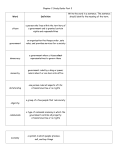
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Computer Methods and Programs in Biomedicine (2004) 75, 45—49 Adjusted survival curves with inverse probability weights Stephen R. Cole a,*, Miguel A. Hernán b a Department of Epidemiology, Johns Hopkins Bloomberg School of Public Health, 615 N Wolfe St E-7014, Baltimore, MD 21205, USA b Department of Epidemiology, Harvard School of Public Health, Boston, MA, USA Received 9 September 2003 ; received in revised form 17 October 2003; accepted 22 October 2003 KEYWORDS Graphics; Standardization; Stratification; Survival analysis Summary Kaplan—Meier survival curves and the associated nonparametric log rank test statistic are methods of choice for unadjusted survival analyses, while the semiparametric Cox proportional hazards regression model is used ubiquitously as a method for covariate adjustment. The Cox model extends naturally to include covariates, but there is no generally accepted method to graphically depict adjusted survival curves. The authors describe a method and provide a simple worked example using inverse probability weights (IPW) to create adjusted survival curves. When the weights are non-parametrically estimated, this method is equivalent to direct standardization of the survival curves to the combined study population. © 2003 Elsevier Ireland Ltd. All rights reserved. 1. Introduction In observational studies without random assignment of treatment, the unadjusted Kaplan—Meier survival (1-probability of death) curves may be misleading due to confounding. For example, if patients with better prognostic values were more likely to be assigned to the new treatment at baseline, then a higher survival curve could be found in the treated group than in the untreated group, even if treatment were not efficacious. A common approach to deal with this non-comparability problem is to display a separate pair of survival curves for each level of disease severity. Thus, only treated and untreated subjects with the same level of prognostic values at baseline would be *Corresponding author. Tel.: +1-410-955-4342; fax: +1-410-955-7587. E-mail address: [email protected] (S.R. Cole). compared. However, adjustment based on stratification of survival curves becomes unfeasible when the number of baseline covariates is large or when any of them are continuous. Note that the analytic issue motivating this problem is confounding; therefore an adequate graphic that correctly summarizes over subgroups is needed. In contrast, if the issue at hand were effect measure modification (i.e. statistical interaction), then summarizing over subgroups may not be appropriate. Several proposed alternative methods to produce adjusted survival curves suffer from numerous shortcomings, including constraining the adjusted survival curves to be proportional, computation difficulty with numerous or time-varying covariates, and not allowing adjustment for continuous covariates [1]. Below, we describe a method based on inverse probability weights (IPW) that overcomes the above-mentioned problems and is easily implemented with standard software (e.g. SAS). 0169-2607/$ — see front matter © 2003 Elsevier Ireland Ltd. All rights reserved. doi:10.1016/j.cmpb.2003.10.004 46 2. Method It is well known that standardization is a general alternative to stratification-based methods of adjustment for covariates. In the simplest case with one dichotomous baseline covariate, it can be shown that direct standardization (to the combined study population) is equivalent to Robin’s non-parametric g-computation algorithm [2], which in turn is equivalent to non-parametrically estimated IPW [3]. Specifically, given n subjects with m exposed, of whom a are diseased and c are non-diseased, all of whom may be stratified into j levels of a covariate, such that aj , mj , and nj are the number of exposed and diseased, number of exposed, and overall number of subjects at level j