Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
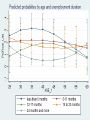
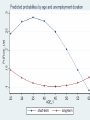
From user demand to indicator – the example of labour market flow statistics Hannah Kiiver - Eurostat Frank Espelage - Eurostat Outline Labour market transitions: data availability and data needs Agreeing on a method: Task Force on Labour Market Flow Statistics Further methodological challenges and proposed solutions Background information on data availability • The EU – Labour Force Survey is the main source for labour market analysis • Quarterly survey, output harmonization • ILO definition for employed, unemployed, inactive • Source for main policy indicators concerning labour market Availability of labour market transitions data • Retrospective question in the LFS: self-perceived labour market status one year ago • Not comparable to ILO definition, reliability, lack of additional information • Use other source: SILC • Timeliness, comparability to other labour market data Data needs Quarterly and annual transition data based on ILO definitions Consistency stocks – flows for ILO status Detailed breakdowns longitudinal micro-data Comparability over time/across countries Exploit overlap in LFS data – at least one quarter overlap for all rotational patterns used Task Force Labour Market Flow Statistics Quarterly flows first • Lower attrition, smaller changes in population Longitudinal sample: 15-74 in both quarters Iterative raking to meet margins for ILO status of both quarters Eurostat produces data starting in 2010 Labour market status flows in the EU* for 2015Q4-2016Q1, in millions *excluding DE and BE Transition rates 2015Q4-2016Q1 in the EU*, in % of initial status *excluding DE and BE Net changes in unemployment in the EU*, 1000 persons *excluding DE and BE Further requests: Breakdowns, additional transitions Annual flows Seasonal adjustment Methodological challenges Weighting – derive individual weights from raking procedure Sample size – for longitudinal sample, breakdown of indicators for small countries impossible Proposed solution • Pool longitudinal data for several quarters, create annual averages of quarterly flows • Simple probit regression • Function of age as regressor • Interaction terms where necessary • Bootstrap standard errors or use derived weights Communication • Do not publish complete regression output • Evaluate margins at the mean, or for different ages • Derive and publish predicted probabilities Example for Estonia, 2011 data • Transition from unemployment to employment • Total sample: 8016, of which 119 moving from unemployment to employment; • Breakdown by age and unemployment duration • Breakdown not publishable; sample less 10 in most groups • Regression using age, age squared as continuous variables, interaction terms with unemployment duration (5/2 categories) Conclusion The LFS is originally not designed for longitudinal analysis, and the availability of data (sample size and weights) and technical information collected reflects this. Using the available data, simple methods and some readiness to compromise of all stakeholders, production of detailed and meaningful data is nevertheless possible.