Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
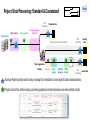
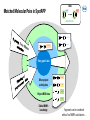
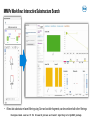
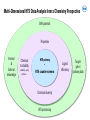
Automated Workflows for Integrated Project Data Analysis Using Spotfire: the SpotAPP Family Nicolas Zorn, CADD Group, Roche Innovation Center Basel Basel Tibco Spotfire UGM, Nov 3rd 2016 Preamble Data optimization cycle Drug discovery cycle Design Retrieval Analysis Presentation Synthesis Testing Processing Enrichment Key features for success: relevance, efficiency, agility – integration & interactivity Building-up Capabilities to Help Answer Key Projects Questions System for Agile Development Action Flexibility • Knowledge Information Modularity • Decision-making! • Project-centric data mining and analysis • SAR, SPR exploration A Data • Predicted properties Automation • • Virtual Compounds Infrastructure Presentation Outline • Overview and concepts of the SpotAPP workflow • Features highlights – Activity-efficacy data analysis – MMPs and project SAR analyses – ivive and PK/PD • Workflow expansion to HTS data analysis: SpotHTS • Conclusions, Perspectives SpotAPP: Integrated Project Data Mining and Analysis Spotfire Automated Project Data Processing Roche internal databases External data (Chembl, patent data…) in house Off-target, HTS and LTS data PK/PD and ivive Custom calculations (selectivity, LE, ...) In house molecular property predictions Matched Molecular Pairs and SAR analyses Cluster analysis and series tagging Structural data Implementation Overview • Project data flow processing Data sources Tables are linked and auto-embedded Project data tables (linux FS and WIN shares) Spotfire library project template Spotfire server automation service: reloads and embeds data tables after each update. • Overall process control: CRON table drives SpotAPP project runs (frequency and options) Full flexibility Options passed as one-letter codes for CRON jobs Daily update All projects run in ~3h every night Project Data Structure during Processing Non-pivoted, non-aggregated 1 row per result Batch aggregation Substance aggregation 1 row per result & per batch 1 row per result & per subst. Unpivoted data table Project custom aggregation then pivoting 1 row per substance Pivoted data table Partially aggregated or raw data tables • Standard aggregation rules apply, then possibility to override/refine with project-custom rules • Optionally, unpivoted data can be exposed at several aggregation levels Project Data Processing: Standard & Customized Final formatting Retrieve data Input cleanup Std aggregation Unpivoted data Process structures, properties Final formatting Retrieve and process off-tgt data ancillary data Project aggregation, Pivoting Clustering Series Tagging Predicted properties PKPD module … Final pivoted data formatting • Auxiliary Pipeline pilot protocol: easy to setup from template to insert specific data manipulations • Project control file: defines input, processing options and team decisions on desired data format Advanced Series Tagging • Project-specific substructure definitions (Molfile) Complex search hierarchy, multiple fields possible • Used to label series, substructures, motifs… • Can be combined with on-the-fly SS searches. SpotAPP Highlight: Activity and Efficacy Data Analysis Roche internal databases External data (Chembl, patent data…) in house Off-target, HTS and LTS data PK/PD and ivive Custom calculations (selectivity, LE, ...) In house molecular property predictions Matched Molecular Pairs and SAR analyses Cluster analysis and series tagging Structural data On-target Activity Data Browsing and Compound Profiling • Latest processed data is always exposed in project SpotAPP package • Browse data across all available dimensions (activities, properties…) Marked compounds put in ‘shopping cart’ for side-by-side comparison and profiling Pivoted data used for overview and data correlations. IronPython script captures marked compounds as tag. Activity–Efficacy Data Analysis and Drilldown • Efficacy data analyzed using complex set of conditions: target subtype, species, doses, measurement mode… Interplay of Spotfire pivoted and unpivoted tables: instantaneous data drill-down. SpotAPP Highlight: SAR Analysis of a Complex Data Set Roche internal databases External data (Chembl, patent data…) in house Off-target, HTS and LTS data PK/PD and ivive Custom calculations (selectivity, LE, ...) In house molecular property predictions Matched Molecular Pairs and SAR analyses Cluster analysis and series tagging Structural data SAR Analyses: Integration of Standard Methods into Project Context • SpotAPP exposes and connects in-house Python-based SAR tools: MMPs, Non-add FreeWilson Project SAR – R-group decomposition – Matched pairs/series – Non-additivity analysis R-groups • Advanced SAR analyses are pre-processed using activities/properties selected by the team and can make use of the SpotAPP series tags. • Analysis results from SAR tools can then be connected to any other project data. • Customization is possible by applying the same concepts as presented for regular project data. R-group Decomposition Analysis 1. Select core, R-groups and activity 2. Select compounds in R-group matrix 3. See SAR and trends for 1+ activity(ies) Connect to MMPs data • Setup for single/multiple activity R-group matrix visualization and analysis • Uses series tags when R attachments are defined à browse R-group cores using project definitions MMPs Matched Molecular Pairs in SpotAPP N H 2 O H common core X Y ΔPgp X X Y Y ΔHepCl ΔIC50 ‘Entry point’ data Other project activity data C H X Y X Y F F 3 Project MDO data F C H F 3 F F Global MMPs knowledge ΔIC50 ΔKi ΔIC50 ΔKi Approach can be combined with ad hoc MMPs calculations… MMPs Workflow: Filter-down to Desired Pairs / Series 