of the covariate, respectively. TheIPW risk proportion can be written as j aj w j / j m j w j , = (m/n)/(m where w /n ). Replace the wj , j j j a [(m/n)/(m /n )]/ m [(m/n)/(m /n )], facj j j j j j j j tor m/n out of the numerator and denominator and a [1/(m cancel, leaving /n )]/ m [1/(m /n j j j j j j )], j j rearrange as j aj (nj /mj )/ j mj [(nj /m ), and furj ther rearrange the numerator as j (aj /mj )nj / m (n /m ). Next, the m ’s in the denominaj j j j j tor cancel on each j, leaving j (aj /mj )nj / j nj , which is exactly a common form of the directly standardized risk proportion [4]. Informally, analyses using IPWs weight each subject i by Wi , where Wi is equal to the inverse of the probability of receiving his or her own treatment or exposure X conditional on the observed covariate vector Z, rather than stratifying on, or adjusting for, covariates Z by including them in a regression model. Specifically, Wi = 1/f(X|Z), where f[·] is by definition the conditional density function evaluated at the observed covariate values for subject i. While the true weights Wi are typically unknown, one can estimate these weights ŵi non-parametrically from the corresponding sample proportions. However, just as non-parametric standardization is unfeasible in the presence of multiple or continuous covariates, so to is the non-parametric calculation of IPW. Therefore, we may use a semi- or fully-parametric model to estimate these weights. While it is not immediately clear how to extend classic direct standardization to such a model, Robins and colleagues have described how to do so for IPW [5]. Briefly, one fits a prior logistic regression of exposure X regressed on the covariate vector Z (the same regression used to estimate the propensity score [6]) and obtains estimates of the predicted probabilities Pr(X = x|Z) from the fitted model. These predicted probabilities are used to calculate ŵi as P̂r(X = x|Z)−1 . While asymptotically unbiased, in S.R. Cole, M.A. Hernán practice wi may be highly variable and notable stabilization may be achieved by replacing the numerator with the marginal probability of receiving the exposure observed, SWi = f(X)/f(X|Z) [3]. A separate logistic regression model is used to estimate the numerator of swi . Using IPW to produce adjusted survival curves is derivative of using such weights for the control of confounding in general, as recently described by Robins and colleagues [5]. A Cox regression model weighted by the estimated stabilized weights sŵi accounts for confounding by the covariate vector Z because in the ‘‘pseudopopulation’’ created by weighting the covariates Z are unrelated to exposure X. To obtain a variance estimate that is valid under the null hypothesis and provides conservative confidence interval coverage, we use the robust variance estimator of Lin and Wei [7]. A short SAS program in the Appendix illustrates this method. To adjust for potentially informative censoring, one could multiply our IPW by time varying inverse probability-of-censoring weights of the form cwi (t) = tj=1 Pr[C(t) = 0]/Pr[C(t) = 0|Z], where the product is over j and C(t) is an indicator of censoring, and two logistic regression models analogous to the previous IPW are used to estimate the numerator and denominator. 3. Example Table 1 provides the data from a study comparing disease-free survival in 76 Ewing’s sarcoma patients, 47 of whom received a novel treatment (S4) while 29 received one of three (S1—S3) standard treatments [8]. Panel A of Fig. 1 displays the unadjusted survival curves for treatment S4 versus S1— S3 combined. The estimated hazard (i.e. instantaneous risk) ratio comparing treatment S4 against S1—S3 from a Cox model was 0.5 (95% confidence interval: 0.3, 1.0; P = 0.03). The unadjusted analysis suggests that the S4 treatment was beneficial in reducing the hazard of Ewing’s sarcoma recurrence compared to the other treatments combined. Serum lactic acid dehydrogenase (LDH) is an