Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
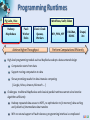
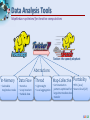
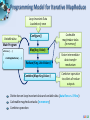
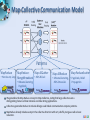
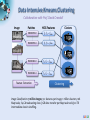
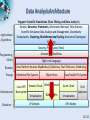
Analysis Tools for Data Enabled Science Judy Qiu [email protected] http://SALSAhpc.indiana.edu School of Informatics and Computing Indiana University Summer Workshop on Algorithms and Cyberinfrastructure for large scale optimization/AI, August 9, 2013 Big Data Challenge (Source: Helen Sun, Oracle Big Data) Learning from Big Data Converting raw data to knowledge discovery Exponential data growth Continuous analysis of streaming data A variety of algorithms and data structures Multi/Manycore and GPU architectures Thousands of cores in clusters and millions in data centers Cost and time trade-off Parallelism is a must to process data in a meaningful length of time SALSA Programming Runtimes Pig Latin, Hive Hadoop MapReduce Workflows, Swift, Falkon PaaS: Worker Roles Classic Cloud: Queues, Workers Achieve Higher Throughput MPI, PVM, HPF DAGMan, BOINC Chapel, X10 Perform Computations Efficiently High-level programming models such as MapReduce adopt a data-centered design Computation starts from data Support moving computation to data Shows promising results for data-intensive computing ( Google, Yahoo, Amazon, Microsoft …) Challenges: traditional MapReduce and classical parallel runtimes cannot solve iterative algorithms efficiently Hadoop: repeated data access to HDFS, no optimization to (in memory) data caching and (collective) intermediate data transfers MPI: no natural support of fault tolerance; programming interface is complicated SALSA Applications & Different Interconnection Patterns (a) Map Only (Pleasingly Parallel) Input map Output - CAP3 Gene Analysis - Smith-Waterman Distances - Document conversion (PDF -> HTML) - Brute force searches in cryptography - Parametric sweeps - PolarGrid MATLAB data analysis No Communication (b) Classic MapReduce (c) Iterative MapReduce (d) Loosely Synchronous Input iterations map Input map Pij reduce - High Energy Physics (HEP) Histograms - Distributed search - Distributed sorting - Information retrieval - Calculation of Pairwise Distances for sequences (BLAST) reduce - Expectation maximization algorithms - Linear Algebra - Data mining, includes K-means clustering - Deterministic Annealing Clustering - Multidimensional Scaling (MDS) - PageRank Collective Communication Domain of MapReduce and Iterative Extensions Many MPI scientific applications utilizing wide variety of communication constructs, including local interactions - Solving Differential Equations and particle dynamics with short range forces MPI SALSA Data Analysis Tools MapReduce optimized for iterative computations Twister: the speedy elephant Abstractions In-Memory Data Flow Thread • Cacheable map/reduce tasks • Iterative • Loop Invariant • Variable data • Lightweight • Local aggregation Map-Collective Portability • HPC (Java) • Communication patterns optimized for • Azure Cloud (C#) large intermediate data transfer SALSA Programming Model for Iterative MapReduce Loop Invariant Data Loaded only once Variable data Configure() Main Program while(..) { runMapReduce(..) } Cacheable map/reduce tasks (in memory) Map(Key, Value) Reduce (Key, List<Value>) Combine(Map<Key,Value>) Faster intermediate data transfer mechanism Combiner operation to collect all reduce outputs Distinction on loop invariant data and variable data (data flow vs. δ flow) Cacheable map/reduce tasks (in-memory) Combine operation SALSA Map-Collective Communication Model Patterns MapReduce MapReduceMap-AllGather • Wordcount, Grep MergeBroadcast • MDS-BCCalc • KMeansClustering, PageRank Map-AllReduce Map-ReduceScatter • KMeansClustering, • PageRank, Belief Propagation MDS-StressCalc We generalize the Map-Reduce concept to Map-Collective, noting that large collectives are a distinguishing feature of data intensive and data mining applications. Collectives generalize Reduce to include all large scale linked communication-compute patterns. MapReduce already includes a step in the collective direction with sort, shuffle, merge as well as basic reduction. SALSA Case Studies: Data Analysis Algorithms Support a suite of parallel data-analysis capabilities Clustering using image data Parallel Inverted Indexing used for HBase Matrix algebra as needed Matrix Multiplication Equation Solving Eigenvector/value Calculation SALSA Iterative Computations K-means Performance of K-Means Matrix Multiplication Parallel Overhead Matrix Multiplication SALSA PageRank Partial Adjacency Matrix Current Page ranks (Compressed) Iterations C M Partial Updates R Partially merged Updates Well-known page rank algorithm [1] Used ClueWeb09 [2] (1TB in size) from CMU Hadoop loads the web graph in every iteration Twister keeps the graph in memory Pregel approach seems natural to graph-based problems [1] Pagerank Algorithm, http://en.wikipedia.org/wiki/PageRank [2] ClueWeb09 Data Set, http://boston.lti.cs.cmu.edu/Data/clueweb09/ SALSA Data Intensive Kmeans Clustering Collaboration with Prof. David Crandall Image s 9900007 Patches 99000070-0 HOG Features 𝑓1 , 𝑓2 … 𝑓𝑑𝑖𝑚 99000070 0 9900007 6 99000076 9900043 99000432 2 Clusters I 99000070-4 𝑓1 , 𝑓2 … 𝑓𝑑𝑖𝑚 II 99000432-0 𝑓1 , 𝑓2 … 𝑓𝑑𝑖𝑚 III 99000432-4 Feature Extraction 𝑓1 , 𝑓2 … 𝑓𝑑𝑖𝑚 Clustering Image Classification: 7 million images; 512 features per image; 1 million clusters; 10K Map tasks; 64G broadcasting data (1GB data transfer per Map task node); 20 TB intermediate data in shuffling. SALSA High Dimensional Image Data K-means Clustering algorithm is used to cluster the images with similar features. Each image is characterized as a data point (vector) with dimensions in the range of 512 ~ 2048. Each value (feature) ranges from 0 to 255. A full execution of the image clustering application We successfully cluster 7.42 million vectors into 1 million cluster centers. 10000 map tasks are created on 125 nodes. Each node has 80 tasks, each task caches 742 vectors. For 1 million centroids, broadcasting data size is about 512 MB. Shuffling data is 20 TB, while the data size after local aggregation is about 250 GB. Since the total memory size on 125 nodes is 2 TB, we cannot even execute the program unless local aggregation is performed. SALSA Image Clustering Control Flow in Twister with new local aggregation feature in Map-Collective to drastically reduce intermediate data size Broadcast from Driver Worker 1 Worker 2 Worker 3 Map Map Map Local Aggregation Local Aggregation Local Aggregation Shuffle Reduce Reduce Reduce Combine to Driver We explore operations such as high performance broadcasting and shuffling, then add them to Twister iterative MapReduce framework. There are different algorithms for broadcasting. 14 Pipeline (works well for Cloud) minimum-spanning tree bidirectional exchange bucket algorithm SALSA Broadcast Comparison: Twister vs. MPI Performance comparison of Twister chain method and Open MPI MPI_Bcast Performance comparison of Twister chain method and MPJ broadcasting method (MPJ 2GB is prediction only) Chain method with/without topologyawareness The new topology-aware chain broadcasting algorithm gives 20% better performance than best C/C++ MPI methods (four times faster than Java MPJ) A factor of 5 improvement over non-optimized (for topology) pipeline-based method over 150 nodes. 15 SALSA Broadcast Comparison: Local Aggregation Comparison between shuffling with and without local aggregation Communication cost per iteration of the image clustering application Left figure shows the time cost on shuffling is only 10% of the original time Right figure presents the collective communication cost per iteration, which is 169 seconds (less than 3 minutes). 16 SALSA Triangle Inequality and Kmeans Dominant part of Kmeans algorithm is finding nearest center to each point O(#Points * #Clusters * Vector Dimension) Simple algorithms find min over centers c: d(x, c) = distance(point x, center c) But most of d(x, c) calculations are wasted, as they are much larger than minimum value Elkan [1] showed how to use triangle inequality to speed up relations like: d(x, c) >= d(x, c-last) – d(c, c-last) c-last position of center at last iteration So compare d(x,c-last) – d(c, c-last) with d(x, c-best) where c-best is nearest cluster at last iteration Complexity reduced by a factor = Vector Dimension, and so this is important in clustering high dimension spaces such as social imagery with 512 or more features per image [1] Charles Elkan, Using the triangle inequality to accelerate k-means, in TWENTIETH INTERNATIONAL CONFERENCE ON MACHINE LEARNING, Tom Fawcett and Nina Mishra, Editors. August 21-24, 2003. Washington DC. pages. 147-153. SALSA Fast Kmeans Algorithm d(x(P), m(now, c1)) ≥ d(x(P), m(last, c1)) – d(m(now, c1), m(last, c1)) (1) lower_bound = d(x(P), m(last, c)) – d(m(now, c), m(last, c)) ≥ d(x(P), m(last, c - current_best)) (2) Graph shows fraction of distances d(x, c) calculated in each iteration for a test data set 200K points, 124 centers, Vector Dimension 74 SALSA Results on Fast Kmeans Algorithm Histograms of distance distributions for 3200 clusters for 76800 points in a 2048 dimensional space. The distances of points to their nearest center is shown as triangles; the distance to other centers (further away) as crosses; the distances between centers are the filled circles SALSA Data Analysis Architecture Applications/ Algorithms Support Scientific Simulations (Data Mining and Data Analysis) Kernels, Genomics, Proteomics, Information Retrieval, Polar Science, Scientific Simulation Data Analysis and Management, Dissimilarity Computation, Clustering, Multidimensional Scaling, Generative Topological Mapping Security, Provenance, Portal Services and Workflow Programming Model Runtime Storage Infrastructure Hardware High Level Language Cross Platform Iterative MapReduce (Collectives, Fault Tolerance, Scheduling) Distributed File Systems Object Store Windows Server Linux HPC Amazon Cloud HPC Bare-system Bare-system Virtualization CPU Nodes Data Parallel File System Azure Cloud Virtualization Grid Appliance GPU Nodes SALSA