1. Filter-to/mark set of MMPs to answer question 3. Analyze D(activity/properties) for selected pairs Current marked compounds (R-groups…) and/or Aggregated MMPs trends (e.g. Avg, Geo… ) 2. Browse/select individual pairs and/or Line plot: identify outliers MMPs workhorse: Python platform designed for processing of large data & interactive queries MMPs Workflow: Interactive Substructure Search • Allows fast substructure-based filtering using Core and variable fragments; can be combined with other filterings Discngine Panel used as UI for SS search process and result reporting into SpotAPP package SpotAPP Highlight: Prototype ivive Calculations Roche internal databases External data (Chembl, patent data…) in house Off-target, HTS and LTS data PK/PD and ivive Custom calculations (selectivity, LE, ...) In house molecular property predictions Matched Molecular Pairs and SAR analyses Cluster analysis and series tagging Structural data Concepts for SpotAPP ‘PK/PD’ Module Prototype Goals: • Provide facilitated and standardized calculations of derived PK properties to team PK reps. Enable consistent decision making & expose key visualizations to teams. Key principles: • Automation of calculations using a central, validated, R script • Implementation of different clearance scaling calculation methods è Comparison and selection of most appropriate method to share and use • Customization of script behavior per project using control file and ad hoc data files (if needed) Internal DB’s Main SpotAPP package Main data table Process controlled by PK rep. PK/PD processing Custom input / parameters Complete PK tables Advanced PK and PK/PD data package; & features Example of Advanced PK Calculations Available to PK Rep. for Decision-making • Example of different methods providing clearance scaling from hepatocytes Dilution method Estimate unspecific binding (Houston) in vivo CLb_unbound_int_hep Assume no binding CLint in [mL/min/kg] in vitro CLint_hep Estimation of protein binding in hepatocyte incubation medium: fu from preclinical species • PK concentration-time curves from individual animals and aggregated over treatment groups SpotAPP Workflow Adaptation To HTS Analysis Re-use of Standard Processing Modules Flexibility • Action Knowledge Information Modularity • HTS data package • HTS screen results, general compound info • Early HIT SAR exploration Data • Off-target, ancillary profile Automation • • Hit-expansion Infrastructure Multi-Dimensional HTS Data Analysis from a Chemistry Perspective SAR potential Properties Internal & External knowledge Chemical tractability availability, purity, synthesis… HTS potency • HTS counter-screens Chemical diversity HTS promiscuity Ligand efficiency Target / gene / pathway data SpotHTS Workflow Overview Primary screen data (single points) Roche DB Clusterings Tags, labels MDO, props HTS confirmation data (dose-responses) DR curves CEREP panel Off-tgt. data HTS results HTS hit history Tox/Safety data Advanced data mining (Phenotypic/assay profiling…) MDO, purity Ligand eff. HTS Package Kinase panel PAINs SEA analysis External data Ontology analysis External data HTS Data Package: Highlights HTS history and known in-house activities Dashboard for multi-parametric hit analysis • Platform for narrowing high Primary hit-rate, analyze hits • Used for internal prioritization & sharing with external partners Chemical space clustering and diversity analysis Knowledge Capture: Hits Annotation within SpotHTS Package • Team members can annotate and label compounds inside SpotHTS package. 1. Select hit(s) in analyses and provide annotation 2. Retrieve and analyze compounds based on annotations Annotations captured in Oracle DB via information link, then embedded in HTS package as data table. Integrated Hit Expansion within SpotHTS Package • Retrieval of top-100 similar compounds for all hits with dose-response data. Done as part of data processing (2D-based similarity). à Use as initial info to assess hit SAR potential and screening follow-up activities 1. Select hit(s) in analyses 2. See all IRCI closest neighbors 3. Find overlap and compounds not screened yet Visualize data and stock availability, purity... IronPython scripts in Spotfire to perform automatic list logic and markings. Conclusions • SpotAPP ecosystem has organically grown last couple of years at Roche as DEV platform Ø For project teams: provides integrated project data, advanced SAR and PK analyses… Ø For experts-developers: helps test new features, data models & custom visualizations. • Core design features for efficient data delivery: Flexible, automated, customizable to project critical needs • SpotAPP standard components and logic shared by other Spot* family members (potentially also by Roche New Assay Data Analysis Landscape tools) Ø SpotHTS variant for HTS analysis: on the way to integrated hit delivery HTS PK MDO * Perspectives Retrieval • Spotfire is efficient and versatile as vector of new data models – especially for fast/complex data optimization cycles – excellent for relational data tables and large data volumes Presentation Processing – iPython, R, information links and data connections are powerful – enhanced features possible via add-ons (Discngine, JS D3,…) Enrichment • Challenges still remain for drug discovery community – UI and data presentation simplification for non-experts – Increased chemical intelligence & cheminformatics-guided workflows Acknowledgements • Brian Jones Yi Lin Lisa Sach-Peltason Christian Blumenroehr Daniel Wenger Olivier Roche Martin Blapp Gunther Doernen Peter Hilty (pREDi) Paula Petrone • Jerome Hert Christian Kramer • Stefanie Bendels Michael Reutlinger Wolfgang Guba (CADD) Martin Kapps + many other contributors (PS) • Katrin Groebke-Zbinden • Eric Leroux (Discngine) John Cumming + many medicinal chemists for feedback-suggestions Doing now what patients need next