Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
ROLL NO.:
NAME:
CS 537 / CMPE 537 – Neural Networks
Final Exam
May 26, 2005
Duration: 2 hours (9:00 to 11:00 AM)
Instructions:
(1) Please write legibly. Unreadable answers will NOT be graded. Use a BALL-POINT
and write in a readily readable font size.
(2) Write in the space provided for each question only. If you need to continue a question
in a different space, have it signed by the instructor/invigilator. Otherwise, it will not
be graded.
(3) Distribute your time judiciously as some questions might be more involved than
others.
(4) Make all usual assumptions if something is not stated in the question explicitly. If you
feel your answer depends on an unstated assumption, then state it explicitly.
(5) You may use a double-sided help-sheet and a basic calculator.
(6) There are 19 questions in this exam.
Questions 1 to 15 require short answers or multiple choice selections. Each question
is worth 3 points.
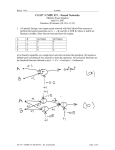
1. The following RBF network uses Gaussian activation functions in the hidden layer
and linear activation function in the output layer. Suppose the Gaussians are centered
at [0, 0] (neuron 1) and [3, 3] (neuron 2) and have variances of 1 and 1.5, respectively
Given the weight vector w = [2, 1, 2]T, compute the output y when an input x = [1, 1]T
is applied to the network.
1
w0
x1
1
w1
x2
CS 537 / CMPE 537 (Sp 04/05) – Dr. Asim Karim
y
2
w2
Page 1 of 8
2. Refer to question 1 above. (a) plot the input space showing the Gaussian functions
(and its parameters) and the input vector. (b) plot the feature space (hidden layer
space) showing the decision boundary and the input vector.
3. Given the 3 input-output samples {di, xi} (i = 1, 2, 3): {5, (0, 2)}, {8, (1, 3)}, and {12,
(2, 4)}, compute the interpolation matrix Φ when the Gaussian radial-basis functions
with variances of 1 are used.
4. Refer to question 3 above. Suppose we want to fit a curve through the first 2 inputoutput samples only (i = 1, 2). Solve the resulting strict interpolation problem to find
the interpolation weights. Draw the network that solves this interpolation problem
showing all nodes and links with activation functions and weights. (Answer on the
back-side of the PREVIOUS page)
CS 537 / CMPE 537 (Sp 04/05) – Dr. Asim Karim
Page 2 of 8
5. Consider a regularization network with 10 input nodes, 125 hidden neurons, and 2
output neurons (no bias inputs). What is the number of free parameters in the network?
Explain your answer clearly.
6. The principal component of a zero-mean input space
a. Has the smallest mean-square deviation
b. Has the largest mean
c. Has the largest mean-square deviation
d. Has the smallest mean
e. a and b
f. c and d
7. Mathematically show that the weights increase (or decrease) without bounds when
using the simple Hebbian learning rule. Assume multiple inputs and a single output
Hebbian network.
8. The correlation matrix of an input space is given by:
2 0.5
R
0.2 1
Given the unit vector [0.707 0.707]T compute the variance of the input (space) when
projected on the unit vector.
CS 537 / CMPE 537 (Sp 04/05) – Dr. Asim Karim
Page 3 of 8
9. List the key difference(s) between a Hebbian network (with Sanger’s rule) and a
Kohonen network (SOM with Kohonen’s rule).
10. Draw the signal-flow graph of a single neuron instar network (for feedforward
operation only). Label all parameters.
11. Consider a competitive network with 4 inputs and 2 outputs having the weight matrix:
1 2 1.5 3
W
2 1 1.5 2
Compute the new weight matrix when the input [2 1 2 1]T is presented to the network.
Assume learning rate parameter is 0.5. (Answer on the back-side of the PREVIOUS page)
12. List at least 3 implementation details that helps improve the performance of the SOM
algorithm.
CS 537 / CMPE 537 (Sp 04/05) – Dr. Asim Karim
Page 4 of 8
13. Write the equation for the decision boundary of a single-layer single-neuron
feedforward network with the sigmoidal activation function. Will this boundary be
linear or nonlinear?
14. Briefly describe the cross-validation approach to avoiding overfitting in a MLP.
15. The following is NOT a technique for improving the performance of the BP
algorithm:
a. De-correlate the inputs
b. Use the hyperbolic tangent activation function
c. Initialize the weights to uniform random numbers with zero mean
d. Allow learning rate annealing
e. Increase learning rate parameter when weights change in the same direction
for several iterations
f. None of the above
Questions 16 to 19 require brief answers. Points are indicated next to the question
number.
16. (a) (6 points) Suppose a single-neuron neural network has the following cost function
(R = correlation matrix of the inputs):
w T Rw
J (w ) T
(Note: you should not cancel out terms)
w w
Find (show) the weight vector that maximizes this cost function.
CS 537 / CMPE 537 (Sp 04/05) – Dr. Asim Karim
Page 5 of 8
(b) (4 points) What is the interpretation of this cost function? What useful task does it
perform? Which neural network model (that we studied) has this cost function?
17. (15 points) Suppose we want to solve the XOR problem (classification problem)
using a regularization network. (Answer this question on the back-side of the
PREVIOUS page)
a. (2 points) Draw the architectural graph of the network labeling all important
parameters.
b. (4 points) If Gaussian functions are used, determine their numbers and centers.
c. (9 points) Compute the updated weights of the network when it is presented
with the input [0, 1]T. Assume the current weights are all zeros and learning
rate parameter is 0.5.
18. (15 points) Consider the following input patterns:
(-3, 9), (-2, 4), (-1, 1), (0, 0), (1, 1), (2, 4), (3, 9), (4, 16)
Suppose we want to design a Kohonen network that produces a 1-D topological map of
the input space. The discrete output space consists of 6 neurons indexed from 1 to 6. The
current weight matrix (from input to output) is
CS 537 / CMPE 537 (Sp 04/05) – Dr. Asim Karim
Page 6 of 8
0.6
0.4
0.2
W
0.8
0.4
1
1
0.2
0 .8
1
0 .8
0.2
a. (4 points) Determine the index of the winning neuron when input (-1, 1) is
presented to the network. Show your working.
b. (8 points) Compute the new weight matrix after presentation of the pattern in
(a) above. Take the learning rate parameter as 0.1.
c. (3 points) Draw the initial (before update) and final (after the network has
stabilized) topological maps formed by the Kohonen network. (Answer on the
back-side of the PREVIOUS page)
CS 537 / CMPE 537 (Sp 04/05) – Dr. Asim Karim
Page 7 of 8
19. (15 points) Design a MLP to learn the following function:
y = x2 where -3 <= x <= 4
a. (2 points) Choose an appropriate normalizing constant for the inputs and
outputs so that they lie in [+1, -1].
b. (5 points) Compute the output of the network when the input x = 2 is
presented to the network. Assume the network has 4 hidden layer neurons
each with the hyperbolic tangent activation function (constants = 1), and all
weights are equal to 1.
c. (8 points) Compute the new weights of the network after the presentation of
the input in (b) above. Take the learning rate parameter as 0.5. (Answer on the
bback-side of the PREVIOUS page)
CS 537 / CMPE 537 (Sp 04/05) – Dr. Asim Karim
Page 8 of 8