Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
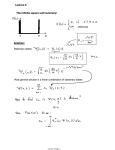
Lecture 3 Stephen G Hall Stationarity NON-STATIONARY TIME SERIES OVER THE LAST DECADE OR SO WE HAVE BEGUN TO UNDERSTAND THAT ECONOMETRIC ANALYSIS OF TIME SERIES DATA CAN BE SERIOUSLY MISLEADING WHEN WE ARE DEALING WITH NON STATIONARY DATA. EARLIER STUDIES POINTED TO THE PROBLEM GRANGER AND NEWBOLD(1974) OR YULE(1926) eg BUT IT IS ONLY RECENTLY THAT WE HAVE BEGUN TO DEVELOP A BODY OF TECHNIQUES WHICH ALLOW US TO DEAL WITH THESE PROBLEMS THESE THREE LECTURES ARE AIMED AT GIVING YOU A WORKING GRASP OF THIS BODY OF TECHNIQUES. REFERENCES CUTHBERTSON K., HALL S.G. and TAYLOR M.P. APPLIED ECONOMETRIC TECHNIQUES, SIMON AND SCHUSTER 1991, (OVERVIEW AND INTUITION) ENGLE R.F. and GRANGER C.W.J. LONG RUN ECONOMIC RELATIONSHIPS, OXFORD UNIVERSITY PRESS 1991 (REPRINTS OF KEY READINGS) BANERJEE A. DOLADO J. GALBRAITH J.W. AND HENDRY D.F. COINTEGRATION, ERROR CORRECTION AND THE ECONOMETRIC ANALYSIS OF NON-STATIONARY DATA, OXFORD 1993. MORE ON ASYMPTOTIC THEORY AND DETAILED PROOFS. SOME DEFINITIONS STATIONARITY A STOCHASTIC PROCESS IS STRICTLY (STRONGLY) STATIONARY IF ITS PROBABILITY LAW IS NOT TIME DEPENDENT. THAT IS TO SAY IF WE TAKE ANY CONSECUTIVE SUBSET OF THE TIME SERIES ITS JOINT DISTRIBUTION FUNCTION IS IDENTICAL TO ANY OTHER SIMILAR SUBSET. WEAK (SECOND ORDER, COVARIANCE) STATIONARITY IS IMPLIED BY E( X t ) = E( X t+h ) = < E( X t2 ) = E( X t2+h ) = < E( X t X t - j ) = E( X t+h X t+h- j ) = ij < AN INTEGRATED PROCESS IS ONE WHICH MAY BE REDUCED TO STATIONARITY BY DIFERENCING, DENOTED I(J) WHERE J IS THE NUMBER OF DIFFERENCES. I(0) IS STATIONARY ORDERS OF MAGNITUDE AND CONVERGENCE LET Xt BE A SEQUENCE OF REAL NUMBERS AND Yt BE A SEQUENCE OF POSITIVE REAL NUMBERS. THEN X IS OF SMALLER ORDER IN MAGNITUDE THAN Y IF; lim T X T / Y T = 0 denoted X T = o( Y T ) X IS AT MOST OF ORDER IN MAGNITUDE Y IF; | X t | / Y t M all t, denoted X T = O( Y T ) THESE TWO DEFINITIONS ARE ABOUT HOW FAST X AND Y GROW RELATIVE TO EACH OTHER, IMPLICITLY WHICH OF THE TWO WILL COME TO DOMINATE THE OTHER OVER TIME. IF Wt IS A SEQUENCE VARIABLES THEN; OF RANDOM STOCHASTIC Wt CONVERGES IN PROBABILITY TO W IF lim t Pr(| W t - W |> ) = 0, > 0, denoted plim W t is W Wt IS OF SMALLER ORDER IN PROBABILITY THAN Yt IF; plim W T / Y T = 0, denoted W T = o p ( Y T ) Wt IS AT MOST OF ORDER IN PROBABILITY Yt IF THERE EXISTS A POSITIVE REAL NUMBER M SUCH THAT; Pr(| W T | M Y T ) , > 0, denoted W T = O p ( Y T ) THESE THREE ARE ABOUT WHERE W IS GOING IN THE LONG RUN AND IF WE EXPECT W OR Y TO BECOME