enzyme thought to be related to tumor burden. Indeed, in the present data abnormally high (i.e. ≥200 international units) pre-treatment LDH was a strong predictor of recurrence (unadjusted hazard ratio = 7.6; 95% confidence interval: 4.0, 14.5). Further, high LDH levels were indicative of a lesser likelihood of assignment to treatment with S4 rather than S1—S3 (odds ratio = 0.2; 95% confidence interval: 0.1, 0.5). To implement the proposed method, two prior logistic regression models were fit and sŵi were Adjusted survival curves with inverse probability weights 47 Table 1 Recurrence of Ewing’s sarcoma by treatment and lactic acid level (N = 76) Treatment LDHa Days to recurrenceb S4 0 31, 335, 366, 426, 456, 578, 589, 762+, 792, 913+, 914+, 974, 1005, 1035, 1065+, 1096, 1107+, 1219+, 1250+, 1312+, 1403+, 1461+, 1553+, 1645+, 1706+, 1734+, 1826+, 1948+, 1949+, 1979+, 2222+, 2374+, 2435+, 2465+, 2526+ 0, 91, 183, 334, 338, 365, 391, 518, 547, 608, 609, 851 1 S1—S3 0 1 153, 945, 1400, 1887, 2557+, 3134+, 3226+, 3348+, 3501+, 3743+ 151, 152, 212, 214, 242, 243, 244, 245, 249, 273, 336, 337, 396, 427, 457, 761, 1249, 1310, 2708+ a Serum lactic acid dehydrogenase, <200 vs. ≥200 international units. b Censored subjects indicated by +. Fig. 1 Panel (A) presents the unadjusted survival curves for 76 Ewing’s sarcoma patients. Panel (B) presents the inverse probability weighted survival curves. constructed and added to the data file. Table 2 details the construction of the pseudopopulation for the 76 patients. When the model for the denominator of the stabilized weights is non-parametric (such as in this example), the pseudo-sample size sŵi equals the observed sample size (n = 76) because the mean of the stabilized weights is unity (3). In the pseudopopulation, the indicator of elevated LDH is no longer associated with treatment (odds ratio = 1.0; robust 95% confidence interval: 0.4, 2.7). The estimated IPW hazard ratio com- paring treatment S4 against S1—S3 was 1.1 (robust 95% confidence interval: 0.6, 2.1; robust P = 0.78), indistinguishable from the results attained from standard covariate adjustment (adjusted hazard ratio = 1.1; 95% confidence interval: 0.6, 2.1). However, since the final IPW model is not fit within levels of the covariates Z, Panel B of Fig. 1 is a straightforward plot of the survival curves for the weighted data, which are not forced to be proportional, are computationally simple even with numerous or time-varying covariates, and allow Table 2 Stabilized inverse probability weights (sw) and pseudopopulation (N = 76) LDH S4 N Pr(X = x) Pr(X = x|Z) sŵ Pseudo N 1 1 0 0 1 0 1 0 12 19 35 10 0.62 0.38 0.62 0.38 0.39 0.61 0.78 0.22 1.60 0.62 0.80 1.72 19.2 11.8 27.8 17.2 Total 76 76.0 48 S.R. Cole, M.A. Hernán for adjustment of continuous covariates. Indeed, the full power of the weighting approach is best appreciated with numerous time-varying and/or continuous covariates as demonstrated by Hernán et al. [9] and Cole et al. [10]. In conclusion, the present method based on IPW has a direct and intuitively appealing interpretation. Under the assumption of no unmeasured confounding, one survival curve represents the experience of the entire sample had none been exposed, while the other curve represents the experience of the entire sample had everyone been exposed. Acknowledgements We thank Drs. Paul Allison, Sander Greenland, Alvaro Muñoz, James Robins and Patrick Tarwater for constructive suggestions. Portions of this paper were presented at the 35th annual meeting of the Society for Epidemiologic Research. Dr. Cole was partly supported by the National Institute of Allergy and Infectious Diseases by means of the data coordinating centers for the Multicenter AIDS Cohort (U01-AI-35043) and Women’s Interagency HIV studies (U01-AI-42590). Dr. Hernán was partly supported by NIH grant K08-AI-49392. Appendix A. SAS Macro Code to implement method /* Macro to implement weighted survival curves ** 1. Must pass (a) data