculated as follows: 2 (1 ) 2 2 (1 ) 2 ( 1) 2 CORRELATION AND COVARIANCE • So far, we have been discussing the statistics of isolated variables, such as the change in the equity prices. • We also need to describe the extent to which two variables move together, e g, the changes m equity prices and changes in interest rates. CORRELATION AND COVARIANCE • If two random variables show a pattern of tending to increase at the same time, then they are said to have a positive correlation. • If one tends to decrease when the other increases, they have a negative correlation • If they are completely independent, and there is no relationship between the movement of x and y, they are said to have zero correlation. CORRELATION AND COVARIANCE • The, quantification of correlation starts with covariance. • The covariance of two variables can be thought of as an extension from calculating the variance for a single variable. • Earlier, we defined the variance as follows: CORRELATION AND COVARIANCE CORRELATION AND COVARIANCE • The covariance between the variables is calculated by multiplying the variables together at each observation: CORRELATION AND COVARIANCE • The correlation is defined by normalizing the covariance with respect to the individual variances: THE STATISTICS FOR A SUM OF NUMBERS. • In risk measurement, we are often interested In finding the statistics for a result which is the sum of many variables • For example, the loss on a portfolio is the sum of the losses on the individual instruments • Similarity, the trading loss over a year is the sum of the losses on the individual days • Let us consider an example in which y is the sum of two random numbers, x1 and x2 THE STATISTICS FOR A SUM OF NUMBERS. THE STATISTICS FOR A SUM OF NUMBERS. THE STATISTICS FOR A SUM OF NUMBERS. • One particularly useful application of this equation is when the correlation between the variables is zero • This assumption is commonly made for day-to-day changes m market variables. • If we make this assumption; then the variance of the loss over multiple days is simply the sum of the variances for each day: THE STATISTICS FOR A SUM OF NUMBERS. BASIC MATRIX OPERATIONS • When there are many variables, the normal algebraic expressions become cumbersome. • An alternative way of writing these expressions is in matrix form. • Matrices are just representations of the parameter in an equation BASIC MATRIX OPERATIONS • You may have used matrices m physics to represent distances m multiple dimensions, e g, m the x, y, and z coordinates. • In risk, matrices are commonly used to represent weights on different risk factors, such as interest rates, equities, FX, and commodity prices BASIC MATRIX OPERATIONS • For example, we could say that the value of an equity portfolio was the sum of the number (n) of each equity multiplied by the value (v) of each: BASIC MATRIX OPERATIONS BASIC MATRIX OPERATIONS BASIC MATRIX OPERATIONS