DOMINANT, AND HOW DOMINANT. ERGODIC AND MIXING PROCESSES AN ERGODIC PROCESS IS A SLIGHTLY STRONGER FORM OF WEAK STATIONARITY WHERE IN ADDITION WE REQUIRE -1 lim t t COV( X t , X t+i ) = 0 i=1 t MIXING IS A PARTICULAR INDEPENDENCE. FORM OF ASYMPTOTIC UNIFORM MIXING MEANS THAT ASYMPTOTICALLY THE CONDITIONAL PROBABILITY OF X GIVEN Y IS EQUAL TO THE UNCONDITIONAL PROBABILITY OF X. (ie Y TELLS US NOTHING ABOUT X) STRONG MIXING MEANS THAT ASYMPTOTICALLY THE JOINT PROBABILITY OF X AND Y IS EQUAL TO THE PRODUCT OF THE INDIVIDUAL PROBABILITIES OF X AND Y. SO AGAIN THEY ARE BASICALLY UNRELATED. WIENER OR BROWNIAN PROCESSES NORMAL ASYMPTOTICS WORKS OVER TIME AS TIME GOES FROM ZERO TO INFINITY. THIS MEANS THAT VARIANCES OF NON-STATIONARY PROCESSES GENERALLY BECOME UNBOUNDED. THE TRICK USED HERE IS TO MAP THE ZERO TO INFINITY INTERVAL OF DISCRETE TIME INTO A CONTINUOUS INTERVAL OVER 0-1. A WIENER PROCESS IS LIKE A RANDOM WALK BUT IN CONTINUOUS TIME MAPPED OVER THE UNIT INTERVAL. THE WIENER PROCESS IS DENOTED W(r) FOR r BETWEEN ZERO AND ONE. W(r) IS DISTRIBUTED AS NORMAL WITH ZERO MEAN AND VARIANCE r. THE TRICK IS TO LEARN HOW TO MAP NONSTATIONARY VARIABLES INTO THE UNIT INTERVAL AND RELATE THEM TO KNOWN DISTRIBUTIONS. CONSTRUCTING A WIENER PROCESS LET S t = S t -1 + vt S 0 = 0 vt ~ IN(0,1) THEN E( S | 0 ) = t 2 t THE IDEA IS TO FIND A MAPPING WHICH TAKES THIS SERIES WHICH SPREADS FROM ZERO TO INFINITY AND MAPS IT ONTO THE UNIT INTERVAL. WE CONSTRUCT A NEW SERIES AS FOLLOWS; RT (r) = S [Rt] / T WHERE [rT] IS THE INTEGER PART OF rT AND r IS BETWEEN 0 AND 1. THIS CREATES A `STEP' FUNCTION WHICH GETS FINER AS r GETS SMALLER. IN THE LIMIT RT(r) TENDS TO W(r) AS T BECOMES LARGE. The following slides illustrate this Step representation of a random walk over 10 points Step representation of a random walk over 100 points Step representation of a random walk over 1000 points SPURIOUS REGRESSION THE STANDARD OLS ESTIMATOR IS = (X X ) (X Y) -1 THIS RESTS ON THE ASSUMPTION THAT (1/T)(X'X) AND (1/T)(X'Y) CONVERGES ON SOME CONSTANT. MANY OF THE PROOFS OF CONSISTENCY ETC. ALSO USE THIS ASSUMPTION. UNDER NON-STATIONARITY NEITHER OF THESE TWO TERMS MAY EXIST, AS T GROWS BOTH MAY EXPLODE IN DIFFERENT WAYS AND THE RESULTING ESTIMATOR CAN BE HIGHLY MISLEADING. CONSIDER A MONTE CARLO EXPERIMENT 2 = + ~ IID(0, 1 ) Yt Y t -1 u t u t 2 X t = X t -1 + vt vt ~ IID(0, 2 ) 1 NOW CONSIDER THE REGRESSION Yt = 0 + 1 X t + t AS X AND Y ARE UNRELATED WE WOULD HOPE THAT THE COEFFICIENT ON X WOULD CONVERGE ON ZERO. THIS IS NOT THE CASE. OLS MAXIMISES CORRELATIONS AND IN NON STATIONARY DATA