Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
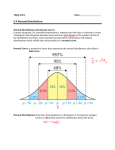
Lab 3 Analyzing Normally Distributed Data Overview of Lab Session: In this lab session we analyze real-world medical data, and test how well the data appear to be normally distributed. We begin by using SPSS to generate “fake” normally distributed data—that is data that are randomly selected from a perfectly normal distribution. We qualitatively compare the results of this ideal sample to medical data from a study of ICU patients published in JASA: Lemeshow, S., Teres, D., Avrunin, J. S., Pastides, H. (1988). Predicting the Outcome of Intensive Care Unit Patients. Journal of the American Statistical Association, 83, 348-356. This research article is available on the database JSTOR which you can access using your library account. [Go to www.csulb.edu/~library , click on Databases by title, then find JSTOR; you will be prompted to enter your campus ID and library password. Now search JSTOR for the article.] The article is also linked to the course website; you must first be logged on to your library account to link to the article. The data we work with in this lab is part of the ICU data used in the above study. The data is for 200 patients (represented by the rows of the data matrix). For each patient there are 21 measured characteristics (represented in the columns of the data matrix). These include ID, STA (Vital Status), AGE, SEX, RACE, SER (service at ICU admission), CAN (cancer), CRN (chronic renal failure), …, SYS (systolic blood pressure), HRA (heart rate), … I. Get Started Use your ID number and password to log onto the computer. Launch SPSS by clicking on Start, All Programs, Classes, then SPSS. Load the ICU data from www.csulb.edu/~saleem/Course-F08-503/Data/icu.sav II. Generate “Fake” Normally Distributed Data STEP 1 Generate “Fake” Normally Distributed Data using Compute Variable Use SPSS to generate a random sample of size 200 from a “perfect” normal distribution. The last command in the set below generates normally distributed data with mean 100 and standard deviation 20 .1 From the top menu choose Transform > Compute Variable. In the Target Variable window type FN (this is the name of the new variable) In the Numeric Expression window type: Normal(20)+100 STEP 2 Generate a Histogram for the FN Data using Chart Builder and Superimpose a Normal Curve From the top menu choose Graphs > Chart Builder From Gallery >Choose From choose Histogram Highlight the FN variable and drag it to the x-Axis under the histogram chart Go to Element Properties > Set Parameters For AnchorFfirst Bin choose Automatic For Bin Sizes choose Automatic Check the Display normal curve box Click on Continue and OK The output should contain a histogram with the appropriate normal curve. Double click on the histogram in the output window to get to Chart Editor. Choose Element > Show data labels. This last command labels each bar in the histogram with the percentage of the data that the bar represents. The Chart Builder, Element Properties, and Element Properties: Set Parameters windows are shown below. .2 II. Analyzing the Systolic Pressure Data In this part of the lab we repeat Steps 2 for the systolic pressure (SYS) from the ICU data. Observe how the real-world SYS data exhibits the characteristics of a normal distribution. STEP 2 Generate a Histogram for the SYS Data using Chart Builder. From the top menu choose Graphs > Chart Builder From Gallery >Choose From choose Histogram Highlight the FN variable and drag it to the x-Axis under the histogram chart Go to Element Properties > Set Parameters For AnchorFfirst Bin choose Automatic For Bin Sizes choose Automatic Check the Display normal curve box Click on Continue and OK The output should contain a histogram with the appropriate normal curve. Double click on the histogram in the output window to get to Chart Editor. Choose Element > Show data labels. This last command labels each bar in the histogram with the percentage of the data that the bar represents. .3 Name ________________ Worksheet for Lab 3 Use the SPSS output to answer the following questions. PART I 1. What are the mean and standard deviation of the FN data? Mean ______________, Standard deviation ______________ 2. Fill in the following table with the appropriate percentages. In the “Normally Distributed” column put the percentage of the data that should lie in the given interval if the data were perfectly normally distributed. In the FN column put the actual percentages of the data in the given interval. Interval Normally Distributed Actual FN data Between 80 and 120 Greater than 140 Greater than 160 Less than 140 3. How well does the data conform to normally distributed data? Answer this question based on (1) How well the normal curve fits the histogram and (2) the results in the table in Question 2. .4 PART II 4. What are the mean and standard deviation of the SYS data? Mean ______________, Standard deviation ______________. 5. Sketch a rough graph of the histogram and the normal curve from the SPSS output. 6. Does the data appear to be normally distributed? Answer this question based on the histogram and the superimposed normal curve. 7. Find the interval that represents the mean systolic pressure plus or minus one standard deviation. Interval: ( __________, __________ ) 8. What percent of the systolic pressures would expect to lie in the interval in Question 7. .5