Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
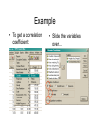
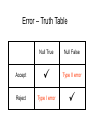
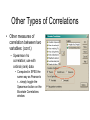
Correlation Association between 2 variables Suppose we wished to graph the relationship between foot length and height of 20 subjects. In order to create the graph, which is called a scatterplot or scattergram, we need the foot length and height for each of our subjects. 74 72 Height 70 68 66 64 62 60 58 4 6 8 10 Foot Length 12 14 1. Find 12 inches on the x-axis. 2. Find 70 inches on the y-axis. 3. Locate the intersection of 12 and 70. 4. Place a dot at the intersection of 12 and 70. Assume our first subject had a 12 inch foot and was 70 inches tall. 74 72 Height 70 68 66 64 62 60 58 4 6 8 10 Foot Length 12 14 5. Find 8 inches on the x-axis. 6. Find 62 inches on the y-axis. 7. Locate the intersection of 8 and 62. 8. Place a dot at the intersection of 8 and 62. 9. Continue to plot points for each pair of scores. Assume that our second subject had an 8 inch foot and was 62 inches tall. 74 72 70 68 66 64 62 60 58 4 6 8 10 12 14 Notice how the scores cluster to form a pattern. The more closely they cluster to a line that is drawn through them, the stronger the linear relationship between the two variables is (in this case foot length and height). 74 72 70 68 66 64 62 60 58 4 6 8 10 12 14 If the points on the scatterplot have an upward movement from left to right, we say the relationship between the variables is positive. 74 72 70 68 66 64 62 60 58 4 74 72 70 68 66 64 62 60 58 4 6 8 10 12 14 6 8 10 12 If the points on the scatterplot have a downward movement from left to right, we say the relationship between the variables is negative. 14 A positive relationship means that high scores on one variable are associated with high scores on the other variable It also indicates that low scores on one variable are associated with low scores on the other variable. 74 72 70 68 66 64 62 60 58 4 6 8 10 12 14 A negative relationship means that high scores on one variable are associated with low scores on the other variable. It also indicates that low scores on one variable are associated with high scores on the other variable. 74 72 70 68 66 64 62 60 58 4 6 8 10 12 14 Not only do relationships have direction (positive and negative), they also have strength (from 0.00 to 1.00 and from 0.00 to –1.00). The more closely the points cluster toward a straight line, the stronger the relationship is. A set of scores with r= –0.60 has the same strength as a set of scores with r= 0.60 because both sets cluster similarly. For this procedure, we use Pearson’s r (also known as a Pearson Product Moment Correlation Coefficient). This statistical procedure can only be used when BOTH variables are measured on a continuous scale and you wish to measure a linear relationship. NO Pearson r Linear Relationship Curvilinear Relationship Formula for correlations ( x x )( y y ) / n r SxS y or Covxy SDx SDy 1 xi x yi y r n s x s y Assumptions of the PMCC 1. The measures are approximately normally distributed 2. The variance of the two measures is similar (homoscedasticity) -- check with scatterplot 3. The relationship is linear -- check with scatterplot 4. The sample represents the population 5. The variables are measured on a interval or ratio scale Example • We’ll use data from the class questionnaire in 2005 to see if a relationship exists between the number of times per week respondents eat fast food and their weight • What’s your guess (hypothesis) about how the results of this test will turn out? .5? .8? ??? Example • To get a correlation coefficient: • Slide the variables over... Example • SPSS output The red is our correlation coefficient. The blue is our level of significance resulting from the test…what does that mean? Digression - Hypotheses • Many research designs involve statistical tests – involve accepting or rejecting a hypothesis • Null (statistical) hypotheses assume no relationship between two or more variables. • Statistics are used to test null hypotheses – E.g. We assume that there is no relationship between weight and fast food consumption until we find statistical evidence that there is Probability • Probability is the odds that a certain event will occur • In research, we deal with the odds that patterns in data have emerged by chance vs. they are representative of a real relationship • Alpha (a) is the probability level (or significance level) set, in advance, by the researcher as the odds that something occurs by chance Probability • Alpha levels (cont.) – E.g. a = .05 means that there will be a 5% chance that significant findings are due to chance rather than a relationship in the data – The lower the a the better, but…a level must be set in advance Probability • Most statistical tests produce a p-value that is then compared to the a-level to accept or reject the null hypothesis • E.g. Researcher sets significance level at .05 a priori; test results show p = .02. • Researcher can then reject the null hypothesis and conclude the result was not due to chance but to there being a real relationship in the data • How about p = .051, when a-level = .05? Error • Significance levels (e.g. a = .05) are set in order to avoid error – Type I error = rejection of the null hypothesis when it was actually true • Conclusion = relationship; there wasn’t one (false positive) (= a) – Type II error = acceptance of the null hypothesis when it was actually false • Conclusion = no relationship; there was one Error – Truth Table Null True Null False Accept Type II error Reject Type I error Back to Our Example • Conclusion: No relationship exists between weight and fast food consumption with this group of respondents Really? • Conclusion: No relationship exists between weight and fast food consumption with this group of subjects – Do you believe this? Can you critique it? Construct validity? External validity? – Thinking in this fashion will help you adopt a critical stance when reading research Another Example • Now let’s see if a relationship exists between weight and the number of piercings a person has – What’s your guess (hypothesis) about how the results of this test will turn out? – It’s fine to guess, but remember that our null hypothesis is that no relationship exists, until the data shows otherwise Another Example (continued) • What can we conclude from this test? • Does this mean that weight causes piercings, or vice versa, or what? Correlations and causality • • • Correlations only describe the relationship, they do not prove cause and effect Correlation is a necessary, but not sufficient condition for determining causality There are Three Requirements to Infer a Causal Relationship Correlations and causality A statistically significant relationship between the variables The causal variable occurred prior to the other variable There are no other factors that could account for the cause Correlation studies do not meet the last requirement and may not meet the second requirement (go back to internal validity – 497) Correlations and causality If there is a relationship between weight and # piercings it could be because weight # piercings weight # piercings weight some other factor # piercings Which do you think is most likely here? Other Types of Correlations • Other measures of correlation between two variables: – Point-biserial correlation=use when you have a dichotomous variable • The formula for computing a PBC is actually just a mathematical simplification of the formula used to compute Pearson’s r, so to compute a PBC in SPSS, just compute r and the result is the same Other Types of Correlations • Other measures of correlation between two variables: (cont.) – Spearman rho correlation; use with ordinal (rank) data • Computed in SPSS the same way as Pearson’s r…simply toggle the Spearman button on the Bivariate Correlations window Coefficient of Determination Correlation Coefficient Squared Percentage of the variability among scores on one variable that can be attributed to differences in the scores on the other variable The coefficient of determination is useful because it gives the proportion of the variance of one variable that is predictable from the other variable Next week we will discuss regression, which builds upon correlation and utilizes this coefficient of determination Correlation in excel Use the function “correl” The “arguments” (components) of the function are the two arrays Applets (see applets page) • http://www.stat.uiuc.edu/courses/stat100/java/GCApplet/GCAppletFrame.html • http://www.stat.sc.edu/~west/applets/clicktest.html • http://www.stat.sc.edu/~west/applets/rplot.html