ENTIRELY SPURIOUS CORRELATIONS MAY EXIST WHICH DO NOT DISAPPEAR NO MATTER HOW LARGE THE SAMPLE. YULE(1926) FIRST POINTED THIS OUT IN A PRAGMATIC WAY AND GRANGER AND NEWBOLD(1974) COINED THE TERM SPURIOUS REGRESSION AND WARNED OF AN R2>DW. PHILLIPS(1986) DEMONSTRATES FORMALLY THAT OLS ESTIMATORS OF THE COEFFICIENTS DO NOT HAVE ANY WELL DEFINED LIMITING DISTRIBUTION AND AS T GROWS THE PROBABILITY OF FINDING A `SIGNIFICANT' RELATIONSHIP RISES. THE FOLLOWING SLIDES SHOW THE ACTUAL DISTRIBUTIONS WHICH EXIST UNDER VARIOUS ASSUMPTIONS REGARDING THE PROPERTIES OF X AND Y Frequency distribution for the correlation between X and Y when they are both I(0) Frequency distribution for the correlation between X and Y when they are both I(1) Frequency distribution for the correlation between X and Y when they are both I(2) Frequency distribution for the correlation between X and Y when X is I(1) and Y is (2) DETERMINISTIC AND STOCHASTIC TRENDS ONE SOLUTION CONSIDERED TO THE PROBLEM OF NONSTATIONARITY WAS DETRENDING THE DATA. THIS IS NOT NOW REGARDED AS SATISFACTORY FOR TWO REASONS. FIRST. DETERMINISTIC TRENDS CAN NOT REMOVE A STOCHASTIC UNIT ROOT. X t = + X t - 1 + vt X0 = 0 t X t = t + vi i=0 ONLY THE DRIFT IS REMOVED NOT THE UNIT ROOT. SECOND. THE DISTRIBUTIONAL PROBLEMS ASSOCIATED WITH SPURIOUS REGRESSIONS APPLY EQUALLY TO THE ESTIMATION OF DETERMINISTIC EFFECTS. WE TEND TO ACCEPT THERE PRESENCE TOO EASILY. SO WE NEED TO KNOW ABOUT THE STATIONARITY PROPERTIES OF OUR DATA TO MAKE SENSE OF ANY ESTIMATION RESULTS. TESTING FOR STATIONARITY THIS IS USUALLY UNDERTAKEN IN TERMS OF TESTING FOR A UNIT ROOT, CONSIDER Y t = Y t -1 + vt THEN THE NULL HYPOTHESIS OF A UNIT ROOT IMPLIES THAT =1 IF THIS IS SIGNIFICANTLY LESS THAN 1 THEN WE CAN REJECT THE UNIT ROOT HYPOTHESIS IN FAVOUR OF A STATIONARY ALTERNATIVE. UNDER THE NULL HOWEVER Y IS NONSTATIONARY AND SO THE DISTRIBUTION OF THE TEST STATISTIC IS NONNORMAL AND SO WE CAN NOT USE STANDARD `t' TABLES. CORRECT CRITICAL VALUES WERE FIRST TABULATED BY DICKEY(1976) AND USED IN DICKEY AND FULLER (1979, 1981) THE DICKEY-FULLER TEST MODELS THREE BASIC MODELS ARE CONSIDERED, IN A SLIGHTLY DIFFERENT PARAMETERISATION TO THE LAST SLIDE. a Y t = a Y t - 1 + vt b Y t = + b Y t - 1 + vt c Y t = + c Y t - 1 + t + vt H0 : = 0 H1 : < 0 TWO TEST PROCEDURES ARE PROPOSED i) Tˆ ii) ˆ/SE( ˆ ) Dickey-Fuller 5% critical values for both tests TEST i) TEST ii) -7.7 -1.95 T=100 -7.9 T=INFINITY -8.1 MODEL b -1.95 -1.95 T=50 -13.3 T=100 -13.7 T=INFINITY -14.1 MODEL c -2.93 -2.89 -2.86 T=50 -19.8 -3.50 T=100 -20.7 T=INFINITY -21.8 -3.45 -3.41 MODEL