set name, (b) binary exposure variable, (c) covariate list, (d) survival time, ** and (e) binary event indicator, in that order ** 2. Two graphs are saved as "C:/temp/crude.png" and "C:/temp/weighted.png" */ %macro curves(data,exp,covs,time,event); *PREPARE DATA; data a; set &data; id=_n_; label &exp="Exposure" &time=”Time” &event=”Event”; *CALCULATE WEIGHTS; proc logistic descending data=&data noprint; model &exp=; output out=o1 prob=tn; proc logistic descending data=&data noprint; model &exp=&covs; output out=o2 prob=td; proc sort data=o1; by id; proc sort data=o2; by id; data o12; merge o1 o2; by id; data b(drop=_level_ tn td); set o12; by id; if &exp=0 then do; tn=1-tn; td=1-td; end; tw=1/td; stw=tn/td; *FIT CRUDE, ADJUSTED, AND WEIGHTED COX MODELS; proc phreg data=b; model &time*&event(0)=&exp/rl; title1 "Crude"; proc phreg data=b; model &time*&event(0)=&exp &covs/rl; title1 "Adjusted"; proc phreg data=b covs; model &time*&event(0)=&exp/rl; freq stw/notruncate; title1 "Weighted"; *SET GRAPH OPTIONS; goptions device=png targetdevice=png gsfname=grafout gsfmode=replace xmax=5 ymax=4 xpixels=1500 ypixels=1200; axis1 label=(angle=90 font="Times" height=9 "Survival") width=3 order=(0.00 0.25 0.50 0.75 1.00) major=(height=2 width=3) minor=none value=(font="Times" height=5) offset=(0,0); axis2 label=(font="Times" height=9 "Days") width=3 length=130 order=(0 500 1000 1500) major=(height=2 width=3) minor=none value=(font="Times" height=5) offset=(0,5); legend1 across=1 position=(top right inside) noframe label=none shape=line(10) value=(justify=left font="Times" height=6 "Standard Tx" "Novel Tx"); symbol1 c=black l=1 w=9 v=none i=stepjs; symbol2 c=black l=3 w=9 v=none i=stepjs; *PLOT GRAPHS; proc phreg data=b noprint; model &time*&event(0)=; strata &exp; baseline out=g1 survival=s; filename grafout "C:/temp/crude.png"; proc gplot data=g1; plot s*&time=&exp/vaxis=axis1 haxis=axis2 legend=legend1 noframe; title1 move=(+25,+0) font="Times" height=6 "Unadjusted"; proc phreg data=b noprint; model &time*&event(0)=; strata &exp; freq stw/notruncate; baseline out=g4 survival=s; title1; filename grafout "C:/temp/weighted.png"; proc gplot data=g4; plot s*&time=&exp/vaxis=axis1 haxis=axis2 legend=legend1 noframe; footnote1; title1 move=(+25,+0) font="Times" height=6 "Weighted"; run; quit; %mend curves; *CALL MACRO FOR EXAMPLE DATA; %curves(a,s4,ldh,days,death); run; Adjusted survival curves with inverse probability weights References [1] F.J. Nieto, J. Coresh, Adjusting survival curves for confounders: a review and a new method, Am. J. Epidemiol. 143 (1996) 1059—1068. [2] J.M. Robins, A new approach to causal inference in mortality studies with a sustained exposure period: application to the healthy worker survivor effect, Math. Model. 7 (1986) 1393—1512. [3] J.M. Robins, Marginal structural models, in: 1997 Proceedings of the American Statistical Association, Section on Bayesian Statistical Science, 1998, pp. 1—10. [4] K.J. Rothman, S. Greenland, Modern Epidemiology, Lippincott-Raven, New York, 1998. [5] J.M. Robins, M.A. Hernán, B. Brumback, Marginal structural models and causal inference in epidemiology, Epidemiology 11 (2000) 550—560. 49 [6] P. Rosenbaum, D. Rubin, Reducing bias in observational studies using subclassification on the propensity score, J. Am. Stat. Assoc. 79 (1984) 516—524. [7] D.Y. Lin, L.J. Wei, The robust inference for the proportional hazards model, J. Am. Stat. Assoc. 84 (1989) 1074— 1078. [8] R.W. Makuch, Adjusted survival curve estimation using covariates, J. Chronic Dis. 35 (1982) 437—443. [9] M.A. Hernán, B. Brumback, J.M. Robins, Marginal structural models to estimate the causal effect of zidovudine on the survival of HIV-positive men, Epidemiology 11 (2000) 561— 570. [10] S.R. Cole, M.A. Hernán, J.M. Robins, et al., Effect of highly active antiretroviral therapy on time to acquired immunodeficiency syndrome or death using marginal structural models, Am. J. Epidemiol. 158 (2003) 687— 694.