Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
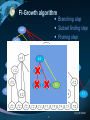
Parallel Association Rule Mining based on FI-Growth Algorithm Bundit Manaskasemsak, Nunnapus Benjamas, Arnon Rungsawang 林俊宏 2010.06.01 Outline 1 Introduction 2 FI-Growth algorithm 3 Parallel FI-Growth 4 Experiments and results 5 Conclusion Introduction Association rule mining is one of the most important techniques in data mining. consists of two main steps: frequent itemsets generation tries to extract the most frequent patterns; rule generation uses these frequent patterns to generate interesting rules. 林俊宏2010.06.01 3 Introduction Two fundamental algorithms proposed for finding the frequent itemsets from large databases Apriori algorithm Closed algorithm Proposed to reduce this cost. The Fp-growth algorithm FI-growth algorithm 林俊宏2010.06.01 4 Introduction Transaction-oriented databases are usually very large. Mining useful rules from such large and volatile databases is a challenging problem. Fast association rule mining inevitably requires large computing resources. cluster computing technology offers a potential solution parallel Apriori approach, parallel FP-growth approach 林俊宏2010.06.01 5 Introduction The objective of this paper utilize parallelization on a computing cluster environment for fast extraction of frequent itemsets from large dense databases. propose an alternative approach parallel association rule mining based on the FIgrowth algorithm 林俊宏2010.06.01 6 FI-Growth algorithm Similar to the FP-growth algorithm, FI-growth represents the data set as a prefix sharing tree, called an “FI-tree”. It commonly consists of two phases: FI-tree construction Mining 林俊宏2010.06.01 7 FI-Growth algorithm Constructing an FI-tree requires scanning the database only twice: the first scan creates the header table the second scan creates the items-tree. Note that : the items in all lists must be A 3 in the same relative order. B 1 C 4 D 2 E 4 F 4 A 3 C 4 D 2 E 4 F 4 林俊宏2010.06.01 8 FI-Growth algorithm d:2 d:2 d:2 Combining operation e: 1 e: 1 e: 1 f: 1 f:1 f: 1 f:f:11 the same sub-paths are grouped and their counts summed. f:1 The combining operation has the following properties. 1) Self-reflective property: tree(a) © tree(a) is equal to tree(a) itself. 2) Commutative property: tree(a ) © tree(a ) is equal to tree(a ) © tree(a ). 3) Associative property: (tree(a ) © tree(a )) © tree(a ) is equal to tree(a ) © (tree(a ) © tree(a )). 1 2 2 1 1 1 2 2 3 3 林俊宏2010.06.01 9 The result (grey nodes) replaces the old one that is linked from root. 林俊宏2010.06.01 10 FI-Growth algorithm Branching step Subset finding step Pruning step root a:3 c:2 c:2 d:2 d:2 d:2 e:1 e:1 f:1 e:1 f:1 e:2 f:1 f:2 e:4 e:1 f:2 f:1 f:4 f:3 f:1 f:1 林俊宏2010.06.01 11 Parallel FI-Growth a parallel version of the FI-growth algorithm employ a data parallelism technique on a PC cluster partition the transaction one-time synchronization to exchange their sub-trees 林俊宏2010.06.01 12 Parallel FI-Growth Hierarchical minimum support two solutions to avoid such a problem: All processors synchronize their lists of item counts utilizing two values of minimum support: • min_supL1 is defined and used to prune the local header table • min_supL2 is defined to prune the local items-tree. in this paper, we use the second approach. 林俊宏2010.06.01 13 Parallel FI-Growth Parallelization min_supL1 = 1(20%) min_supL2 = 2(40%) 林俊宏2010.06.01 14 Parallel FI-Growth FI-Tree synchronization Exchanging of local header table: • To reduce the communication overhead, only the list of items is broadcast to other processors. Sending of local sub-tree: • which local sub-tree(s) should be kept, and which should be sent to the target processors 林俊宏2010.06.01 15 Experiments and results Hardware and environment configuration: Tested on a cluster of x86-64 based SMP machines named “Bedrocks”. Each machine consists of dual 3.2GHz Intel quad-core processors, 4GB of main memory, and an 80GB SATA disk. equipped with the Linux-based operating system inter-connected via a 1000Base-TX Ethernet switch the parallel algorithm is written in the C language uses the MPICH message passing library version 1.2.7. All experiments were run under no-load conditions 林俊宏2010.06.01 16 Experiments and results Data set: For the test data set, we utilized the standard “IBM synthetic data generator” to synthesize a transaction database. • 1000 unique items • 16 million records (each has average transaction length of 10) 林俊宏2010.06.01 17 林俊宏2010.06.01 18 Conclusion research in many areas, including run-time memory requirements In this paper propose a parallel FI-growth algorithm to accelerate association rule mining. In future work, effects of partitioning memory requirements reduce the communication overhead load balancing 林俊宏2010.06.01 19 20 林俊宏2010.06.01