a T=50 TESTING IN THE PRESENCE OF A GENERAL DYNAMIC ERROR PROCESS. THE TESTS OUTLINED ABOVE ASSUME THAT THE ERROR PROCESS OF THE MODEL IS WELL BEHAVED. IN GENERAL WE WOULD EXPECT A SIMPLE MODEL OF THIS TYPE TO HAVE A RICH DYNAMIC STRUCTURE. FULLER(1976) DEMONSTRATES THAT A HIGH ORDER AR MODEL CAN BE DEALT WITH USING THE FOLLOWING MODEL. SAID AND DICKEY(1984) EXTEND THE PROOF TO INCLUDE ARMA MODELS. THE AUGMENTED DICKEY-FULLER TEST (ADF) k a Y t = a Y t - 1 + Y t - i + vt i +1 k b Y t = + b Y t - 1 + Y t - i + vt i=1 k c Y t = + c Y t - 1 + t + Y t - i + vt i=1 H0 : = 0 H1 : < 0 THESE HAVE THE SAME ASYMPTOTIC DISTRIBUTION AS THE DF TESTS. NON-PARAMETRIC TESTS OF A UNIT ROOT TO AVOID USING MORE SPECIAL TABLES IT IS USEFUL TO HAVE TESTS WHICH RELY ON LESS STRINGENT DISTRIBUTIONAL ASSUMPTIONS. THE MAIN TESTS USED ARE THE PHILLIPS(1987) AND PHILLIPS AND PERON(1988) TESTS; SAME THREE BASIC MODELS AS THE DF TEST a Y t = a Y t - 1 + vt b Y t = + b Y t - 1 + vt c Y t = + c Y t - 1 + t + vt H0 : = 0 H1 : < 0 BUT THE ERRORS NEED NOT BE WHITE NOISE and normal. THE FOLLOWING ASSUMPTIONS ARE MADE. E( vt ) = 0 t sup t E | vt | < FOR SOME > 2 2 = lim t E( t -1 Y t2 ) EXISTS, AND 2 > 0 vt IS STRONGLY MIXING 2 = E( v12 ) + E( v1 ,v j ) j=2 THE TEST DEFINE T 2 -1 S v = T vˆt2 t =1 l T j=1 t = j +1 ~2 2 -1 S Tl = S v + 2 T l (j) v~t v~t - j -1 (j) = 1 j(l + 1 ) l THEN THE CORRESPONDING TESTS FOR THE CASE WITHOUT TREND ARE T 2 -1 2 2 -2 = T 0.5( )[ ( ) S Tl S v T Y t - 1 Y - 1 ] Z t= 2 Z = ( S v / S Tl )( ˆ/SE( ˆ )) Standatd DF distrbution T - 0.5( S tl2 - S v2 )[ S Tl ( T - 2 ( Y t - 1 - Y - 1 )2 )0.5 ] - 1 t= 2 MULTIPLE UNIT ROOTS WE OFTEN WANT TO ESTABLISH THE ORDER OF INTEGRATION OF A SERIES. DICKEY AND PANTULA(1987) POINT OUT THAT TESTING FOR I(1) THEN I(2) THEN I(3) ETC, IS NOT A VALID TEST SEQUENCE AS THE ALTERNATIVE IS STATIONARITY. THE CORRECT PROCEDURE IS TO START FROM THE HIGHEST PROBABLE ORDER OF INTEGRATION, SAY I(3), THEN TEST I(3) AGAINST I(2), IF WE REJECT I(3) THEN TEST I(2) AGAINST I(1) AND SO ON. SEASONAL INTEGRATION UNIT ROOTS MAY EXIST AT ANY FREQUENCY (NOT JUST ZERO) AND SOME LITERATURE EXISTS ON SEASONAL INTEGRATION. IF X t - X t -4 = vt THEN GENERALLY THE FIRST DIFFERENCE OF X WILL NOT BE STATIONARY AND X MUST BE SEASONALLY DIFFERENCED. WE CAN WRITE X t - X t - 4 = ( X t - X t -1 ) + ( X t -1 - X t - 2 ) + ( X t - 2 - X t - 3 ) + ( X t - 3 - X t - 4 ) (1 - L4 )X = (1 - L)(1 L L2 L3 )X = S(L) X IS SEASONALLY INTEGRATED OF ORDER d,D (SI(d,D) IF D S(L ) X d IS STATIONARY FURTHER (1 - L4 ) = (1 - L)(1 + L)(1 + L2 ) = (1 - L)(1 + L)(1 - iL)(1 + iL) SO THERE ARE 4 ROOTS; 0, HALF YEARLY AND A PAIR OF COMPLEX CONJUGATES AT 4 QUARTERS TESTING SEASONAL UNIT ROOTS LETS ASSUME (L) X t = (1 - 1 L)(1+ 2 L)(1+ 3 L2 ) X t + vt THEN AFTER SOME MANIPULATION WE CAN WRITE (1 - L4 ) X t = 1 Z 1t - 1 + 2 Z 2t - 1 + 4 Z 3t - 1 + 3 Z 3T - 2 + + vt 2 3 = (1 + L + + Z 1t L L ) Xt 2 3 = -(1 L + Z 2t L L ) Xt 2 = -(1 Z 3t L ) Xt THE HEGY (HYLLEBERG ENGLE GRANGER AND YOO(1990)) TESTS FOR SEASONAL UNIT ROOTS ARE THEN H 0 : UNIT ROOT 0 FREQUENCY => 1 = 0 H 0 : UNIT ROOT HALF SEASONAL F => 2 = 0 H 0 : UNIT ROOT AT SEASONAL F => 3 = 4 = 0 CRITICAL VALUES TABULATED IN HEGY Example The Great Crash, The Oil Price Shock and the Unit Root Hypothesis by P Perron, Econometrica 1989, 57 no.6, pp 1361-1401 Perron notes that the implications for economic analysis of a unit root and a deterministic trend are completely different. xt xt 1 ut a shock should persist for ever, the variance into the future grows exponentially, policy will last forever. xt T ut Here a shock will not last beyond the current period, the variance of x does not grow into the future, policy can have no lasting effect Many studies have found unit roots and Peron questioned this. He proposed 2 possible ways of viewing the world 3 possible models all based around a random walk non-stationary process. Break in level, break in trend and both together. 3 alternatives based around deterministic trends, Break in level, trend or both. His point is it may be very difficult to tell the two apart Log of nominal USA wages Log of real USA GNP Log of USA common stock price Splitting into sub samples often implies the sub samples are stationary Correlogram often dies away quickly suggesting stationarity He undertook a monte carlo study, data was generated by yt 1 ( 2 1 ) DU t 1t et and yt 1 1t ( 2 1 ) DT * et and then he estimated a standard DF test for a unit root. This process was replicated 10,000 times Cumulative density function of the DF coefficient as the size of the break in the mean increases Same thing for the breaking trend model Coefficient results Monti carlo produces new critical values which vary with the break size and he can then retest the data based on this more general model. Surprisingly although the critical value changes with the break size it doesn’t change much He then re-tests the original data assuming the presence of a break with these new critical values and finds that most of the data can be treated as stationary The message: don’t use the tests mechanically, make sensible judgements about when we need to worry about non-stationarity.